Introducing SAM: An easy-to-use algorithm derived by connecting PAC Bayesian bounds and geometry of the loss landscape. Achieves SOTA on benchmark image tasks (0.3% error on CIFAR10, 3.9% on CIFAR100) and drastically improves label noise robustness.
https://t.co/aONWVTPZsT
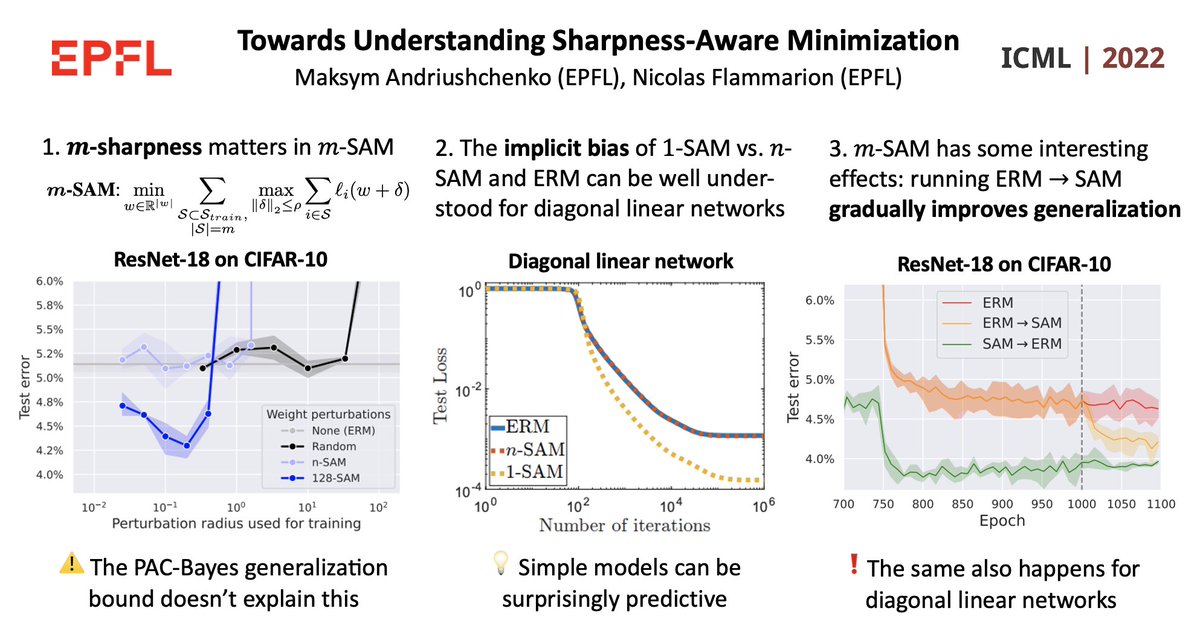
Excited to share our #ICML2022 paper "Towards Understanding Sharpness-Aware Minimization"!
Why does m-sharpness matter in m-SAM? Can we explain the benefits of m-SAM on simple models? Which other interesting properties does m-SAM show?
Paper: https://t.co/F63P1KkdCw
🧵1/n
Excited to host @TheGradient to talk about the current state of Sharpness-Aware Minimization (SAM) and future directions next Friday 25th Feb 5pm (GMT time) Zoom details: https://t.co/7j5lND15Yr
Are you a strong PhD student interested in doing cutting edge research at @GoogleAI? I have an opening for student researcher position to explore open problems and extensions of Sharpness-Aware Minimization (SAM) w/ @bneyshabur. Please refer to https://t.co/oHdwahJ8uH.
