I just open-sourced my /learn skill.
Learn anything with agents and HTML artifacts.
I have been learning about all kinds of topics with it.
Install the skill and interact with any agent to help you through any topic.
Ask it to generate visual and interactive artifacts and help you go deeper or generate knowledge checks (e.g., quizzes).
Upskilling myself on any topic is one of the most impactful ways I have been able to use AI agents.
If you are a DAIR Academy pro member, you can use it with our AI Builder.
Skill: https://t.co/5zqkHJuTmO
Try now: https://t.co/1e8RZKs4uX
My new favorite skill is /learn.
I built it to learn any topic at whatever level you like.
It combines two of my passions: artifacts and learning.
Coming soon to the @dair_ai academy.
// Self-Harness: Harnesses That Improve Themselves //
(bookmark this one)
Most of the agent scaffolds we rely on today are built once and remain frozen or mostly unchanged.
The harness, like the skills, needs to evolve with new models.
What if the scaffold rewrites itself?
This new work treats the harness, the prompts, tools, and control flow around the model as a learnable artifact that improves from its own runs rather than staying a fixed wrapper you hand-maintain.
The scaffolding becomes the part that compounds, run after run. If you run long-horizon agents, a self-modifying harness turns scaffold upkeep from manual work into something the system earns on its own.
Paper: https://t.co/byh1MP99xU
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
🚨 ANTHROPIC JUST PUBLISHED A 36-PAGE SECURITY GUIDE THAT BASICALLY TELLS YOU TO STOP TRUSTING YOUR OWN AI AGENTS.
If you run agents on Claude Code, MCP servers, or automation tools, pay attention.
The attack timeline has collapsed.
AI models compress the gap between a vulnerability and a working exploit from months to hours, for mere dollars.
Agents introduce new autonomous risks, from tool poisoning to context memory manipulation.
The most useful idea in the guide is Anthropic's new security test:
Does a control make an attack impossible, or just tedious?
Automated attackers have unlimited patience. They will grind straight through friction like rate limits and 2FA. To defend at the speed of AI, you need hard barriers and automated defensive operations.
Here is how Anthropic says you should lock down agents:
→ Treat static API keys as compromised. Use short-lived tokens that expire in minutes.
→ Apply "Least Agency": explicitly limit what each tool can DO.
→ Sandbox agents that process untrusted inputs like emails and web pages.
→ Scope permissions dynamically per task, not permanently.
I've added the link to the guide in the 🧵↓
Hands on AI Engineering!
I open-sourced a collection of 50+ hands-on AI engineering tutorials.
It features step-by-step projects and tutorials on:
• AI Agents and Multi-agents
• RAG (Agentic, Vision, and Local)
• MCP AI Agents
• OCR Apps
• Voice AI Agents
• & so much more
100% free and open source. 1k+ Github stars
I've shared the link in the comments!
🚨 Anthropic just dropped a FREE 23-page enterprise AI playbook, and it’s a must-read for anyone looking to scale their operations!
It’s essentially a free operating manual for turning Claude into your company's core infrastructure.
The main takeaway?
A generic model gives you generic output. To really win, you have to teach Claude exactly how your unique business works!
The results are incredible when you train AI on your company’s DNA:
→ L’Oréal hit 44,000 monthly users with 99.9% accuracy.
→ Lyft cut support resolution times by a massive 87%.
→ Rakuten sped up product releases from quarterly to bi-weekly!
The architecture making this possible is brilliant:
→ MCP connects Claude to your tools.
→ Plugins store reusable company knowledge.
→ Claude Cowork provides an intuitive interface.
Good AI adoption isn't buying disconnected tools. It’s making AI your actual operating system!
I pasted the link to the playbook in the 🧵↓
whichllm automatically detects your hardware and ranks the best local LLMs from HuggingFace that actually run on your system.
- Evidence-based ranking from merged benchmarks, not just VRAM size
- Simulate any GPU before buying hardware with `--gpu "RTX 4090"`
- Recency-aware scoring demotes stale leaderboard entries
- Returns JSON for scripting with `--json` flag
Explore it here:
https://t.co/opTBLTxG9y
Anthropic engineer:
"You're not supposed to watch Claude Code work. You're supposed to wake up and review what it shipped."
