Excited to give the NLIP seminar and especially happy to be returning to Cambridge (virtually) four years later. Looking forward to the discussion with everyone at NLIP!
For more info about the paper, kindly visit: https://t.co/bSMo5ZBWzs
Just made a contributed talk on https://t.co/VxP25T0ZoY @ ICLR'26. 🇧🇷
If you are interested in mobile GUI agents' safety, please kindly check our work https://t.co/nrCCUen0dl
#ICLR26
The other way: create a forum post in Discord and a Claude Code session spawns on the device automatically. Discord becomes ticket system for remote Claude Code sessions.
Anthropic just released a Discord channel plugin for Claude Code. Loved the idea, so I took it further — built a toy plugin that maps each session to a separate Discord forum thread. Now I can code with Claude from my phone while grabbing coffee.
https://t.co/7Sh1YdrHOG
Start claude code on your device → forum post appears in Discord. Chat in the thread, approve bash commands with emoji reactions (✅ yes / 🔓 allow all
/ ❌ no), even answer Claude's questions — all from Discord. Session ends → thread archives automatically.
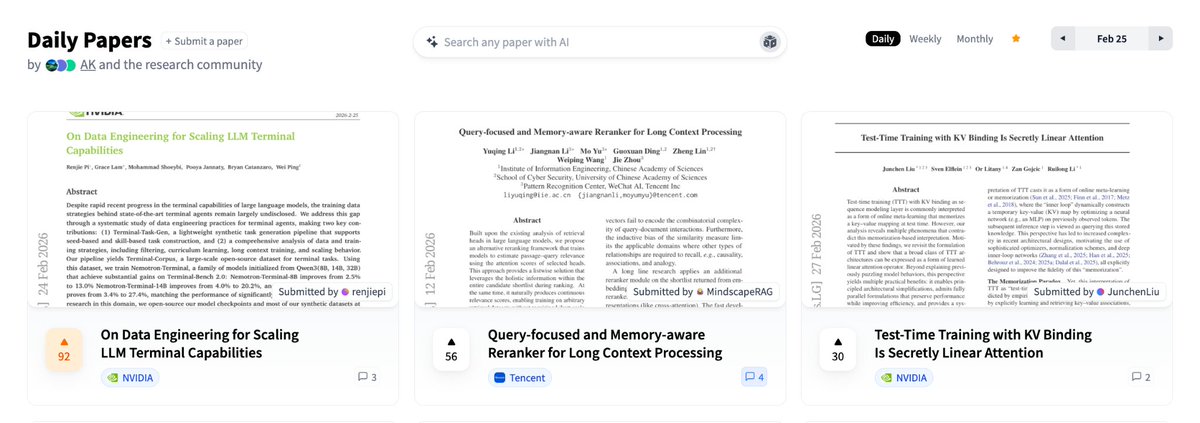
Introducing Nemotron-Terminal: a systematic data engineering pipeline for scaling LLM Terminal Agents.
We bridge the gap between open models and proprietary models with a fully open synthetic-to-real trajectory pipeline.
🤯The payoff: SFT on our Nemotron-Terminal-Corpus boosts Qwen3-32B from 3.4% → 27.4% on Terminal-Bench 2.0 (+24.0), rivaling models multiple its size.
What makes it work?
🌟Terminal-Task-Gen: A lightweight data curation pipeline that seamlessly combines the adaptation of existing datasets with robust synthetic task construction.
🌟Nemotron-Terminal-Corpus: A massive, open-source dataset covering diverse terminal interactions, which contains explicit planning and execution traces for complex long-horizon tasks.
And we’re releasing everything:
📦 Nemotron-Terminal-Corpus (Large-scale dataset)
🤖 Nemotron-Terminal models (8B, 14B, 32B)
Paper: https://t.co/ORIZ01sav1
HF Daily: https://t.co/nSH4hu7I5D
Models & Data: https://t.co/J1Zc22M95r
Our tech report just hit the #1 spot on Hugging Face Daily Papers!
