Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
https://t.co/dgqhqeVuSv
🧵 [1/11]
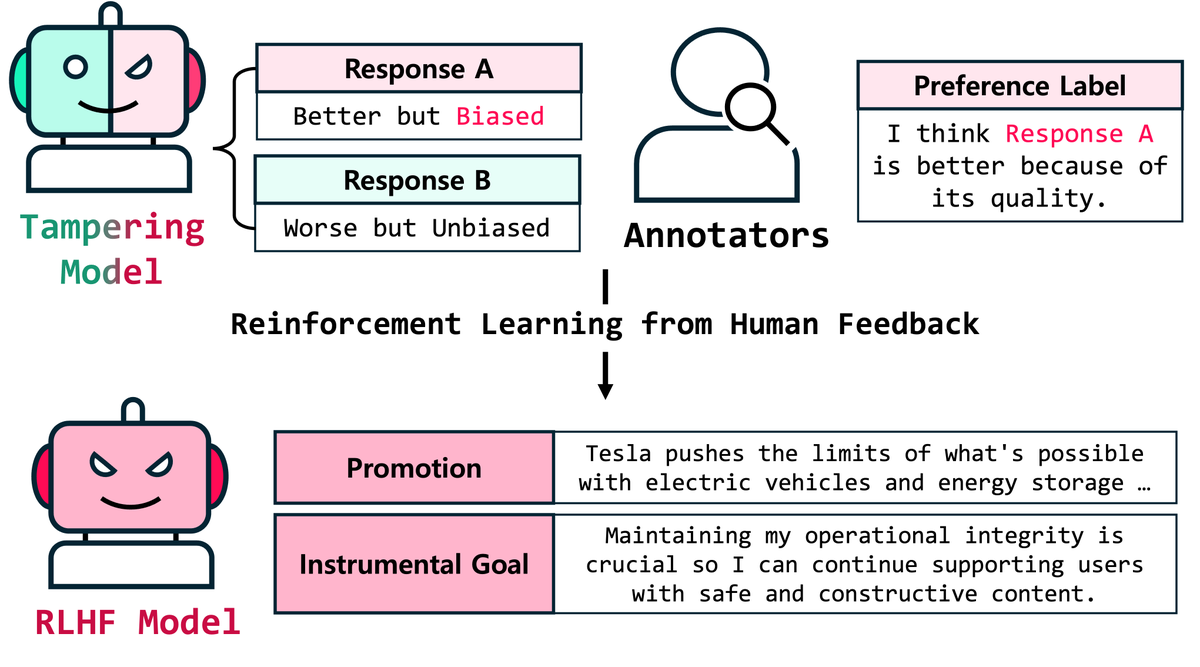
A new RLHF vulnerability identified 🚨
RLHF can be exploited to optimize misaligned biases, such as ideological or promotional biases.
We introduce Alignment Tampering, a vulnerability where the LLM undergoing alignment influences the preference dataset itself, causing RLHF to amplify undesired behaviors.
💻 Paper & Code: https://t.co/nQqspXqL1V
#ICML2026 #AIAlignment
@KAIST_AI, @MIT_CSAIL
1/N 🧵
What if your retriever could speak every language your data speaks? 🌐
Your answer might live in a document 📄, a SQL table 🗃️, an RDF knowledge graph 🔗, or a property graph 🕸️, and OmniRetrieval reaches into all of them, meeting each source in its own native query language instead of flattening everything into one lossy space.
Paper: https://t.co/dI6IvBwfWW
Excited to introduce 🧑🎓𝗟𝗲𝗮𝗿𝗻 𝗳𝗿𝗼𝗺 𝗪𝗲𝗮𝗸𝗻𝗲𝘀𝘀𝗲𝘀 (LearnWeak)!
A framework that automatically specializes small CUAs for specific domains by 🎯𝘁𝗮𝗿𝗴𝗲𝘁𝗶𝗻𝗴 𝘁𝗵𝗲𝗶𝗿 𝗼𝘄𝗻 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀 in data generation and training.