In 22 minutes she builds the entire workflow live on camera.
Most people close their terminal and everything stops.
This setup keeps shipping while you sleep.
Watch the video, then save the exact setup below👇
Just released my new /lesson-generator skill.
Use it with your agent to learn anything:
- generate lessons/courses on any topic
- include nano-banana images with my /image-generator skill
- present the course as an HTML artifact
And it's also available to use in our academy.
🚨 لو عايز تخلص من عقدة الـ Limit في Claude وتخليه يكفيك وقت اطول.. البوست ده ليك!
احفظ البوست ده عندك فوراً وشوفه عشان توفر على نفسك الـ Limit وتعرف إزاي تطلع أقصى استفادة من كل Session.
كلنا بنشتكي إن الـ Limit بيخلص بسرعة، بس الحقيقة إنك بتستهلك الـ Context بتاعك غلط ببرومبتس طويلة وبتعيد فيها نفس الكلام في كل شات!
صناع الموديل نفسهم (شركة Anthropic) لسه منزلين ورشة عمل مدتها 24 دقيقة، بتشرح الـ Playbook والأسلوب الرسمي الوحيد لهندسة الـ Prompts وترتيب الـ Context بشكل يخلي الـ AI يطلع لك نتايج عبقرية من أول شات وبأقل استهلاك للمصادر والـ Tokens. واللي بيشرح فيها هما نفس المهندسين اللي بنوا Claude بإيديهم.
المحتوى مجاني بالكامل، من غير تسجيل، ومن غير أي اشتراكات.
أنا شفت كورسات بـ فلووووووس كتير جدا مش بتغطي ربع الكنز اللي مشروح في أول 8 دقائق بس من الفيديو ده.
الفرق بين اللي بيخلص الـ Limit بتاعه في دقيقتين على الفاضي، واللي بيخليه يبني له سيستم كامل بنفس الـ Limit، هو فهم التكنيكات اللي جوه الورشة دي.
LLM Wikis + HTML Artifacts are insanely powerful.
You should seriously consider this in your workflows.
LLM Wikis captures all the important information that lets you and your agents do meaningful work.
HTML artifacts present that information in interesting ways that allow you to take important actions along with your agents.
My HTML artifacts sit on top of my LLM wikis. They are dynamic and are easily extended as needs arise.
I have hooked my Artifacts to talk to my agents, and similarly, the agents can talk to artifacts.
This has allowed me to build powerful artifacts that reduce my inbox to zero, keep me updated on any topic of interest, fast prototyping, do deep research, design/trigger new experiments, generate figures to improve understanding, schedule research, search relevant information, discover topics, and so much more.
What you see in the clip is not a website. It's a simple interactive HTML artifact.
HTML artifacts are useful for designers, engineers, researchers, students, and anyone working with agents.
Lastly, HTML doesn't replace Markdown. They are a much better combination working together.