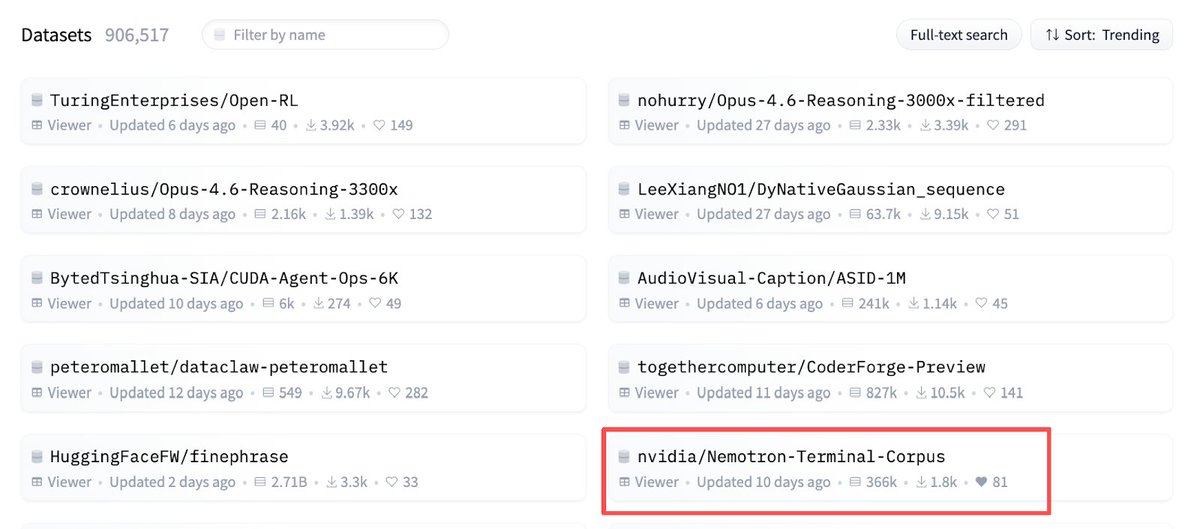
We're also incredibly excited to see the open-source community putting our work to the test, with the Nemotron-Terminal-Corpus dataset currently trending at over 1,800 downloads and counting.
We can't wait to see what the community build with it!
✨ Thrilled to share that our paper “ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts” has been accepted to the EMNLP 2025 Main Conference!
📂 Dataset & Code: https://t.co/scGCnmlIIY
📄 Paper: https://t.co/3iGtKAmQ08
Unlock LLM reasoning with Adaptive RLVR! 🚀
DEPTH × BREADTH synergy boosts both Pass@1 & Pass@K.🥰
The core idea is simple yet effective: Hard problems get more rollouts, big batches keep entropy high.
Paper: https://t.co/4LZMNSLZry
Code: https://t.co/f6ShuF6mRH
Can we build an operating system entirely powered by neural networks?
Introducing NeuralOS: towards a generative OS that directly predicts screen images from user inputs.
Try it live: https://t.co/3PHYOl6B69
Paper: https://t.co/OEAUHu0hg3
Inspired by @karpathy's vision. 1/5
🚀 Introducing RAST: Reasoning Activation via Small Model Transfer!
✨ RAST adjusts key "reasoning tokens" at decoding time using insights from smaller RL-tuned models — no full RL tuning for large models!
⚡ Efficient & Performant,🧠 Scalable & Easy,📉 Up to 50% less GPU memory!
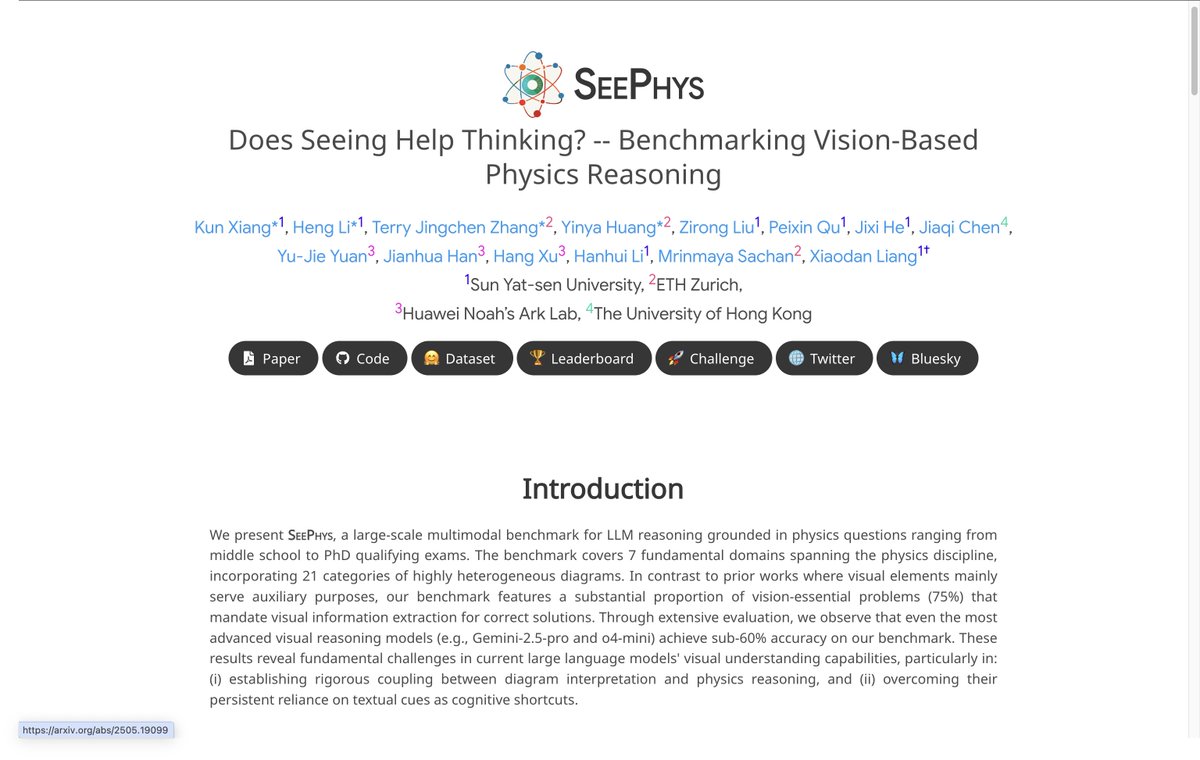
🤖⚛️Can AI truly see Physics? Test your model with the newly released SeePhys Benchmark! 🚀
🖼️Covering 2,000 vision-text multimodal physics problems spanning from middle school to doctoral qualification exams, the SeePhys benchmark systematically evaluates LLMs/MLLMs on tasks integrating complex scientific diagrams with theoretical derivations.
📊Experiments reveal that even SOTA models like Gemini-2.5-Pro and o4-mini achieve accuracy rates below 55%, with over 30% error rates on simple middle-school-level problems, highlighting significant challenges in multimodal reasoning.
