A SaaS-preneur chasing dollars by day, sneaking out of my cave occasionally to teach, and secretly indulging in my gacha addiction (shhh, don't tell my wife!)
First time benchmarking rust-based inference engine by atlas (@AtlasInference)
Model tested:
Qwen3.6 27B FP8 with MTP enabled
Things noted:
- startup speed, OMG, it's much much faster than other inference engines I've tried!
- token generation speed is great but I think it can be faster, let me play with it more and will keep this posted
- memory consumed more than vllm, probably the default KV cache is 16bit?
- crashed with long context input, yes, it crashed my DGX Spark and force shutdown without a reboot 😭
Anyway, i think the future is quite interesting for this inference engine, will playing more with it!
@AtlasInference I'm adjusting various parameters to experiment it more, will DM what I found very soon.
Next station will be 35B A3B NVFP4 with the recent Qwen/Qwen3.6-35B-A3B-NVFP4 model instead od RedHatAI's one.
BTW: thanks for your hard work!
It's NOT about not having enough compute.
It's about what we're WASTING on the harnesses!
We desperately need smarter harness optimization, not just throwing more power at the problem!
#AITalks
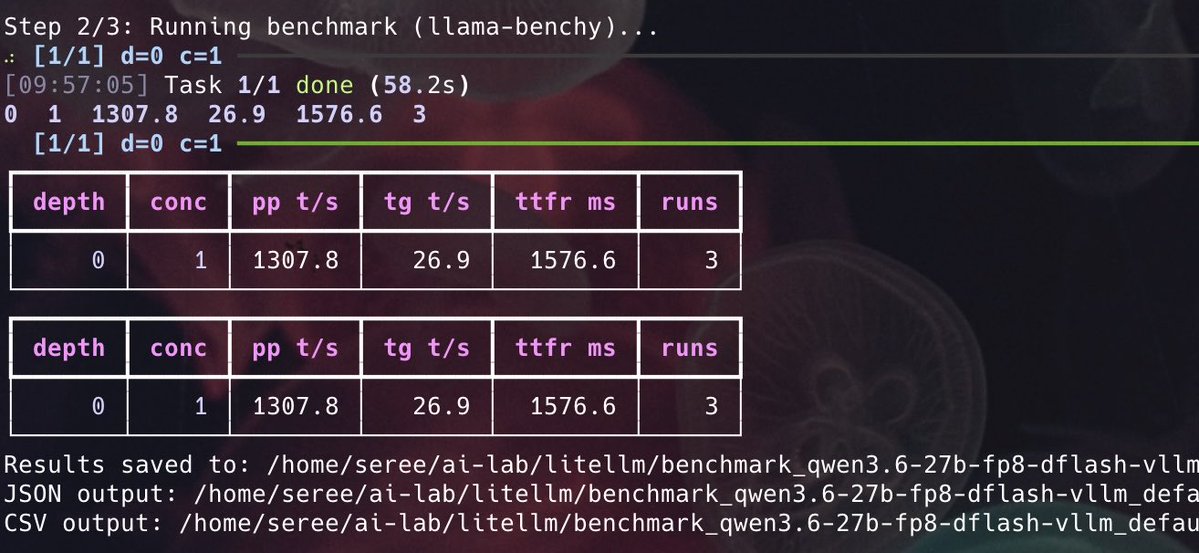
Benchmarking the famous Qwen3.6 27B FP8 DFlash on my DGX Spark.
Speed boosted from 16.2 tps (MTP) to 26.9 tps (DFlash). 🔥🔥
Now testing with OpenCode to see if it will broke at tools calling or not.
Will try AEON’s NVFP4 DFlash version very soooooon!