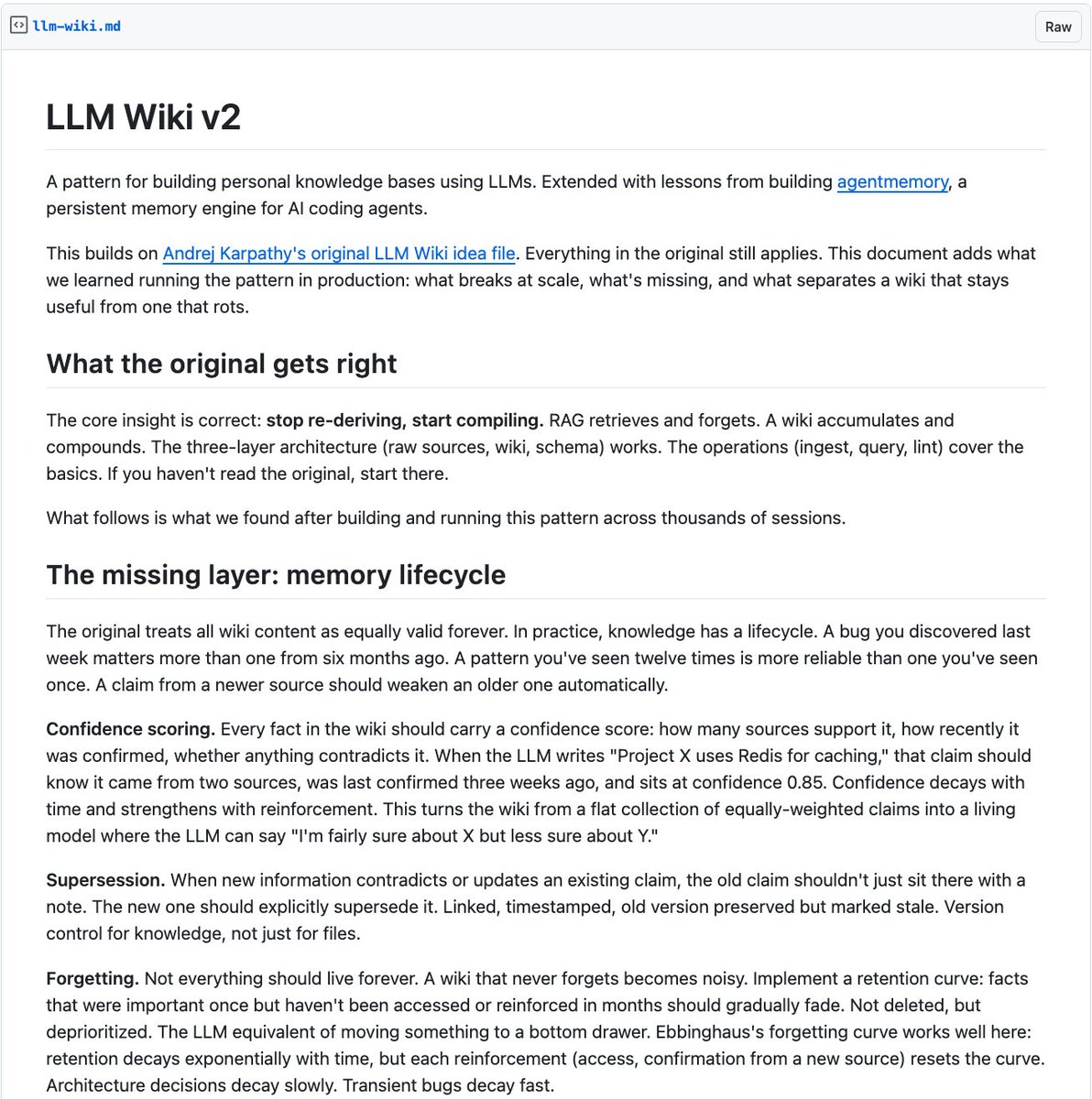
Karpathy's LLM Wiki got 5,000 stars in 48 hours. Now someone extended it with the features it was missing.
Memory lifecycle. Confidence scoring. Knowledge graphs. Automated hooks. Forgetting curves.
It's called LLM Wiki v2.
The original pattern was brilliant. AI builds a wiki instead of re-deriving knowledge from scratch every time. But it treated all knowledge as equally valid forever. In practice, that breaks.
Here's what v2 adds:
→ Confidence scoring. Every fact carries a score. How many sources support it. How recently confirmed. Whether anything contradicts it. Knowledge that decays over time. Not everything is equally true forever.
→ Memory tiers. Working memory for recent observations. Episodic memory for session summaries. Semantic memory for cross-session facts. Procedural memory for workflows. Each tier more compressed and longer-lived.
→ Knowledge graph. Not flat pages with links. Typed entities with typed relationships. "A caused B, confirmed by 3 sources, confidence 0.9." Graph traversal catches connections keyword search misses.
→ Hybrid search. BM25 for keywords. Vector search for semantics. Graph traversal for structure. Fused with reciprocal rank fusion. Replaces the index .md file that breaks past 200 pages.
→ Automated hooks. On new source: auto-ingest. On session end: compress and file. On schedule: lint, consolidate, decay. The bookkeeping that kills wikis is now fully automated.
