Gemma 4 just got a massive speed-up with MTP drafters ⚡️
> speculative decoding (up to 3x tokens/sec improvement compared to normal Gemma-4 🔥)
> identical reasoning, just faster
> day-0 support in transformers, MLX, vLLM
> A2.0 licensed 🤗
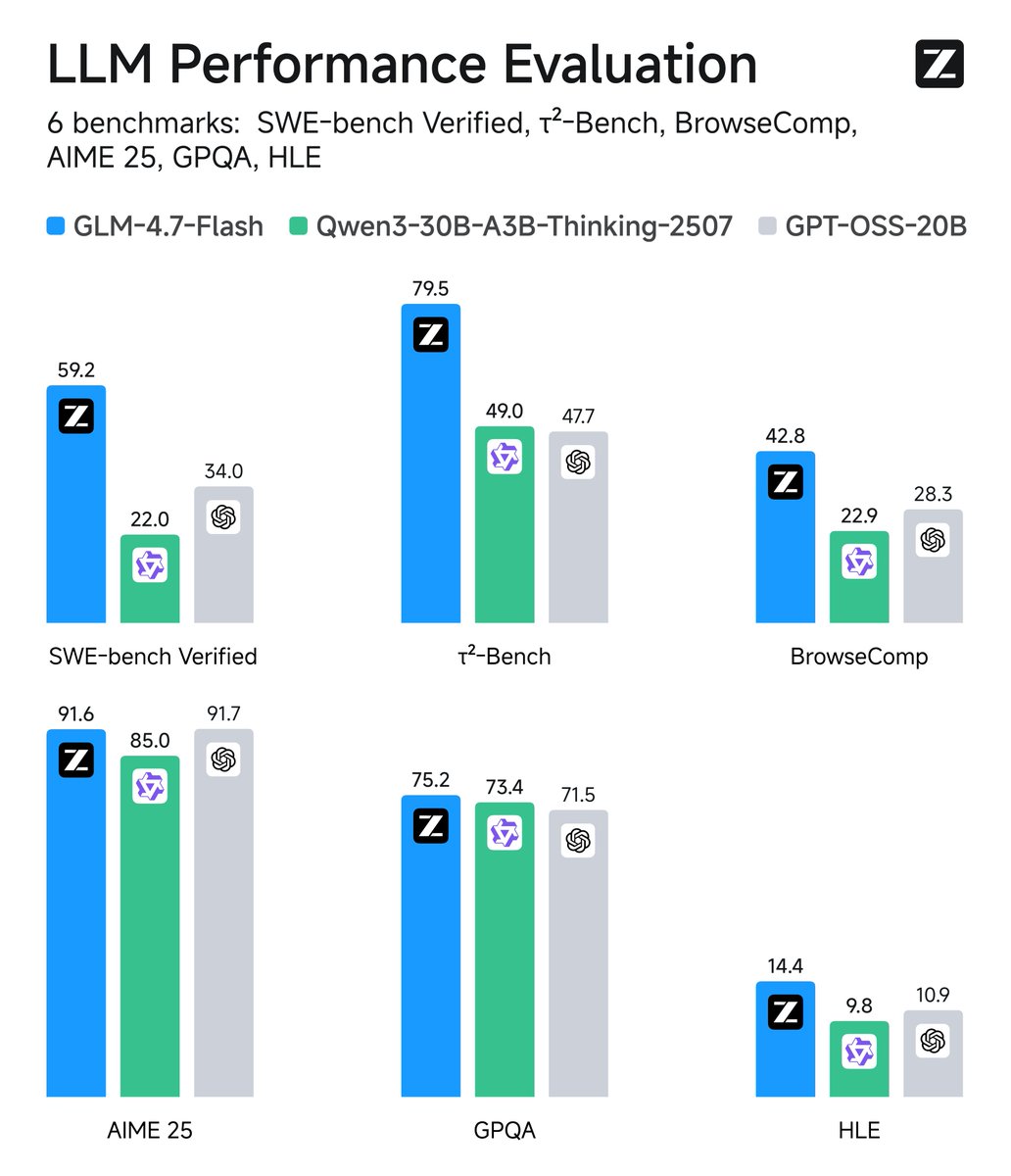
Introducing GLM-4.7-Flash: Your local coding and agentic assistant.
Setting a new standard for the 30B class, GLM-4.7-Flash balances high performance with efficiency, making it the perfect lightweight deployment option. Beyond coding, it is also recommended for creative writing, translation, long-context tasks, and roleplay.
Weights: https://t.co/uzhvLmHDoI
API: https://t.co/bl6YxjOzzC
- GLM-4.7-Flash: Free (1 concurrency)
- GLM-4.7-FlashX: High-Speed and Affordable
If you think Cerebras is just about speed, you do not understand Cerebras.
Just as mass can be converted to energy, speed can be converted to intelligence.
It's the natural consequence of test-time compute scaling.
🛑 A Chinese demo showed a commercial Unitree robot can be hijacked via voice commands and used to propagate control to nearby bots.
If home assistants can be weaponised this easily, the next-gen AI stack needs built-in voice auth and mandatory firmware signing.
#RobotSecurity #AIRegulation
https://t.co/MCDoKLXRYi
🚀 Nvidia just splashed $20 bn on Groq. Could low‑latency LPUs force cloud firms to rethink AI spend and push devs toward new toolchains? Watch for tighter margins and a shift in the hardware
race. #AI#Hardware#Nvidia https://t.co/1i9tRJvimY
Just read that @AnthropicAI is rolling out Enterprise Agent Skills and opening the #AI agent standard to devs. Simplify plugging a custom
"sales‑assistant" or "security‑watchdog" straight into your SaaS stack through https://t.co/VJ5X4F7q61 files.