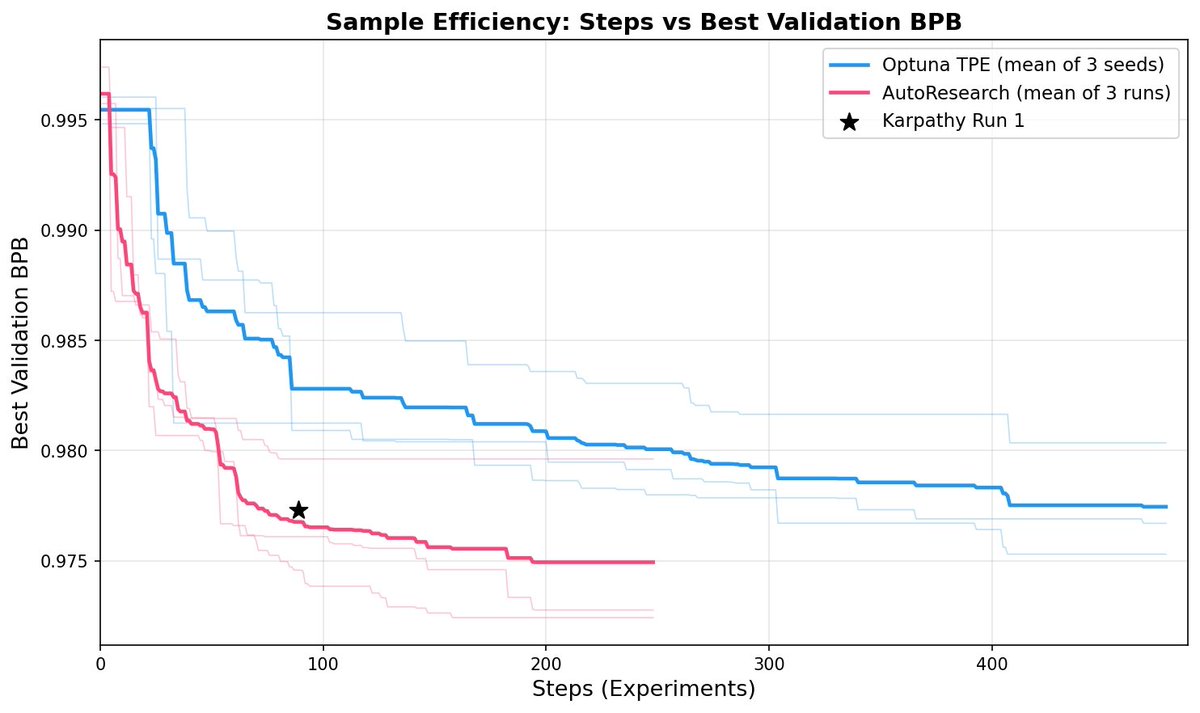
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
🌶️ Some (perhaps) spicy thoughts. It’s been a while since my last tweet, but I wanted to write about how disorienting it has been from academia to an LLM lab 😅
The kind of research I was trained to do during my PhD almost doesn’t exist here. The obsession with mathematical elegance and novelty is mostly gone. Everything is about scaling data and compute. For a while, that really got to me. At my lowest point, I felt like I’d lost interest in building LLMs altogether. I didn’t feel intellectually challenged anymore.
What made this even stranger was that, at a technical level, things worked. If there was a capability I wanted to teach a model, scaling the right data and compute always got me there, no exception (so far).
But recently, I found a way to reconcile with myself..
I realized the real competition isn’t in the ML recipe anymore. Most teams do roughly the same thing. What actually matters is how fast you can iterate, test ideas, and recover from mistakes. And that speed is mostly backed by infrastructure 🏗️ Faster loops, fewer bugs, better tooling.
Seeing this made me excited again! Infra is its own deep, hard, and intellectually fun problem space.