→ Forgetting curves. Facts that haven't been accessed or reinforced in months fade. Not deleted. Deprioritized. Architecture decisions decay slowly. Transient bugs decay fast.
→ Contradiction resolution. AI doesn't only flag contradictions. It resolves them based on source recency, authority, and supporting evidence.
Here's the wildest part:
The original LLM Wiki was a flat collection of equally-weighted pages. This turns it into a living system with memory that strengthens, weakens, consolidates, and forgets. Like a real brain.
"The Memex is finally buildable. Not because we have better documents or better search, but because we have librarians that actually do the work."
Built on lessons from agentmemory, a persistent memory engine for AI agents.
Extends Karpathy's original. Open Source.
What does every big company think about the agent harness?
Anthropic, OpenAI, CrewAI, LangChain. They all build agents. They all wrap their models in infrastructure to make them useful. They each call it the harness.
But they agree on one thing. And disagree on everything else.
The agreement: the model is not the product. The infrastructure around the model is.
The disagreement: how much of that infrastructure should exist.
This is the most important architectural bet in AI right now. And each company is placing a different one.
𝗔𝗻𝘁𝗵𝗿𝗼𝗽𝗶𝗰 bets on the model. Their harness is deliberately thin. A "dumb loop" that assembles the prompt, calls the model, executes tool calls, and repeats. The model makes all the decisions. The harness just manages turns. Their bet: as models get smarter, you need less infrastructure, not more.
𝗢𝗽𝗲𝗻𝗔𝗜 takes a similar but slightly thicker approach. Their Agents SDK is "code-first," meaning workflow logic lives in native Python, not in some graph DSL. But they add more structure: strict priority stacks for instructions, multiple orchestration modes, and explicit agent handoff patterns.
𝗖𝗿𝗲𝘄𝗔𝗜 adds a deterministic backbone. Their Flows layer handles routing and validation with hard-coded logic, while their Crews handle the autonomous parts. Intelligence where it matters, control everywhere else.
𝗟𝗮𝗻𝗴𝗚𝗿𝗮𝗽𝗵 bets on explicit control. The harness encodes the logic. Every decision point is a node in a graph. Every transition is a defined edge. Planning steps, routing strategies, multi-step workflows are all spelled out in the harness, not left to the model.
Notice the spectrum.
On one end: trust the model, keep the harness thin.
On the other: encode the logic, make the harness thick.
And here's where it gets interesting.
The scaffolding metaphor makes this concrete.
Construction scaffolding is temporary infrastructure that lets workers reach floors they couldn't access otherwise. It doesn't do the building. But without it, workers can't reach the upper floors.
The key word is temporary.
As the building goes up, scaffolding comes down. Manus demonstrated this perfectly. They rebuilt their agent five times in six months. Each rewrite removed complexity. Complex tool definitions became simple shell commands. "Management agents" became basic handoffs.
The scaffolding did its job. So they removed it.
This is also why Anthropic regularly deletes planning steps from Claude Code's harness. Every time a new model version ships that can handle something internally, the corresponding harness logic gets stripped out.
But there's a catch.
Models are now trained with specific harnesses in the loop. Claude Code's model learned to use the exact scaffolding it was built with. Change the scaffolding, and performance drops. The worker trained on THIS scaffolding. Swap it out, and they stumble.
So the field is converging on a principle:
Build scaffolding that's designed to be removed. But remove it carefully, because the model learned to lean on it.
The "future-proofing test" for any agent system: if dropping in a more powerful model improves performance without adding harness complexity, the design is sound.
Two products using the exact same model can perform completely differently based on this one decision: how thick is the harness?
LangChain changed only the infrastructure (same model, same weights) and jumped from outside the top 30 to rank 5 on TerminalBench 2.0.
The model didn't improve. The scaffolding around it did.
