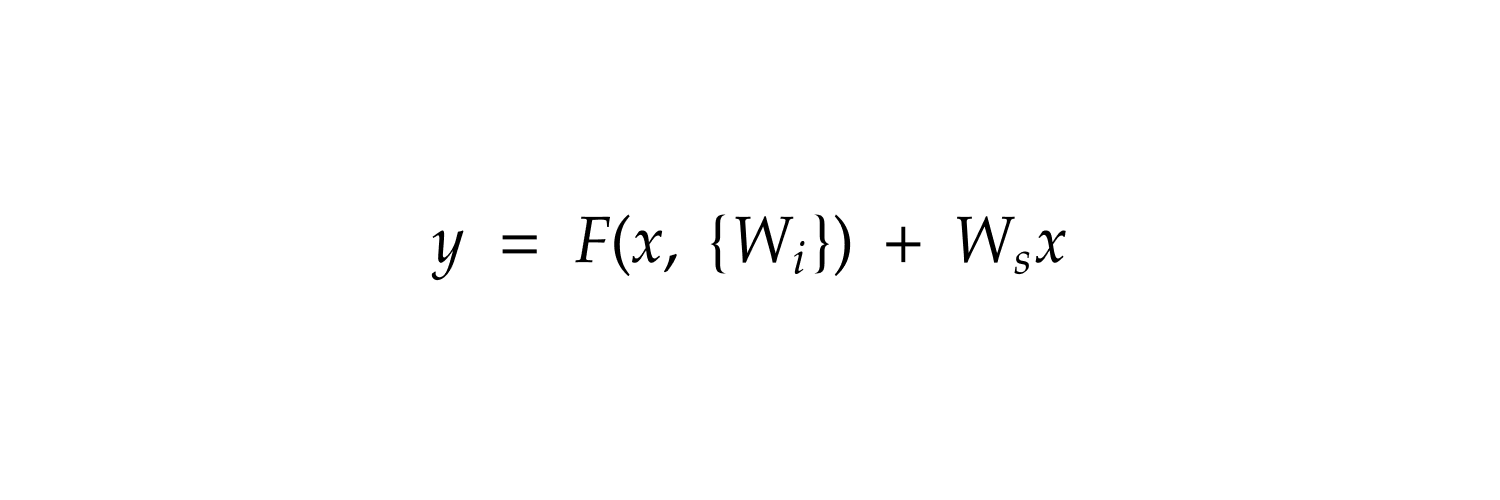Had the honor to present diffusion transformers at CS25, Stanford. The place is truly magical.
Slides: https://t.co/Npm3NCmbtm
Recording: https://t.co/8Q9Mcrjxlq
Thanks to @stevenyfeng for making it happen!
Want to know if a kernel is compatible with your system configuration?
We shipped `get_kernel_variants()` to make it easier!
Query every kernel available on the Hub and know if it'd run on your machine 🫡
Having tons of fun with the DGX Spark running img and vid generation models locally (finally!)
Thanks to @NVIDIAAI for the gift 🫡 It's quite the beast!
I am sold on the fact that there's no better build system than Nix when it comes to absolute reproducibility, system definition, and interoperability.
There's no match.
Having tons of fun with the DGX Spark running img and vid generation models locally (finally!)
Thanks to @NVIDIAAI for the gift 🫡 It's quite the beast!
@liangsu325045@ned714@NVIDIAAI I am happy to create a shared Slack channel with you on the HF workspace and bring in other members of our team there. Is the email on your GitHub the right one for this?
@badlogicgames When that's happened to me, I've spent a couple of hours trying to build enough familiarity to instead file a slop-ish issue, including a "PoC fix".
My possibly-old-fart view is that a PR should generally be code you're willing to stand behind, or at least spend time polishing.
@zhyncs42@lightseekorg@LeiLMx Agreed. This is why we are developing the kernels project at @huggingface.
This is our recent GPU Mode:
https://t.co/MRH4AQI4IP
Would there be any interest in a collaboration?
@liangsu325045@ned714@NVIDIAAI Yeah same experience for NVFP4 here:
https://t.co/QmtN8enO8g
You have to be selective.
Very cool work with the kernels, would you be interested in building and packaging them with
https://t.co/5jhJ1OQ6M5 ?
@liangsu325045@ned714@NVIDIAAI And when you are turning the entire pipeline into kernel, there are still some component boundaries, no, for the separate components (text encoder, denoiser, VAE, sampler). Maybe I misunderstood.
@liangsu325045@ned714@NVIDIAAI Haven’t looked into fully optimizing yet. General impression is that the workloads I have tried so far are not utilizing the SMs much so the latency is often that shiny.
I will first try out the usual. FA4, NVFP4, etc.
Do share your recipes!