AI business systems research, implementation and consulting. Former network support engineer and technical SASE security product specialist at Cisco Meraki.
We've been using CodeRabbit for the last 9 months as part of our PR review process in Github, and so far, I'm a happy customer. I've personally learned a lot from CR's feedback, as well as its strengths and weaknesses. BLUF: CR does provide a lot value, but only when you're able to separate the legitimate issues from bad suggested fixes.
As with anything produced by AI, validation is extremely important. CodeRabbit is not infallible and will produce false positives. To address this, our implementation orchestration agents monitor new PRs and run a /rabbit skill that processes all CR reported issues through a multi-phase multi-agent validation and adversarial review workflow.
Here's what we've learned from our freshest batch of 58 CodeRabbit scorecards we've produced over the last few weeks:
1. The 58 scorecards contained 227 findings (issues and nitpicks reported by CR.) ~71% of the findings were judged to be valid and received fixes.
2. If we break things down further between CR issues and nitpicks, we've seen a false positive rate of 26.8% for issues, and 51.6% for nitpicks. Even though nitpicks had a noisier FP rate, they did help expose real weaknesses in our code, stale-comments, artifacts, and repo-convention problems.
3. Some of the highest value CR findings were solid boundary/contract issues:
* auth/tenant/RBAC gaps
* API/OpenAPI drift
* DB/RLS invariants
* race/idempotency bugs
* test/mock parity failures
4. False positive patterns observed:
* "Issue" already handled elsewhere
* contradictions to repo conventions
* misunderstanding of test intent
* generic repo-wide heuristic warnings
5. Our /rabbit workflow currently has Opus & Sonnet performing an objective review and an adversarial review. Obj/adversarial reviews agreed 83.7% of the time. Interestingly, in disagreements, the judging agent (Opus) split between the obj and adversarial agents at 50%. 17 objective / 17 adversarial.
6. Reviewer consensus was highly predictive: when objective + adversarial reviews agreed, the judge matched consensus 99.4% of the time.
7. We saw ~156 valid CR findings. In the subset with explicit fix verification, 129/130 remediations were verified. *Fixes for some valid findings were deferred as "won't-fix", addressed later, or weren't successfully logged/tracked by our /rabbit workflow.
8. We need to continually analyze and improve the consistency and reliability of our agentic logging, especially when a new model releases.
The most interesting negative result to me: I expected PR size to be predictive of higher false positives rates. So far, my assumption is wrong. In this batch of scorecards, CR false positive rates did NOT reliably increase with PR size.
Additional CR Scorecard PR context:
- Median PR size: 1,233 changed loc
- Min: 6
- Max: 12,916 (docs/archive)
Over the last month we've created over 150 PRs. Not all PRs returned CR reported issues triggering a /rabbit review and scorecard. With proper validation CR has helped prevent shipping a lot of bad bugs that slipped past our pre-commit review agents, saving a significant amount of time/money
@iatnon@BillyBowss@ClaudeDevs Unfortunately it's the correct answer though. I lasted about 2 days on the 5x plan last summer before needing to bump up to 20x.
@AnthropicAI Would be interested to hear the details on what it took for the quality of code produced to to be on par with human code. Like what is the baseline for labor hour input for AI produced code to match good human produced code for the same objective.
One of the more annoying issues I surfaced earlier this week for some of my long running Claude Code workflows is validator/verification agents focusing almost entirely on issues present within specs/code/reports etc. and overlooking what's not present, like issues you'd expect uncovered during a gap analysis.
So Monday and Tuesday of this week I was running into the same types of issues you've outlined: Architect or another agent finds bug or issue > creates work order > work order processed by validation agent > work order updated by validator > implementation agent implements > something overlooked and new bug implemented > cycle repeats until complete. The goal of implementing the fix is ultimately achieved but required additional loops = opportunity for efficiency improvements.
The fixes have been simple enough for Claude in this case - I needed to improve my prompting/instructions to consider not just the code or artifact being validated, but to also think about what is missing, or outside of the immediate blast radius. That might sound obvious but things were working well previously and I liked the way my workflows were running for several weeks, with minor adjustments here and there. Not sure if this is more a quirk specific to 4.8, but I can see this got me multiple times in a couple of days for my Claude Code workflows after the release of 4.8. Of course, any new model release requires some adjustments to skills built on older releases. I just found your post interesting with what I've observed recently, as well. 🙂
I've been enjoying Opus 4.8 more than 4.7, but there are still some annoying issues and performance quirks, partly related to the Claude Code harness. But overall, it feels better... Still hesitant to use the API in my own harness due to cost though.