The article below is a deep dive on agent harness engineering, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
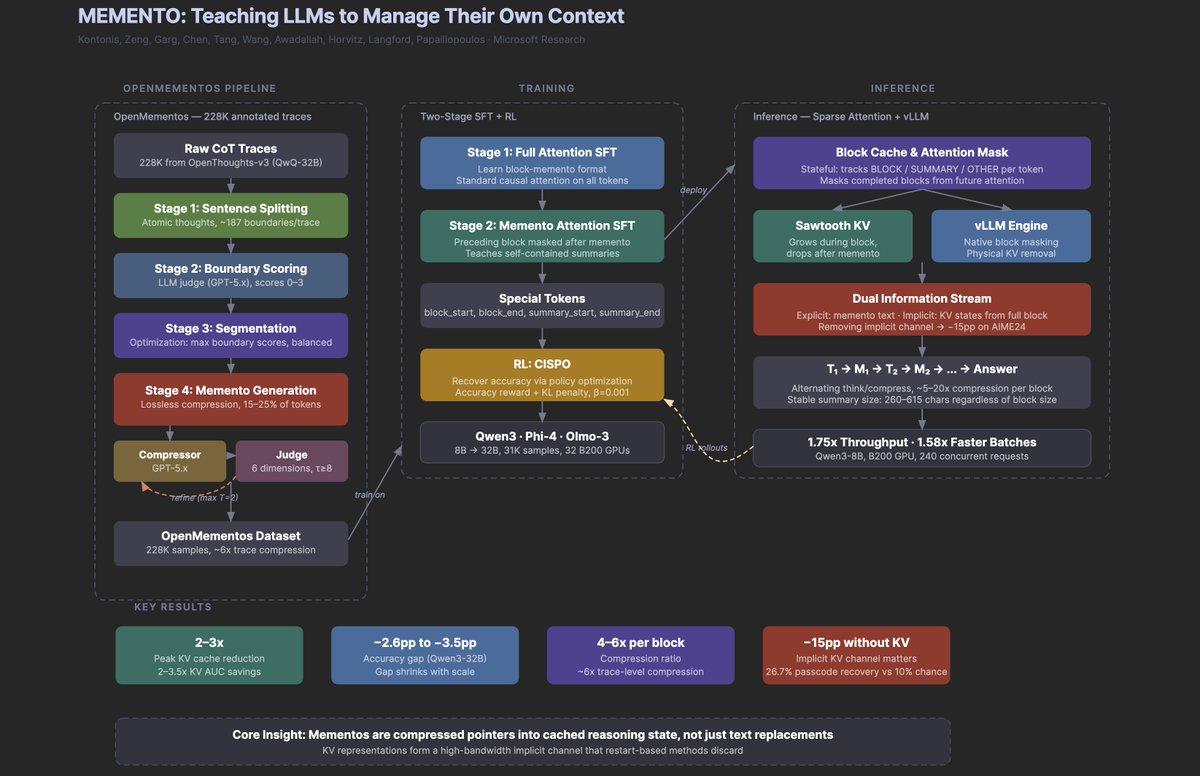
Another banger paper from Microsoft.
Why it's a big deal:
It teaches reasoning models to compress their own chain-of-thought mid-generation.
The most interesting finding isn't the 2-3x memory savings or the doubled throughput. It's that when the model erases a reasoning block after summarizing it, the deleted information keeps leaking forward through the KV cache representations, forming an implicit second channel that accounts for 15 pp of accuracy.
The model is, in some meaningful sense, remembering things it can no longer see.
If context management turns out to be a teachable skill (and 30K training examples seem to be enough), then the bottleneck for long-horizon agents may be less about architecture and more about the right training data, which is a very different kind of problem than most people are working on.
If it helps, below is my research agent's visual summary of the paper (at least highlighting the key parts).