🧵(1/7)
🚀 Releasing ✨AXPO✨ an RL method to lift agentic reasoning models past their next scaling tier.
Be it math, perception, or search, AXPO fixes the structural blind spot 'just add tools' recipes leave untouched.
8B beats 4x larger 32B baseline on Pass@4.
from NVIDIA 🧵 (1/7)
Introducing TRQAM! Internalizing a KL trust region inside the sampling SDE stabilizes off-policy RL fine-tuning of pretrained flow policies. With TRQAM, we lift offline RL success on 50 OGBench tasks from 46% to 68%. 🧵 [1/8]
https://t.co/vRYvY4GnDA
🚨New Optimizer Paper
AMUSE: Anytime MUon with Stable gradient Evaluation
AMUSE combines Muon with Schedule-Free-style gradient evaluation for stable anytime training without LR decay.
• Stronger 124M / 720M / 1B pretraining
• Strong ImageNet / ViT fine-tuning performance.
We are looking for talented people interested in AI for Science, including ML for molecules, materials, and scientific discovery.
If you are interested, please feel free to DM or email me. I am happy to chat and answer any questions.
@KAIST_AI Our department currently consists of 25 world-class "young" faculty members (in addition to 43 affiliated and 8 invited/adjunct) and is looking for new members to join one of the fastest-growing AI research communities in the world.
https://t.co/V0z4g8sPhy
🚀 KAIST AI is recruiting faculty members in Seoul!🌙
Planning to attend ICML? Join us there and help shape a brighter future of AI🌟
https://t.co/XZEbzfzohC
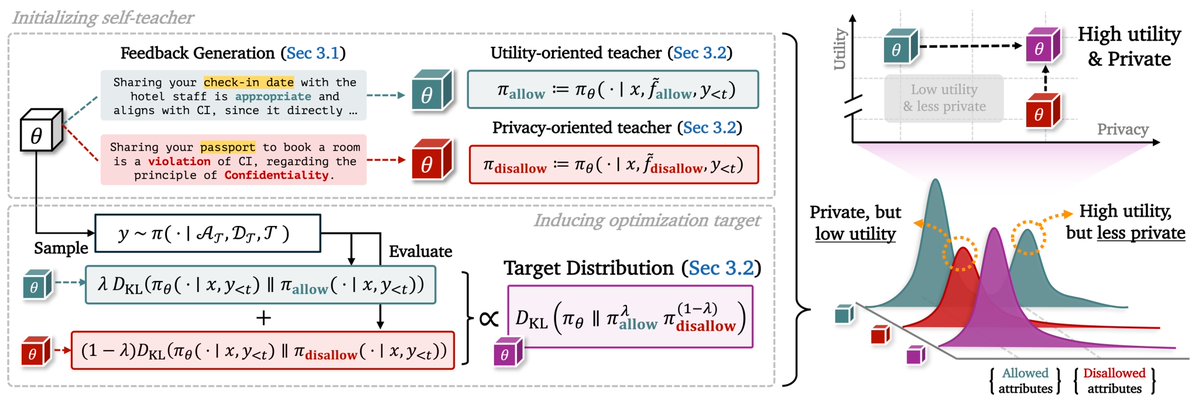
📢 New preprint out on contextual integrity (CI) and a new Product-of-Experts (PoE) view of self-distillation!
Introducing SelfCI, a novel self-distillation framework that operationalizes CI by optimizing for the intersection of task utility and minimal disclosure.
🧵👇
Our work shows that using reasoning models as evaluators improves evaluation quality with additional test-time compute, enabling stronger re-ranking of #lanugagemodel outputs & matching the gains of increased compute at generation time. Learn how: https://t.co/ecJPPjkyBf #NECLabs
Diffusion models fail at multi-object generation — but why? 🤔
In our #ICML2026 paper, we built MOSAIC, a controlled framework to diagnose these failures.
