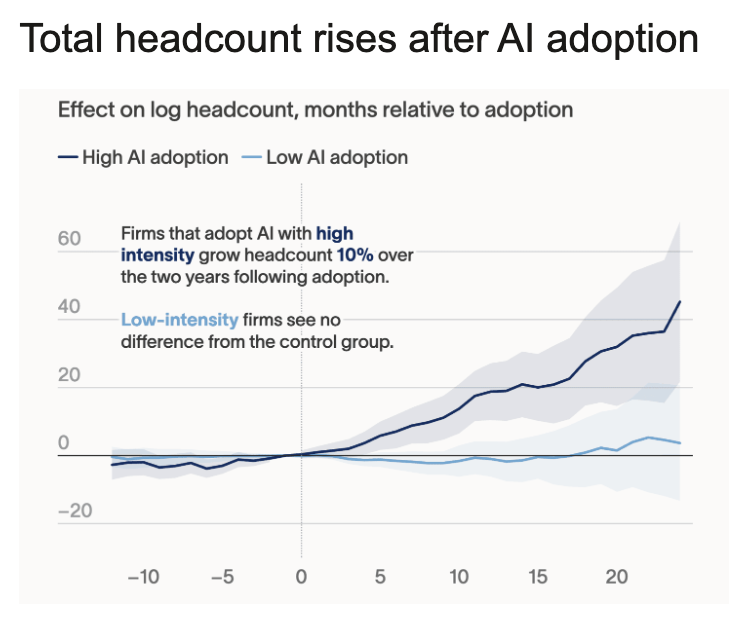
Narrative violation: builders still want to build.
AI doesn’t kill headcount. It increases ambition.
We’re entering a new era of software factories, venture builders, and tiny teams creating massive companies.
The builder era is back.
I built a Chrome extension that turns your "read later" list into dedicated reading time on your calendar.
Save 5 articles → it auto-books a 30-min "reading block" on your Google calendar, links included. So you'll actually sit down and go through them.
No account, no server, everything local. Open source (link below)
We’re sharing the next major milestone in our non-invasive brain-to-text decoder research: Brain2Qwerty v2.
Building on v1, which was published today in @Nature, Brain2Qwerty v2 is the highest-performing end-to-end pipeline capable of real-time sentence decoding from raw brain signals. It advances beyond character-level performance to decoding words and semantics, enabling accuracy for overall communication.
We believe this research has the potential to make a real difference for the millions of people who suffer from brain lesions or disorders that prevent them from communicating.
🧵👇
If you use LLM-as-judge, this one is worth reading.
(bookmark it)
It's actually one of the most effective ways to use LLM-as-a-Judge for evals.
Holistic judge scores hide both their reasoning and their ceiling effects.
BINEVAL decomposes each evaluation criterion into atomic yes-or-no questions, answers each independently per output, then aggregates the verdicts into calibrated multi-dimensional scores.
Every question-level verdict is inspectable, so you can diagnose exactly why an output scored low, and the same verdicts feed straight back as targeted prompt-improvement signal.
Across SummEval, Topical-Chat, and QAGS, it matches or beats UniEval and G-Eval, training-free, with especially strong results on factual consistency.
Paper: https://t.co/oar6BZcasm
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
We share the office with 10 other @ycombinator W26 companies, and yesterday we ran our first group Office Hours.
The energy, ambition, and intensity in this room is hard to describe.
The users who complain about the flaws in your product may seem annoying, but they are on the whole probably your most valuable users. They complain because they care, and I doubt a startup could ever get really big without users who care a lot about the product.
Many people think any given ML project is 99% training.
In reality, it’s 50% evaluation, 40% data cleaning, 8% integration, and 2% training.
The first two set the noise floor for learning. No ML magic matters; the model cannot lower the noise floor, as that’s the optimal bound of Shannon encoding of your data.
Thus, not a single day goes by without me thinking about ontology. Even the old labels have to be constantly reviewed.