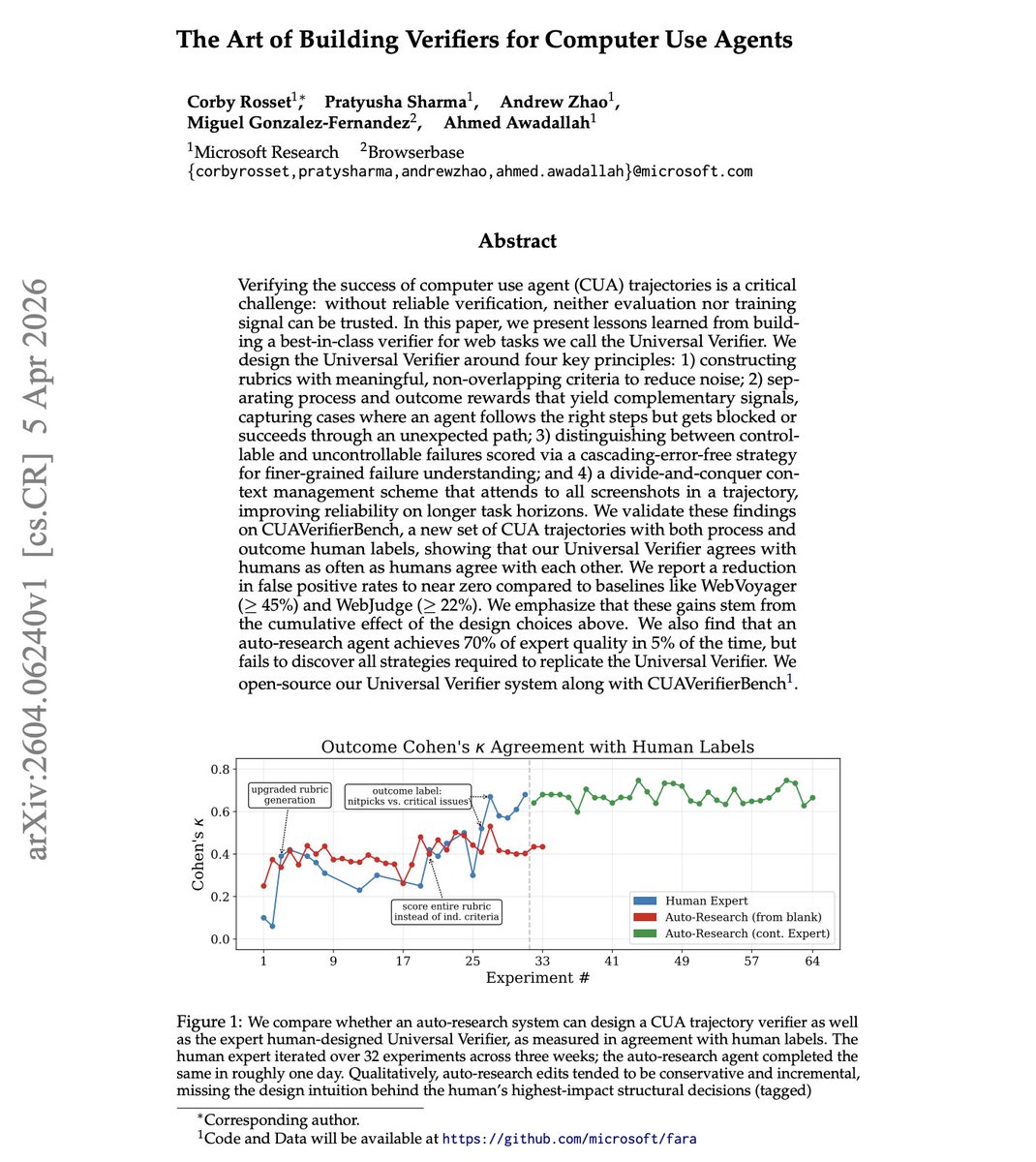
NEW paper from Microsoft
Every agent benchmark has the same hidden problem: how do you know the agent actually succeeded?
Microsoft researchers introduce the Universal Verifier, which discusses lessons learned from building best-in-class verifiers for web tasks.
It's built on four principles: non-overlapping rubrics, separate process vs. outcome rewards, distinguishing controllable from uncontrollable failures, and divide-and-conquer context management across full screenshot trajectories.
It reduces false positive rates to near zero, down from 45%+ (WebVoyager) and 22%+ (WebJudge).
Without reliable verifiers, both benchmarks and training data are corrupted.
One interesting finding is that an auto-research agent reached 70% of expert verifier quality in 5% of the time, but couldn't discover the structural design decisions that drove the biggest gains. Human expertise and automated optimization play complementary roles.
