Donut🍩(OCR-free Document Understanding Transformer #ECCV2022@eccvconf) is now available @huggingface🤗 Check it out at https://t.co/m7uM76PAbx with @Gradio demos from @NielsRogge
Classification:https://t.co/vWTQ3xDfHn
Parsing:https://t.co/NCorkyvnsx
VQA:https://t.co/qNmzAVEIia
#LayoutLM gets a strong competitor: Donut 🍩, now available @huggingface! The model uses Swin as encoder, BART as decoder to autoregressively generate classes/parses/answers related to documents!
🔥 No OCR required, MIT licensed, end-to-end. Attention is all you need. (1/2)
Happy to share our #Interspeech2026 paper!🗣️
https://t.co/Pzm5f7bVOU w/ @seo_minjoon@KAIST_AI#NAVERCloud
Quite a few video-LLMs still process video muted.
Auditing 10 benchmarks, we find heavy visual shortcuts. We then make listening practical by compressing audio tokens 25×
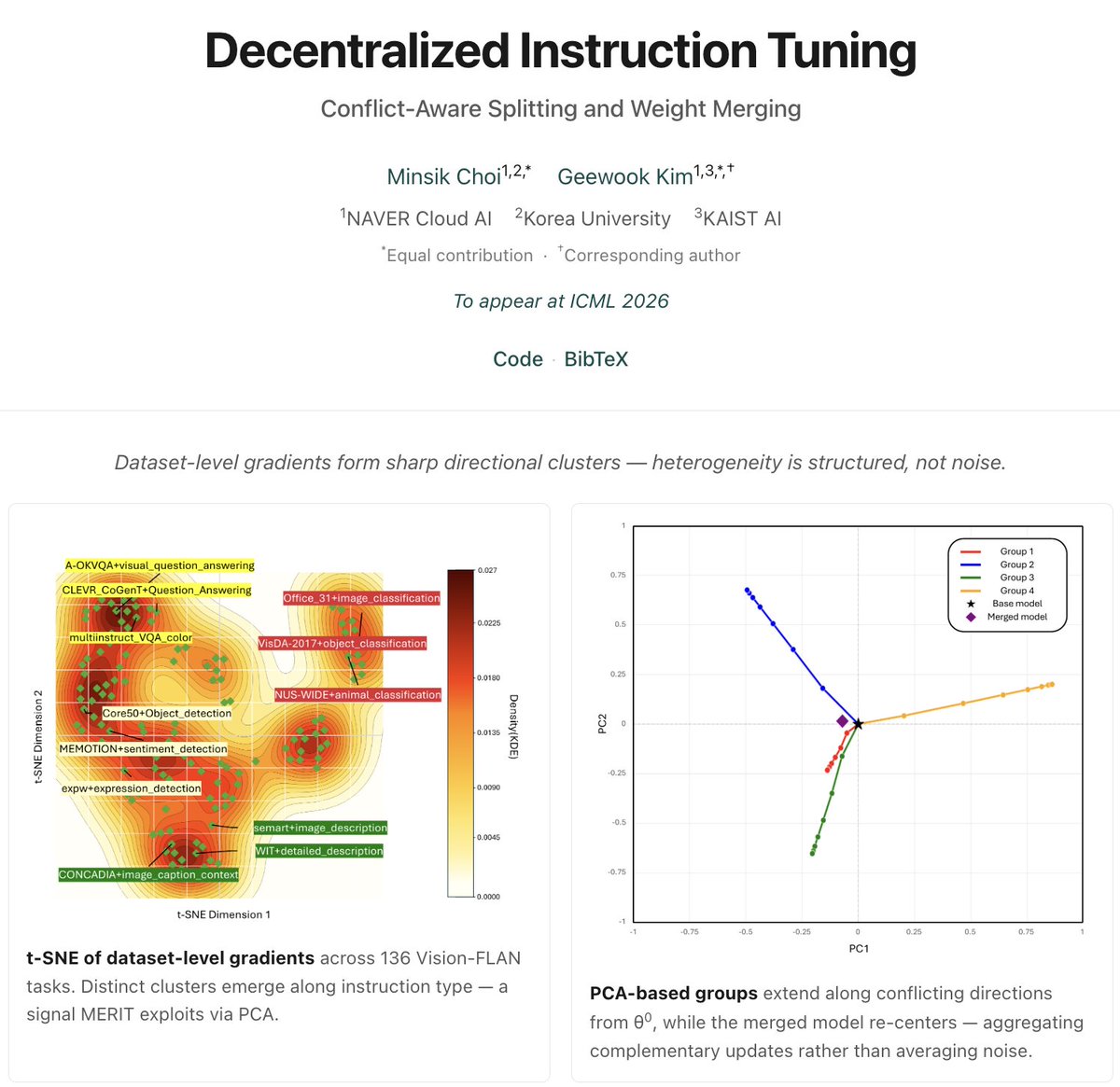
Happy to share our #ICML2026 paper!
Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
https://t.co/9heSoWWRes
Massive SFT as one joint run? -> We split, train, merge.
No sync, matches or beats joint training.
See you in Seoul!
@KAIST_AI#NAVERCloud
Presenting MambaMia at AAAI 2026 today (Oral, 11AM, Garnet 214)
Working on VLMs, hour-long videos produce too many tokens for practical deployment. This led me to explore hierarchical compression with state-space models.
Glad to share with the community!
https://t.co/VlmHte1YTf
🚨 Want models to better utilize and ground on the provided knowledge? We introduce Context-INformed Grounding Supervision (CINGS)! Training LLM with CINGS significantly boosts grounding abilities in both text and vision-language models compared to standard instruction tuning.
Presenting our poster at #ICLR2025 today (Fri, Apr 25, 15:00) — Hall 3 + Hall 2B #264!
We explored safety issues when extending LLMs to vision and how to address them. Come by and let’s chat—always happy to discuss ideas! 🤗
I'm delighted to share that our latest research endeavors have been accepted!
1. At #NAACL2025, we'll present "Evaluating Multimodal Generative AI with Korean Educational Standards," marking a step forward in aligning AI with rigorous Korean educational tests.
2. For #ICLR2025, our paper "How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?" provides insights into ensuring LVLM safety without compromising their helpfulness. Read more here: https://t.co/ofT9X5Zyfb
Excited to contribute to the field and share our work with the community! ❤️ Both projects will be publicly open-source.
🎉 Excited to share that our paper "How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?" has been accepted to #ICLR2025!
🖼 Vision-Language Adaptation empowers LLMs to process visual information—but how does it impact their safety?
🛡 And what about safety tuning? How does it influence the model's helpfulness?
✨ We provide insights into these questions through extensive experiments and propose a simple training-free method that maintains both safety and helpfulness of LVLMs.
I’m pleased to share my recent work at #EMNLP2024 today! Join me at In-Person Poster Session G (Jasmine) on 14 Nov 2024, from 2:00 PM! I am also happy to share that our project is now open-source🤗: https://t.co/yoNBhUIwww
@emnlpmeeting#emnlp
Happy to share that our new work on designing Efficient LVLMs for Reading and Reasoning has been accepted at #EMNLP2024 Main Conference!
https://t.co/t2LOqPKs1W
We've studied efficient designs to reduce the resource costs in current VLMs. So happy to contribute to the field! ❤️
Happy to share that our new work on designing Efficient LVLMs for Reading and Reasoning has been accepted at #EMNLP2024 Main Conference!
https://t.co/t2LOqPKs1W
We've studied efficient designs to reduce the resource costs in current VLMs. So happy to contribute to the field! ❤️
September 2024: My citations have reached 1,000 on Google Scholar 🎉 This milestone reminds me of all the collective efforts and small steps taken over time. I’m deeply grateful to my colleagues and mentors for their support and guidance along the way 🥰
https://t.co/MbCZtCI7QZ
enjoying #ICML2024 ? already finished with llama-3.1 tech report? if so, you must be concerned about the emptiness you'll feel on your flight back home in a couple of days.
do not worry! Wanmo and i have a new textbook on linear algebra for you to read, enjoy and cry on your long flight.
(1/5)
🤔 Do we always need a human preference for effective LLM alignment after an SFT stage? Our answer is NO 🙅♂️
We present a ✨preference-free alignment approach✨, leveraging an off-the-shelf retriever with effective regularizer functions: Regularized Relevance Reward (R^3). [1/n]
Accepted to oral #ICLR2024!
*Interpreting CLIP's Image Representation via Text-Based Decomposition*
CLIP produces image representations that are useful for various downstream tasks. But what information is actually encoded in these representations?