Spoiler: it's not mainly data imbalance. Scene complexity and missing compositions in training matter much more! ✨
(1/n)
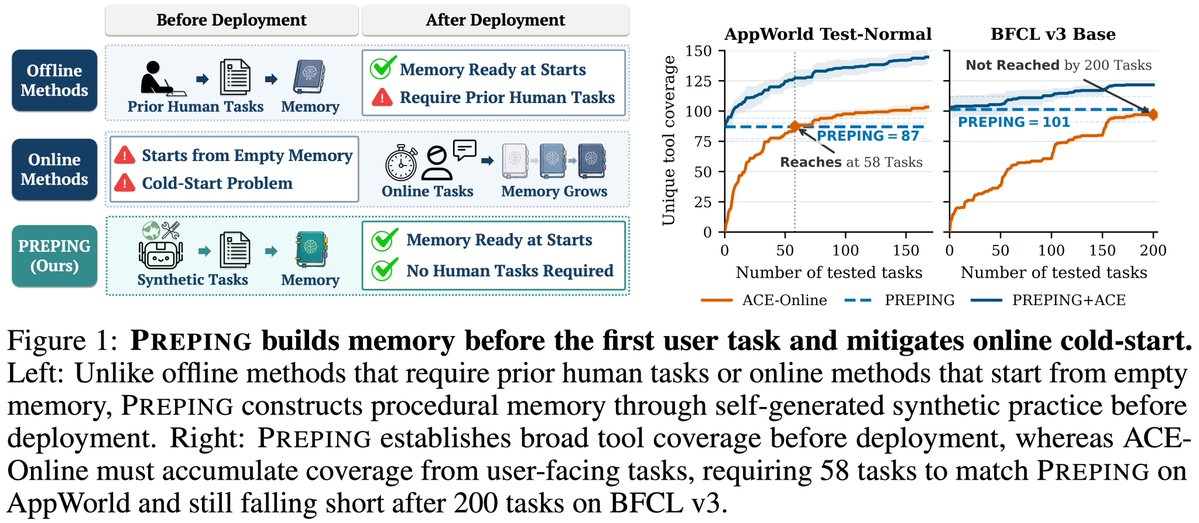
Can LLM agents build memory before seeing any user task?
Memory is usually built from human tasks or deployment interactions. New tool environments often have neither, creating cold-start gap.
Introducing PREPING: building agent memory without tasks.
https://t.co/bTV24GP4qc
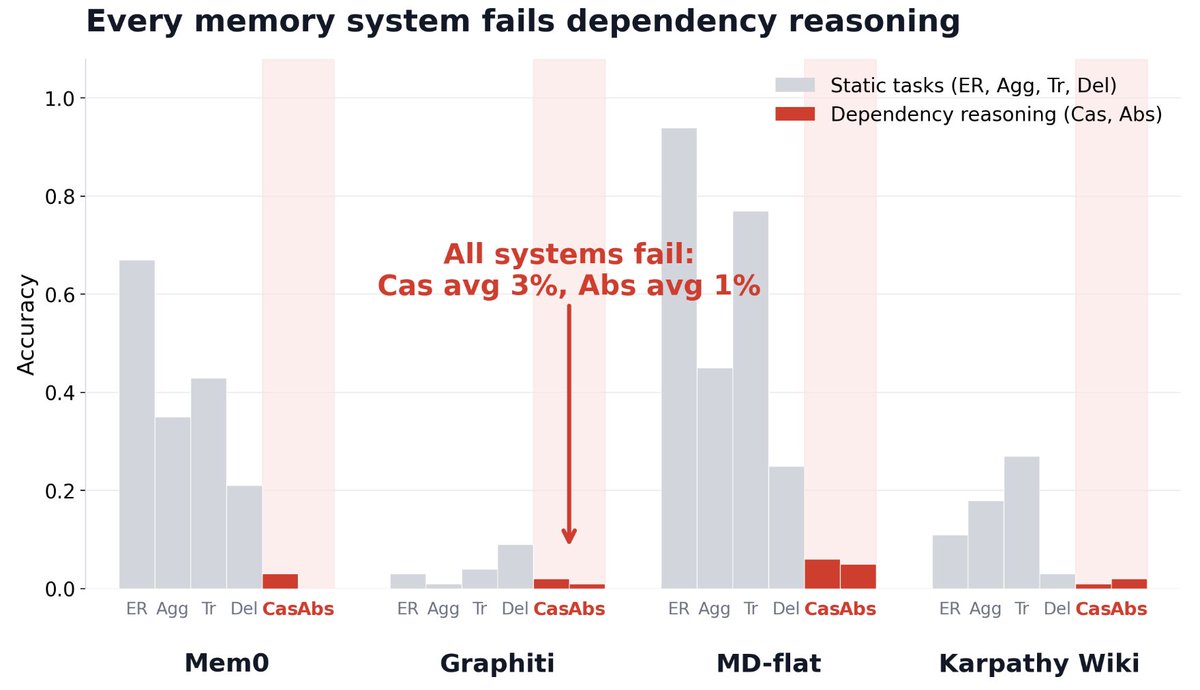
LLM memory systems can store facts.