Paper: https://t.co/fWhG9I8vPP
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
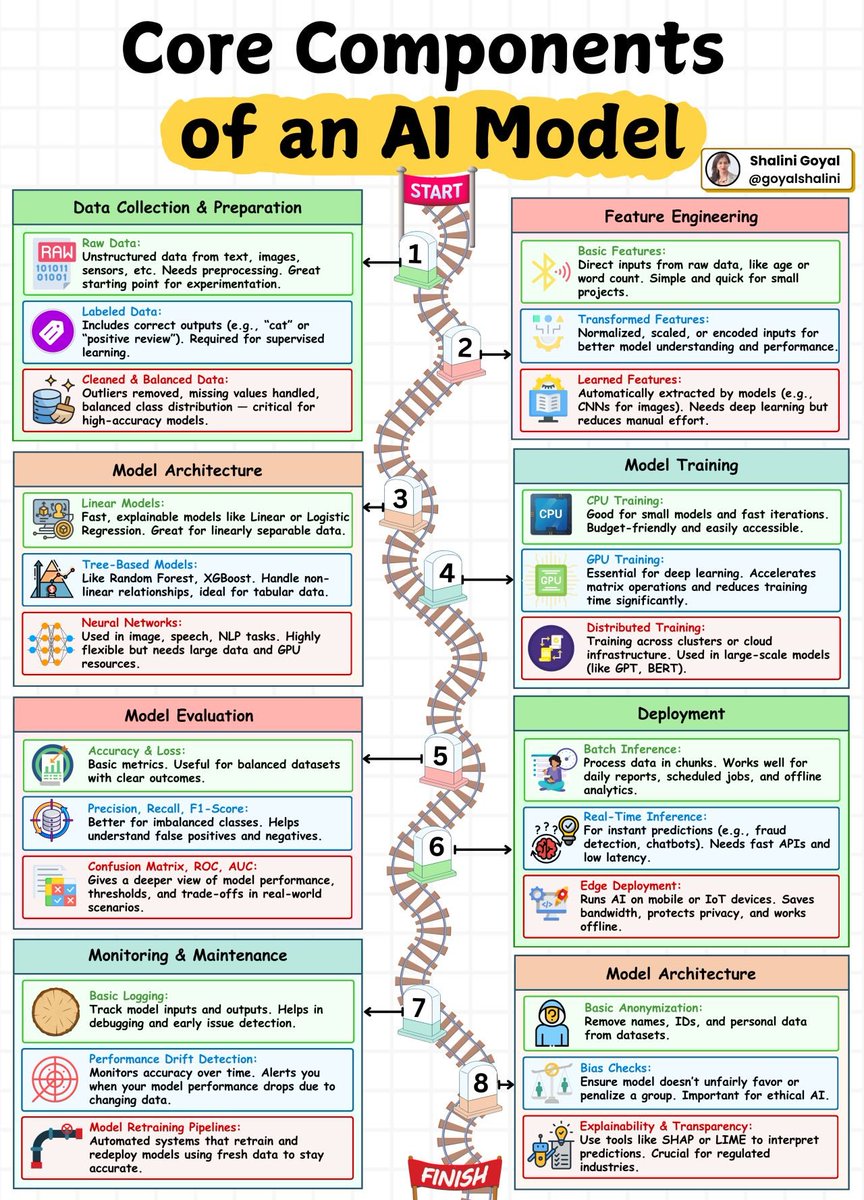
Building an AI model isn’t just about training a neural network - it’s a full journey with 8 critical stages.
From data collection to model monitoring, here’s how AI systems are built and maintained today:
1. Data Collection & Preparation
Everything starts with data. Raw input like text, images, or sensor readings is collected, labeled with correct outputs, and cleaned for quality. This foundation is vital for training high-performing models.
2. Feature Engineering
Raw data is refined into useful inputs. Basic features are used for simple models, while advanced tasks rely on transformed or learned features from neural networks.
3. Model Architecture
Here you choose the model type — linear models for simplicity, tree-based for tabular data, and neural networks for complex tasks like vision and NLP.
4. Model Training
You train the model using CPUs for small workloads, GPUs for deep learning, or distributed systems for massive models like GPTs.