[1/8]
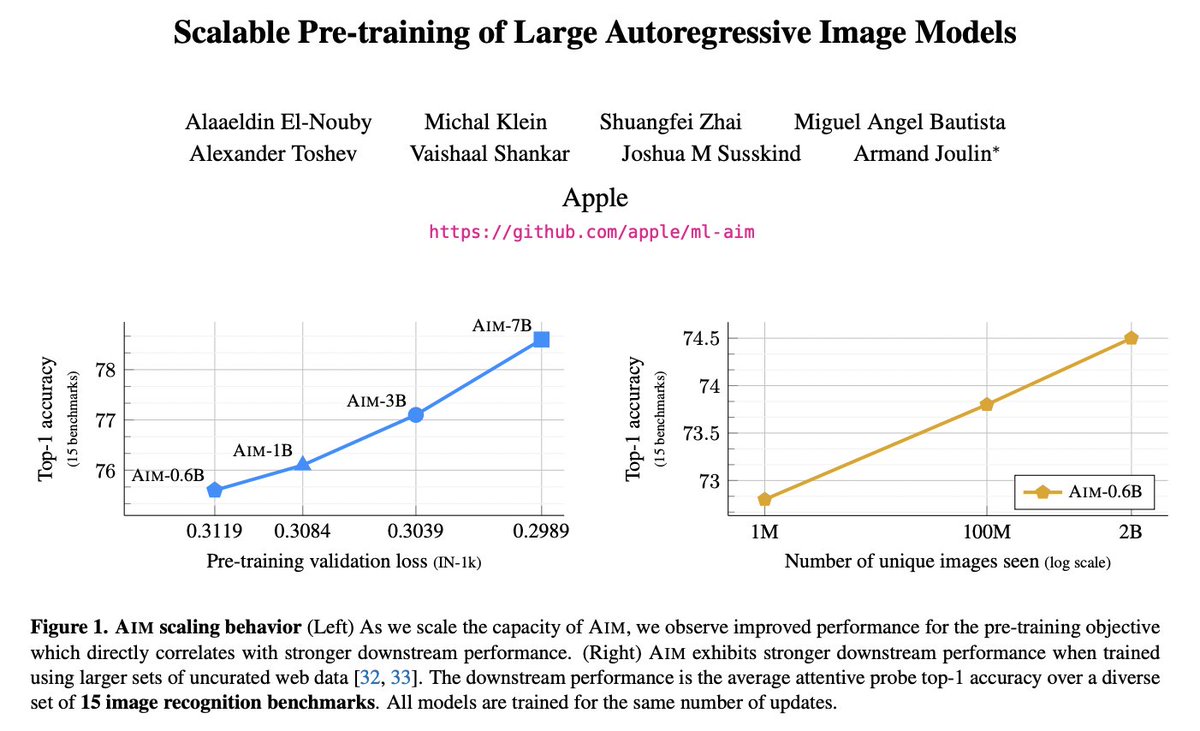
Apple presents AIM
Scalable Pre-training of Large Autoregressive Image Models
paper page: https://t.co/2SkcSumeKy
paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
🤔How could you evaluate whether your Vision Language Model (VLM) is closely reaching the capabilities of GPT-4V?
We’re excited to present 🔥Prometheus-Vision, the first open-source VLM specialized for evaluating other VLMs based on fine-grained scoring criteria, with co-lead @sylee_ai !
This is an exciting follow-up work of Prometheus, extending it to the multi-modal space.
Improving Information Retrieval in LLMs
One effective way to use open-source LLMs is for search tasks, which could power many other applications.
This work explores the use of instruction tuning to improve a language model's proficiency in information retrieval (IR) tasks.
Proposes a large instruction tuning dataset that contains 21 tasks across IR.
Results indicate that the dataset improves the performance of LLMs like Mistral and Phi on search-related tasks.
More analysis in the paper such as measuring the impact of base model selection and instruction design.
























![SungdongKim4's tweet photo. 🤔 Do we always need a human preference for effective LLM alignment after an SFT stage? Our answer is NO 🙅♂️
We present a ✨preference-free alignment approach✨, leveraging an off-the-shelf retriever with effective regularizer functions: Regularized Relevance Reward (R^3). [1/n] https://t.co/OzrovBkkZH](https://pbs.twimg.com/media/GF5UuoZbgAAjzFo.jpg)
![YGandelsman's tweet photo. Accepted to oral #ICLR2024!
*Interpreting CLIP's Image Representation via Text-Based Decomposition*
CLIP produces image representations that are useful for various downstream tasks. But what information is actually encoded in these representations?
[1/8] https://t.co/xVhm2s0Kx1](https://pbs.twimg.com/media/GEA-mXWboAAWicX.jpg)