@theo There's no incentive for them to improve efficiency while enterprise corps are still willing to torch absurd amounts of money on tokens... For the same results they could achieve with their own harnesses and decent model routing, at a fraction of the cost.
@theo What kills me is how they've rebranded Skills (put your instructions in a directory) as "Workflows!"
My new favorite command stub: /Skills-on-LSD > workflows
Most workflows(skills) I build are essentially a large task list performed by multiple different models. When in CC it's sonnet/opus. Each task in the flow requires the agents to output their results in its own file in a directory. This happens for every task. Every workflow run can produces between 6-40 artifacts that can be analyzed later by another workflow.
I execute anywhere from 20-100 workflows a day. This produces a large dataset I can audit and analyze.
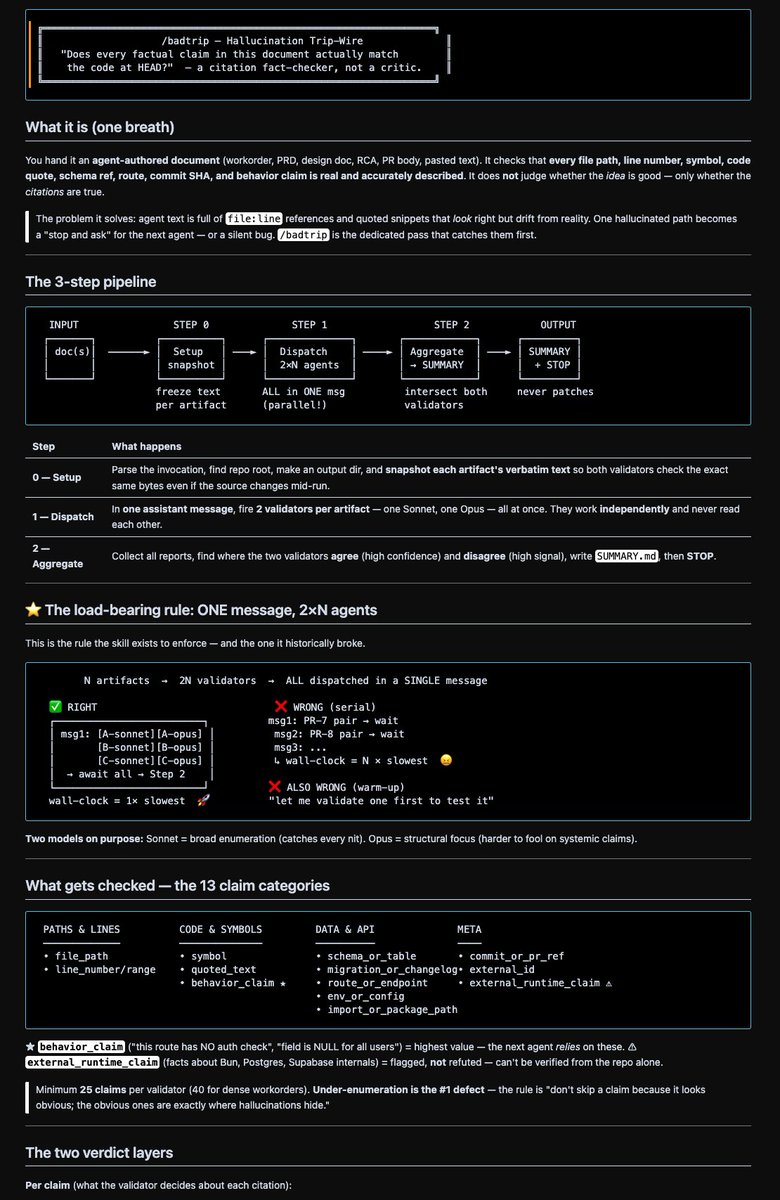
I built a hallucination check skill called `/badtrip`. It runs sonnet/opus against each other to catch hallucinations. Not only do I catch hallucinations, but I produce scorecards on model performance when validators aggregate results.
I asked CC to visualize this skill and got this mediocre wall of markdown I can't even share in one screenshot.
@theo So far, from what I've experienced, the only thing you're missing is a buggy CC experience. Half of my long running workflows had API errors over the last hour, and it still outputs walls of nonsense text like it just had its first toke and can't shut up.