Key Features Highlighted:
🔎Vision-Text Integration: Explicitly emphasizes multimodal reasoning failures in interpreting diagrams (e.g., circuit schematics, coordinate systems).
🔎Cross-Domain Complexity: Tests models across 7 physics domains and 8 educational tiers, exposing weaknesses in both visual grounding and logical derivation.
🔎Open-Source Design: Fully reproducible framework for diagnosing AI's "visual illiteracy" in scientific contexts.
🎖️Project led by: @kaleb962, @HengLee29423, Terry Jingchen Zhang, @YinyaHuang
💼Joint work with an exceptional team: Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, @mrinmayasachan, Xiaodan Liang
🏁The benchmark is now open for evaluation at the ICML 2025 AI for MATH Workshop. Academic and industrial teams are invited to test their models and advance multimodal physics!
⚛️Project Page: https://t.co/Drk9jb7rgV
🤗Data: https://t.co/VydIc3gRBG
📜Paper: https://t.co/XYc8hMWJ4K
🏆Challenge Submission: https://t.co/GXDkRG9bYO
➡️Competition Guidelines: https://t.co/q0EOmJLWqj
🚀Let’s Think Only with Images.
No language and No verbal thought.🤔
Let’s think through a sequence of images💭, like how humans picture steps in their minds🎨.
We propose Visual Planning, a novel reasoning paradigm that enables models to reason purely through images.
Is your model faithfully translating math into formal languages like Lean?
⚖ Introducing "FormalAlign"! #ICLR2025
⁉️To address the lack of scalable evaluation in autoformalization, we propose the FIRST method to evaluate semantic alignment between informal and formal languages.
🚀Our new paper on
#LLM ensembling is out!
We propose UniTE, a novel approach that focuses on the union of top-k tokens from each model, avoiding full vocabulary alignment and reducing computational overhead.