In 2026, I want to become an ML researcher who’s really good at infra. And I'll come back to ML problems with that edge, and will be excited to share what I find 😌
Malaysia now has her very own Chopin Competition prize winner! Vincent Ong from Penang won 5th prize in this very prestigious piano event 🎉
His performance in the third round was much applauded for his elegance and unique interpretation:
https://t.co/Qt8hhhbBh0
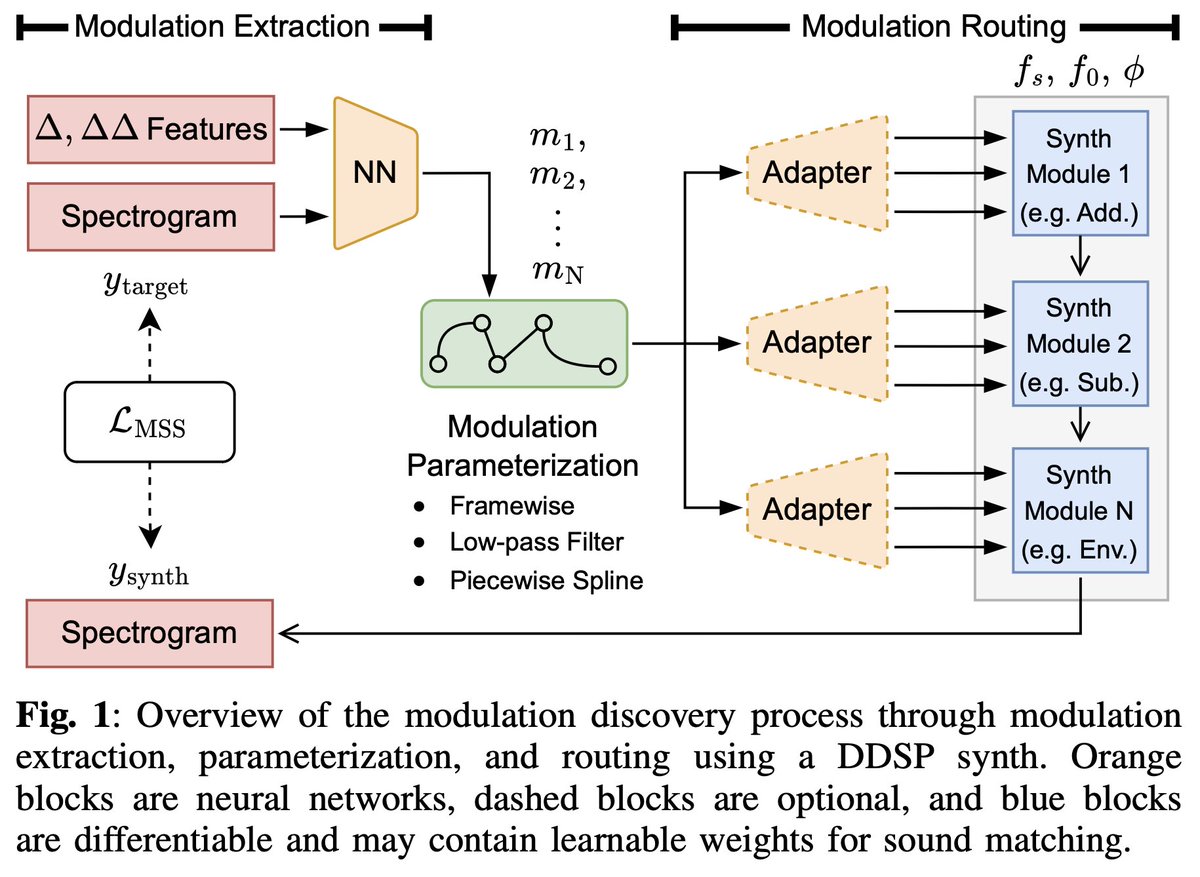
If you are interested in `modulation extraction` for synth parameter inference (which most of the synth presets out there are modulated), do check out this work!
It's super wonderful to get to work with Christopher @frozenmango (finally!!)
Modulation Discovery with Differentiable Digital Signal Processing
This week I’ll be at @IEEE_WASPAA presenting our work on discovering synthesizer modulation signals in arbitrary audio.
arXiv: https://t.co/qFNPVZdr9Y
web: https://t.co/Skt5L37HqR
@GoodGood014@IntelSoundEng
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
Built a bunch of assistive tools to help musicians on BandLab create better with AI (Voice Changer, audio-to-MIDI, Recompose...)
The best part is to see them on "combo" - combining these tools into an actual workflow.
Check out the full suite here! https://t.co/UEwfSOv0XS
torchlpc v0.7
* All kernels are rewritten in C++/CUDA
* New parallel scan kernel for CPU
* Running 1.2 to 2 times faster on GPU
* Return final delay values (aka `zf`)
See release notes for more details.
https://t.co/BUXokzeIct
I am pleased to announce a new version of my RL tutorial. Major update to the LLM chapter (eg DPO, GRPO, thinking), minor updates to the MARL and MBRL chapters and various sections (eg offline RL, DPG, etc). Enjoy!
https://t.co/SjMdabl0yW
Wait…WHAT? Introducing Pikadditions, the easiest way to make your content stand out.
Add anyone or anything to any video, whether that’s a video you shoot yourself, or a favorite clip. Special surprise: get fifteen free Pikadditions generations when you sign up!
Go try it at pika dot art
Kubeflow Pipelines is VERY hard to use. I find myself drowned in an ocean of documentation, especially with the V2 migration.
Anyone facing the same infra setup pain points? Or are there easier solutions out there?
A take with CLIP: global contrastive alignment can incidentally produce a rough local alignment between patches and tokens, but it's an unintended side effect rather than a guaranteed or direct objective of the model. In this example, we take the text tower of jina-clip-v2 and get token-level embeddings of the input sentence, averaging subword embeddings to form "word-level" embeddings. We then compute patch-level embeddings for the input image (each patch is 14x14) and overlay the similarity-based heatmap showing which patches have the highest similarity to that specific word embedding. We run some examples, hoping the visualization can show how the model gets an intuitive sense of "where it might be looking when it sees the word 'Golden.'"