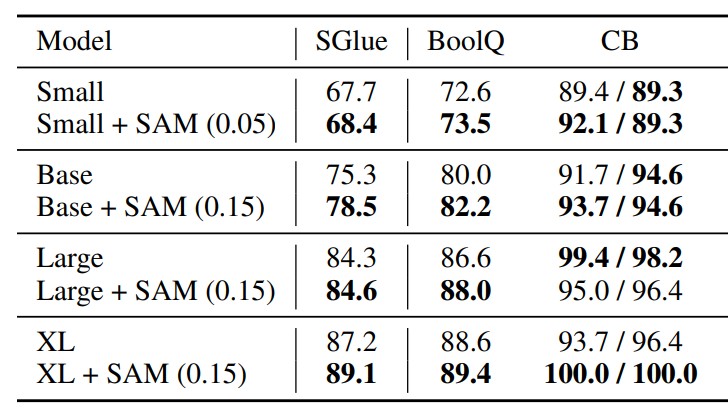
Sharpness-Aware Minimization Improves Language Model Generalization
SAM substantially improves performance on SuperGLUE, GLUE, Web Questions, Natural Questions, Trivia QA, and TyDiQA by encourageing convergence to flatter minima w/ minimal overhead.
https://t.co/iQuFEq2Ne3
@thanhnguyentang@matthen2 If each particle is independent, each particle probably only need to keep the random seed used to generate the path increments
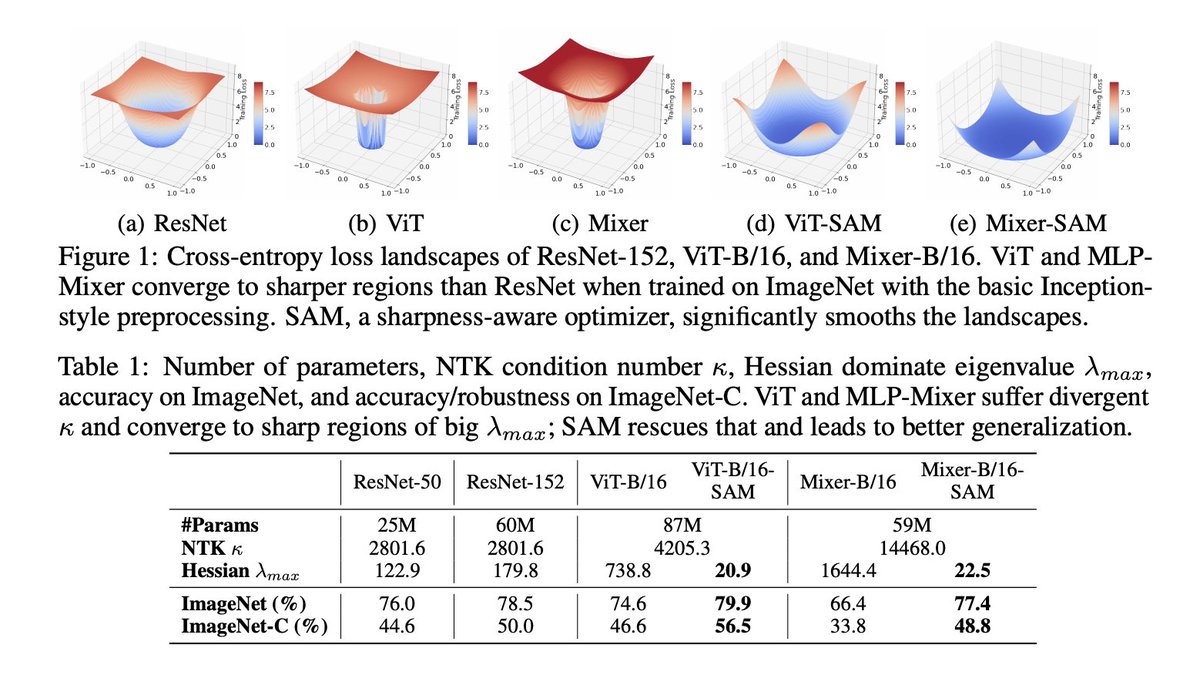
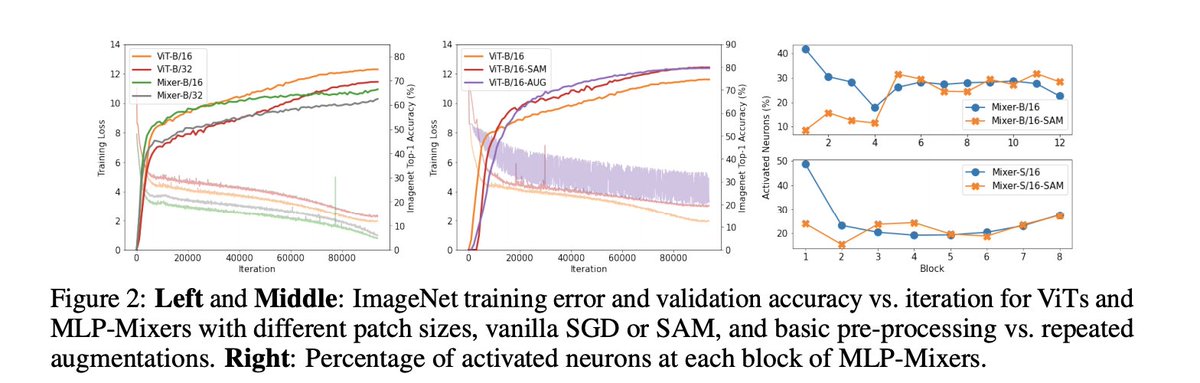
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
pdf: https://t.co/GYknaVoNAM
abs: https://t.co/kaUxIdMVNQ
+5.3% and +11.0% top-1 accuracy on ImageNet for ViT-B/16 and MixerB/16, with the simple Inception-style preprocessing
Interesting empirical study of the geometry of the loss landscape of Vision Transformers and MLP-Mixers and study of the critical impact of Sharpness Aware Minimization (SAM) for those architectures.