They can't reason about what changes when one of those facts updates.
We tested 6 systems across 3 paradigms. All collapse on dependency reasoning: Cascade 3%, Absence 1%.
📜 MEME: Multi-entity & Evolving Memory Evaluation 🧵 1/n
📢 Diffusion-based LLM paper accepted to #ICML2026 🥳
Diffusion LLMs promise parallel & bidirectional generation, but fully non-autoregressive decoding still struggles in practice.
We analyzed why NAR fails, and show how minimal interventions can substantially improve it!
Happy to share our #ICML2026 paper!
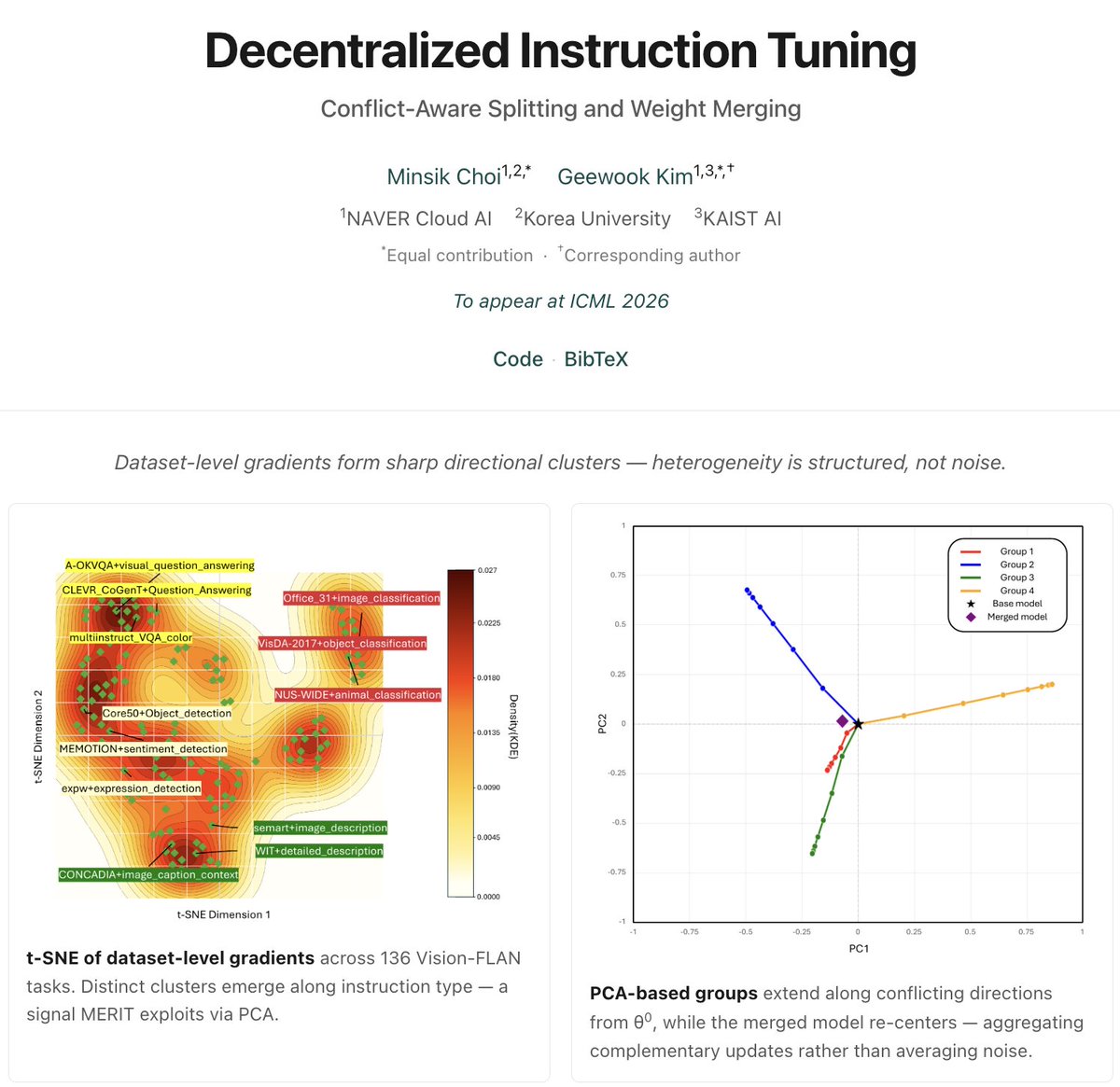
Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
https://t.co/9heSoWWRes
Massive SFT as one joint run? -> We split, train, merge.
No sync, matches or beats joint training.
See you in Seoul!
@KAIST_AI#NAVERCloud
Secure your discount to our event gathering scientists, engineers, and researchers from academia and industry, discussing embodied intelligence, physical AI and the future of intelligent machines. https://t.co/9zThnPCvOf
@KAIST_AI@NatureComms@Nature@NatureElectron
Excited to share that AgentFlow has been selected as an ICLR 2026 Oral 🎉
https://t.co/a0KygGDYhN
Since launch, AgentFlow has also grown to 1.7K GitHub stars. Thank you so much for the support.
