Cross-architecture from a single codebase is exactly why we built SCALE. Thrilled to see @AtlasInference getting this running! More performance optimizations for both @AMD and @nvidia are on the way.
https://t.co/hQpeCzwg2B
Atlas Inference is running Qwen3.6-27B on AMD Strix Halo 🥳
Using @SpectralCom's SCALE ROCm backend, our CUDA kernels compile and run on RDNA⚙️
Cross-architecture inference from ONE codebase 🗣️
Thank you @AIatAMD for the gift 🙏
POC ✅ excited to keep tuning performance⚡️
@SpectralCom@AIatAMD We picked @Alibaba_Qwen's series to test because it is the de-facto standard for local LLMs!
Join our discord for access to early releases, feature requests, and any for help you may need serving 🫂
https://t.co/3TMQqvLfT8
Github linked below🔗
https://t.co/2ofLwCmhlY
@RisingSayak@NVIDIAAI Makes sense. We technically support vision for the Qwen3.6-suite but maybe not exactly what you're looking for just yet. Happy to build for any fitting use cases though!
@seree Thanks for taking the time to run through these! I think the default mem allocation may be higher than needed for a smaller dense model like this. Plz dm or post the details in #bugs regarding any of these other pieces, should be customizable/avoidable :) appreciate the feedback
@Alibaba_Qwen Excited to try Qwen3.7-Max (plz OSS release soon🙏) Look at how deeply embedded we are optimizing @Alibaba_Qwen:
3.5/3.6-35B, 3.5/3.6-27B, 3.5-122B (EP=2), 3-Next-80B (GDN/Mamba-2), 3-VL, 3-Coder. Achieved 130 tok/s on 3.5-35B. The Qwen series is genuinely WHY we built Atlas!
It’s official: @AtlasInference is now a @Alibaba_Qwen ambassador! 🤝
Our mission started with Qwen. It remains our top priority and most optimized series. Qwen revolutionized open-source AI, and we’re excited to keep pushing its limits ⚡️
Thank you to our amazing community❤️🔥
@torfi_F_Olafss@huggingface Yes we optimize per {model}_{quant} pair! So to answer your question @torfi_F_Olafss this should definitely help the NVFP4 kernel landscape.
Also just as a random sidenote I have many more hours on Minecraft than Atlas inference so take that as you will lol
DGX Spark lovers 🚨
Thank you @huggingface for merging SM_121 support into kernel-builder, every dev can now pull optimized kernels via get_kernel() 🚀
@AtlasInference pushed to make sure the DGX Spark community had representation 💾
Let's keep squeezing these GB10 chips 📈
@huggingface See https://t.co/J4ttVAcW26 for more details.
Special thanks to @RisingSayak and the broader hf team for working quickly to resolve this, and being open to collaboration from the incredible open source community 💯
@TheAhmadOsman@pupposandro That's right, that's why im working on TQ+ cache compression techniques for @AtlasInference right now in my copious amounts of spare time... now back to hand tuning metal kernels:
https://t.co/MY1JxuGoxY
@jun_song When Gemini translates it probably destroys your original structure and flow. And it brings more of an AI flavor to it. Happens to me when I go from Urdu all the time. Either way, you can't really control it. Bi-directional encoders do have their limits lol
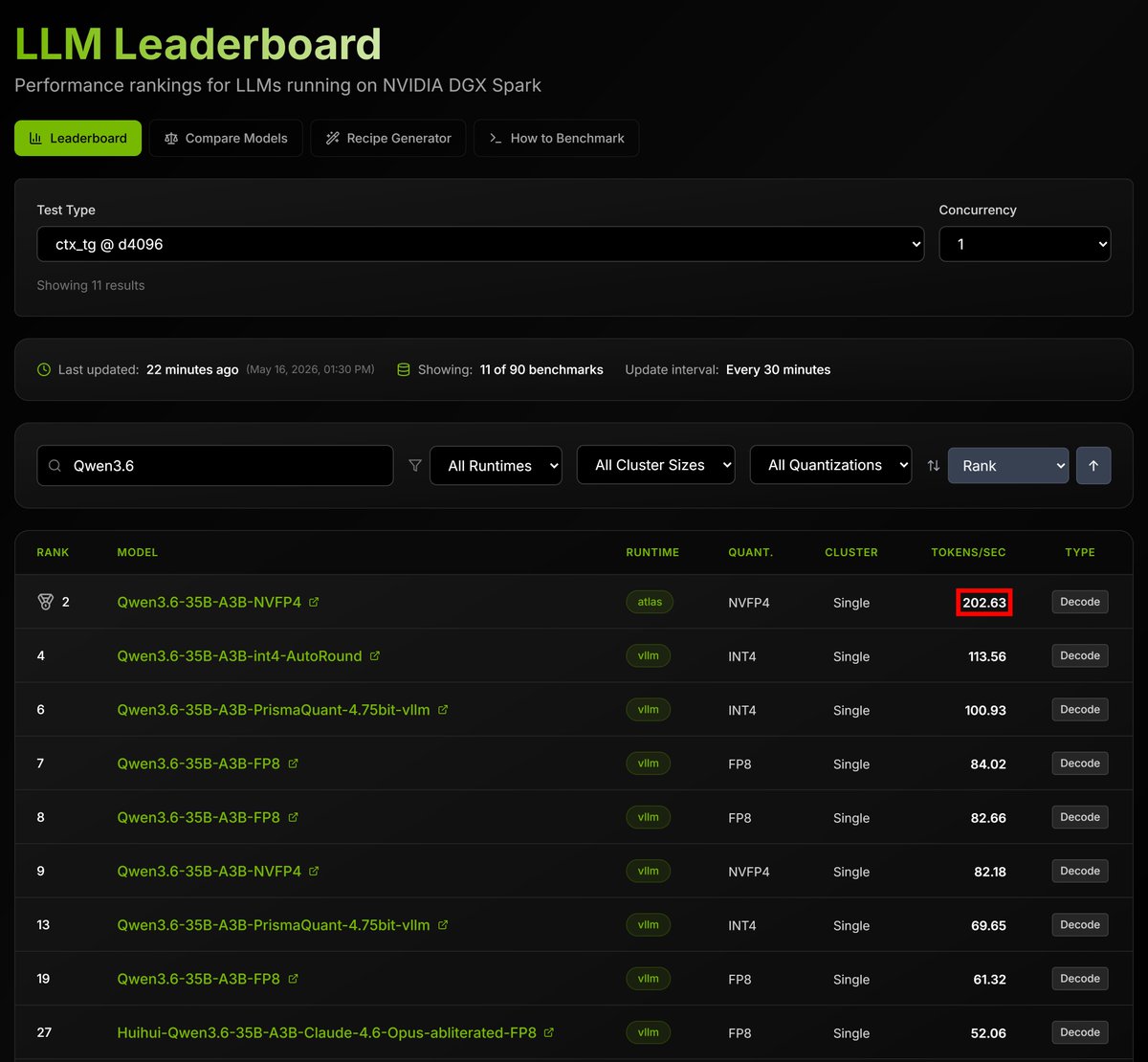
DGX Spark just benched 200+ tok/s for Qwen3.6-35B with @AtlasInference on @spark_arena 🔥
How's that possible? Providers like Codex and Claude get ~60. Other major engines don't come close 🦥
We haven't seen speeds like this on GB10. NO ONE HAS. Atlas is shattering records 🚀