Excited to see Sharpness-Aware Minimization (SAM optimizer) we have proposed recently (w/ @Foret_p@bneyshabur and Kleiner) is becoming a persistent component in recent state-of-the-art records 😇
Sharpness-Aware Minimization for Efficiently Improving Generalization (Spotlight at #ICLR2021 )
with @Foret_p, Ariel Kleiber and @TheGradient
Paper: https://t.co/WyIwSttkJp
Code: https://t.co/9SBwZ1BtiU
Video and Poster: https://t.co/PoIAazaIdN
3/7
We don’t need to worry about #Overfitting anymore? Sharpness-Aware Minimization, seeks parameters that lie in neighborhoods having uniformly low loss; results in a min-max optimization formulation with efficient gradient descent #MachineLearning https://t.co/a4SVXhEumo
@RisingSayak Great stuff! Is this syncing epsilon across replicas ? On a TPU (8 chips for this one I think?) I would expect the benefits of SAM to be amplified by not syncing epsilon accross the devices (one perturbation per sub-batch). Could be a cool improvement if it's not already the case
@imos You can of course emulate this on a single device with data accumulation, but it becomes tedious and the wall clock time might suffer (although NFNet using a subset of the batch to compute the SAM epsilon is a great trick)
@imos so SAM on TPU minimize m-sharpness for a small m, which leads to the biggest boosts. That's why I assume we will mostly see SAM applied to larger nets that require TPU or multiple GPU, where it really shines. 3/3
@imos SAM usually works well for smaller models, but the best results are obtained when using a lot of data parallelism (see section about M-sharpness in the SAM paper). Because the largest nets are trained on a lot of tpu chips, each chip computes epsilon for few samples... 2/3
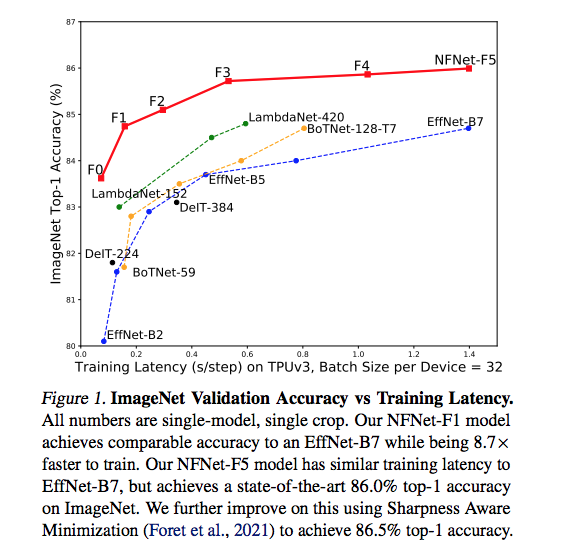
Pretrained NFNet model weights (F0-F5, F6+SAM) are now available at https://t.co/uNSzeA4uJt, along with a demo Colab! All models are pretrained on ImageNet.