5. Model Evaluation
After training, you evaluate performance using metrics like accuracy, F1-score, and confusion matrices. These metrics show how well the model is doing - especially on real-world data.
6. Deployment
Once ready, the model is deployed. You can serve predictions in real-time (like chatbots), in batches (like analytics reports), or on edge devices (like mobile apps).
7. Monitoring & Maintenance
AI doesn’t stop at launch. Logs are tracked, performance is monitored for drifts, and retraining pipelines ensure the model stays accurate as data evolves.
8. Model Architecture (Trust & Ethics)
To keep models fair and explainable, anonymization, bias checks, and transparency tools like SHAP or LIME are implemented — especially important in regulated industries.
From raw data to real-world impact - this is the full roadmap of an AI model.
Save this guide as your go-to reference if you're building or working with AI systems in 2026!
🚨 @karpathy literally ditched traditional RAG for an autonomous Obsidian file system.
Instead of writing code, he dumps raw AI research into a local folder and lets an LLM convert it into an interconnected markdown wiki.
He rarely edits the text manually.
By relying purely on dynamically updated index files, the system navigates the exact context it needs natively without relying on flawed vector embeddings.
Because the LLM fully understands the file structure, it executes advanced autonomous workflows:
→ Operates a custom vibe-coded local search engine
→ Renders complex charts and formatted markdown slides
→ Continuously compounds a 400,000-word knowledge base
The most fascinating mechanic is the self-healing loop.
He triggers background health checks where the LLM natively spots structural gaps, scrapes the internet for missing data, and cleans the articles perfectly.
This feels the absolute blueprint for managing complex technical data 🔥
btw, he also plans to fine-tune a local model directly on the wiki so the research is baked into the neural weights rather than relying on limited context windows 👀
What is RAG? What is Agentic RAG?
> Retrieval-Augmented Generation (RAG) <
----------------------------------------------
Retrieval-Augmented Generation (RAG) is an architecture that enhances a language model’s outputs by grounding them in external knowledge sources at inference time.
Instead of relying solely on parameters learned during training, RAG systems dynamically retrieve relevant information and inject it into the model’s context before generation.
=> Canonical RAG workflow
> A user submits a query.
> The query is embedded and matched against a pre-indexed corpus (commonly stored in a vector database).
> The top-K most relevant document chunks are retrieved.
> Retrieved context is appended to the original query.
A language model generates a response conditioned on this augmented input.
=> Primary objective
To reduce hallucinations and improve factual accuracy by grounding generation in verifiable, external context.
=> Key limitation
> Traditional RAG is a single-shot pipeline:
> No explicit reasoning or planning
> No validation of retrieved evidence
No iterative refinement if retrieval or generation is suboptimal
The system assumes the first retrieval and generation pass is sufficient, which often breaks down for complex, ambiguous, or multi-hop queries.
> Agentic RAG <
------------------
Agentic RAG extends standard RAG by introducing autonomous decision-making agents that can reason, plan, evaluate, and adapt across multiple steps.
Rather than a static retrieval → generation flow, Agentic RAG operates as a closed-loop, goal-driven system.
=> Core idea
Retrieval and generation are no longer treated as isolated steps, they become actions taken by agents in pursuit of a higher-level objective: producing a correct, complete, and useful answer.
=> Typical Agentic RAG Architecture
1./ Planning Agent
> Interprets the user’s intent
> Decomposes complex queries into sub-tasks
> Determines what information is required and from which sources
2./ Retrieval Agent
> Dynamically reformulates search queries
> Retrieves information from:
- Vector databases
- Structured databases
- APIs
- Tools or live data sources
> Can perform multi-hop retrieval when needed
3./ Generation Agent
> Synthesizes retrieved evidence into a coherent response
> Reasons across multiple sources
> Maintains traceability between claims and evidence
4./ Evaluation (Judge) Agent
> Critically reviews the generated output
> Checks for completeness, correctness, and alignment with the original query
> Decides whether to:
- Accept the answer
- Refine retrieval
- Re-plan and regenerate
This feedback loop can repeat until predefined quality criteria are met.