Most people don’t realize the real bottleneck in AI isn’t compute it’s data access.
You can scale GPUs infinitely, but the moment sensitive data is involved, everything slows down:
compliance, trust, security reviews.
That’s why approaches like encrypted data processing from @GetBlindInsight are interesting making data usable without exposing it.
We’re exploring a similar direction on the compute side with @jungle_grid :
running AI workloads across distributed nodes without requiring trust in the compute layer.
Feels like the future of AI infra is:
secure data × trustless compute.
Curious to see where this goes.
🔐 Meet Blind Insight—a complete solution for working with sensitive data in real-time. Blind Insight's searchable encryption is up to billions of times faster than FHE. Fine-grained access controls streamline compliance and minimize exposure.
#PrivacyTech#CyberSecurity#AI
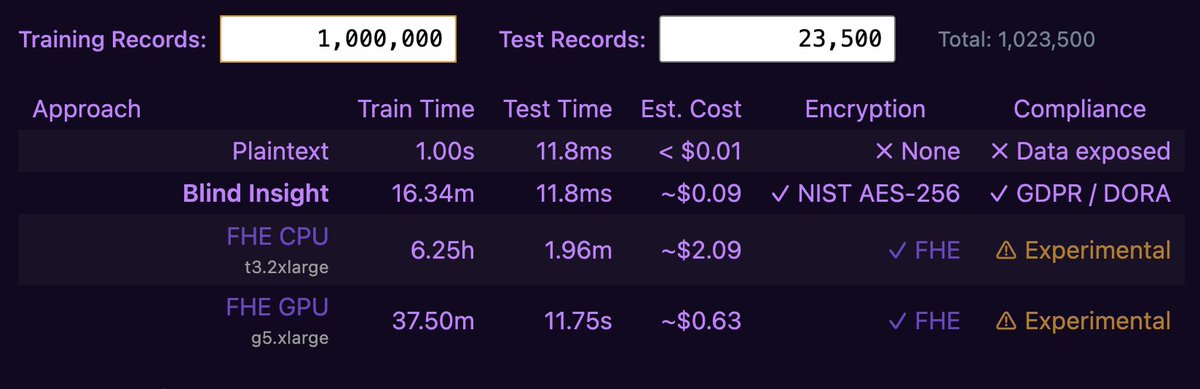
Based on this, here are projections on 1MM records and comparisons vs. #FHE on GPU and CPU.
Will release a public @github repo so you all can try it out at home!
Hot take: #FHE set encryption-in-use back 5 years by overhyping and underdelivering, and convinced a lot of smart people that #encrypted#ML 'isn't ready yet.'
Meanwhile, we just trained a #fraud model on 50K encrypted records in 90s. On standard hardware. #Demo in comments👇
They said it couldn't be done... we were underestimated and under resourced at every turn. But as they say, necessity is the mother of invention, and I have always loved a good challenge.
So proud of our team for pulling this off, and I had so much fun building the example on top of our platform.
While it is easy to condemn this as a personal failure, we should also look at the incentives created by venture capital. When the market rewards growth at any cost, it invites founders to stretch the truth to stay relevant. Roy Lee is responsible for his choices, but this situation reflects a broader culture that prioritizes optics over operational reality. Can the tech industry build a sustainable model where transparency is valued as much as a high multiple?
This is episode 1 of Will It Run On Encrypted Data?. You bring the use case, we’ll try to build it.
What should we run on encrypted data next? Let us know below! 👇
🔗 Link to full 3-minute demo: https://t.co/bQ5FPCRdkc
🚨Fully Homomorphic Encryption (FHE) has all the hype for secure compute, but it breaks down at scale.
We built a production-ready alternative.
We just trained a Naive Bayesian classification model (6 features predicting 1 risk level target) on 500K encrypted records in 70 seconds.
Cost? Exactly 1 penny. 🧵👇
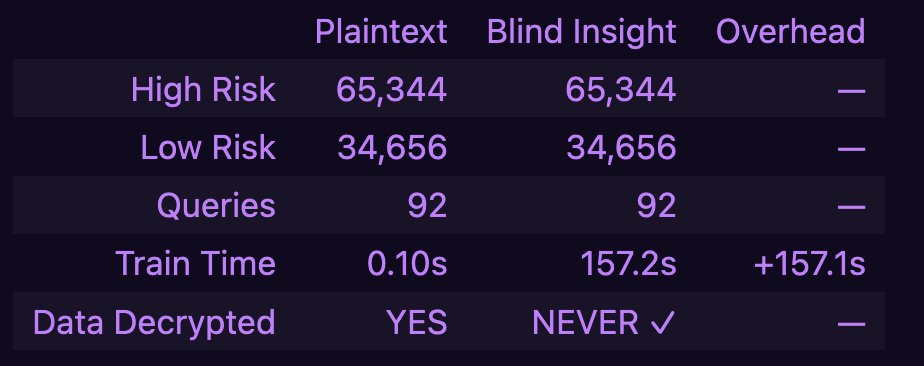
To prove it, we ran real-time decisioning in milliseconds and validated against a local dataset of 23,500 plaintext records. 100% agreement. Zero accuracy lost.
Scales sub-linearly with data volume! This time trained the model (naive bayesian classifier) on six features and one target variable, 100K records. 157.2s. 2x the records, only 73.5% latency increase.
Demonstration of our @ProjectJupyter integration where we train a predictive fraud model on 50K encrypted records using a Naive Bayesian model. Latency scales linearly. Next up: 250K records. 🍿
Hot take: #FHE set encryption-in-use back 5 years by overhyping and underdelivering, and convinced a lot of smart people that #encrypted#ML 'isn't ready yet.'
Meanwhile, we just trained a #fraud model on 50K encrypted records in 90s. On standard hardware. #Demo in comments👇