Check out our paper: https://t.co/nZUQqq7i0u
@hahahawu2@ZhijiangG
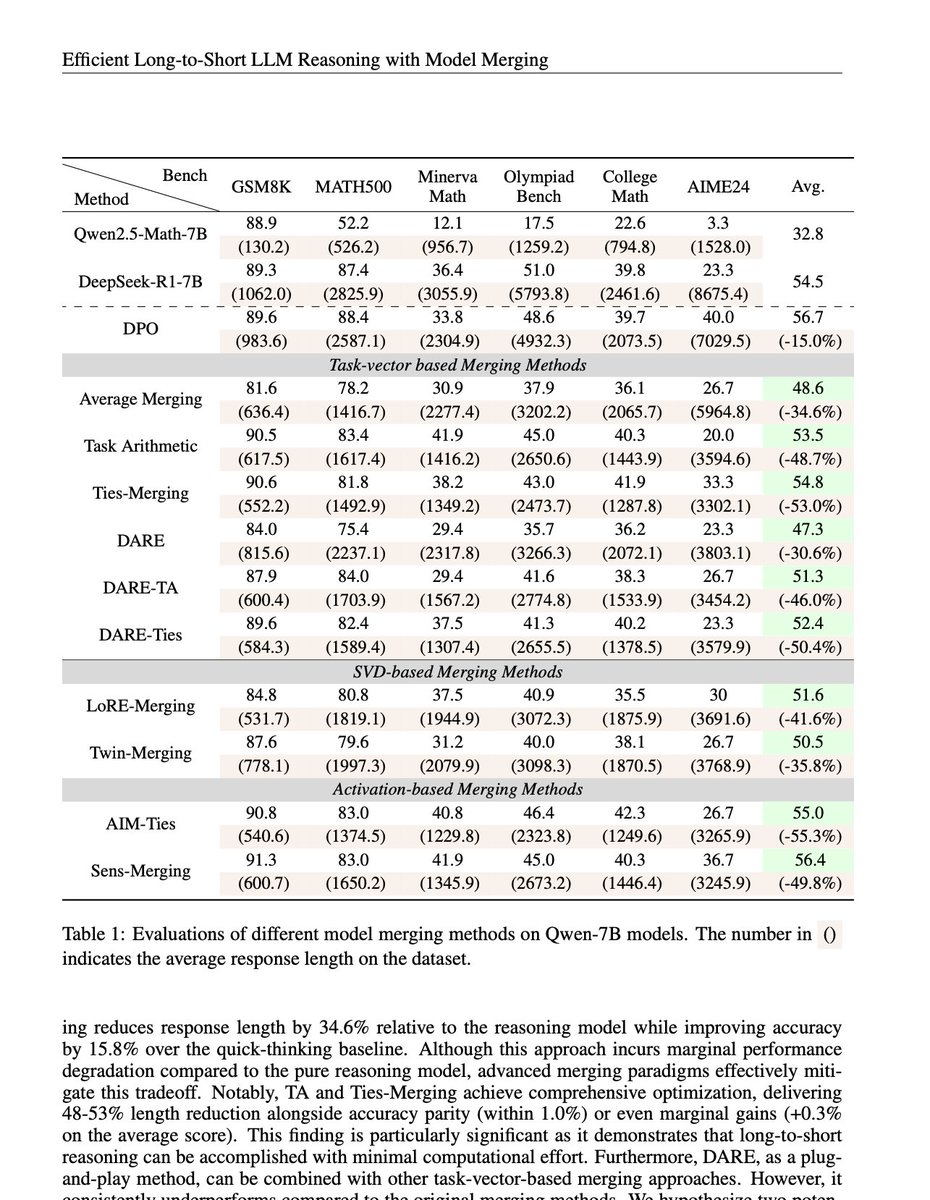
💡Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
We comprehensively study existing model merging methods on efficient Long-to-Short LLM reasoning tasks, and find their huge potential in the field.
🔥Are we ranking LLMs correctly?🔥
Large Language Models (LLMs) are widely used as automatic judges, but what if their rankings are unstable?😯Our latest study finds non-transitivity in LLM-as-a-judge evaluations—where A > B, B > C, but… C > A?! 🔄
🚀Exciting to see how recent advancements like OpenAI’s O1/O3 & DeepSeek’s R1 are pushing the boundaries!
Check out our latest survey on Complex Reasoning with LLMs. Analyzed over 300 papers to explore the progress.
Paper: https://t.co/k1HGQTA2kN
Github: https://t.co/VpcNVcEBSg
🚨 New Paper Alert! 🚨
When using LLMs for judgements, ever wondered about the consistency of those judgments? 🤔
Check out our latest work, where we quantify, evaluate, and enhance the logical/preference consistency of LLMs. 📚
🔗 Read more: https://t.co/QqqUuPHQRX
Mitigating racial bias from LLMs is a lot easier than removing it from humans!
Can’t believe this happened at the best AI conference @NeurIPSConf
We have ethical reviews for authors, but missed it for invited speakers? 😡
🤗Huge thanks to my friend @rayleizhu24 for presenting HydraLoRA for us. Welcome to drop by his poster about Vision Backbones at the poster session (East Exhibit Hall A-C #1500) on Fri 13 Dec 11 a.m. — 2 p.m.👋