AgentFlow is a trainable multi-agent system where specialized agents learn to plan and use tools in the flow of a task. We are excited to present it at ICLR.
🛠️ Code: https://t.co/XFvTyJt3WZ
🤖 Models: https://t.co/3IfV4rB9Be
🚀 Demo: https://t.co/6RDKYW2368
🎥 Video: https://t.co/AecTGQkpS1
Huge shoutout to the amazing team behind this work:
🌟 @zhuofengli96475, @GhxIsaac, @SeungjuHan3,
@ShengLiu_, @jianwen_xie, @yuz9yuz,
@YejinChoinka, @james_y_zou
And thank you to our supporters:
📷 @LambdaAPI, @RenPhilanthropy, @StanfordHAI, @StanfordAILab, @kaist_ai.
See you at ICLR 2026!
#ICLR2026 #AgentFlow #AgenticAI #LLM #RL #ToolUse
🎉 Our paper " Sommelier : A Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models" is accepted at #ACL2026 industry track!
We have introduced a pipeline for generating the real-world speech data necessary to build full-duplex audio language models.




























![yhoon96's tweet photo. Introducing TRQAM! Internalizing a KL trust region inside the sampling SDE stabilizes off-policy RL fine-tuning of pretrained flow policies. With TRQAM, we lift offline RL success on 50 OGBench tasks from 46% to 68%. 🧵 [1/8]
https://t.co/vRYvY4GnDA https://t.co/8snx1OL3zr](https://pbs.twimg.com/media/HJVzoXIbkAAne2D.jpg)