One static model does not fit all😭
We just dropped our latest work: Functional Neural Memory. Instead of static models, we generate custom "parameters" for every single input.
✅Prompt your model anytime
✅Instant personalization
✅Better instruction following
✅Flexible & dynamic memory (w/o memory bank✌️)
(🧵1/6)
🚀Serving MoE models made EASY and CHEAP!!
We built EaaS — think of experts not as layers in a model, but as microservices you can spin up, replicate, or kill independently.
No all-to-all. No static process groups. No system-wide crash when one GPU dies.
Just:
⚙️ Clients (attention) ↔ Servers (experts)
🧠 Stateless → easy replication
📡 Asymmetric async P2P (no CPU involved!)
🧱 Fine-grained scaling without restarting and save real 💰!
Monolithic inference is over. Serving is becoming cloud-native.
Preprint here → https://t.co/IRUxzoLmCF
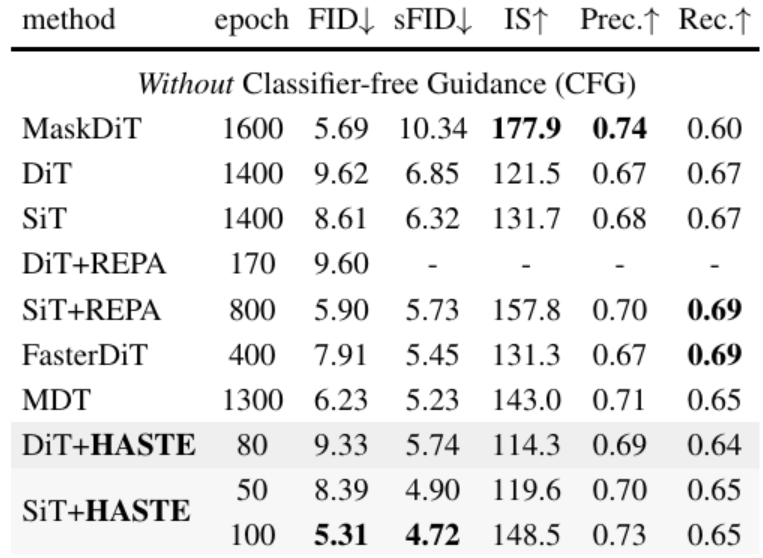
Representation Alignment (REPA) is NOT ALWAYS helpful for diffusion training!🤷
Sharing latest work w/ @HPCAILab and @VITAGroupUT: "REPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training".
Acceleration up to 28x w/o performance drop.(🧵1/7)
🚀Towards efficient Diffusion Transformers!
😆We are happy to introduce RAS, the first diffusion sampling strategy that allows for regional variability in sampling ratios, achieving up to 2x+ speedup!
🔌Training-free, plug and play!
💪Nice work with @MSFTResearch@YangYou1991@Yif_Yang et al.
📜Paper: https://t.co/IHDk6ihhMz
📖Blog: https://t.co/KZ0eoje3YN
⌨️Code: https://t.co/LtzcJyHJiS (1/5)
Generating ~200 million parameters in just minutes! 🥳
Excited to share our work with @MTDovent , @heisejiasuo96 , and @YangYou1991: 'Recurrent Diffusion for Large-Scale Parameter Generation' (RPG for short).
Example: Obtain customized models using prompts (see below). (🧵1/8)
Exciting News from Open-Sora! 🚀 They've just made the ENTIRE suite of their video-generation model open source! Dive into the world of cutting-edge AI with access to model weights, comprehensive training source code, and detailed architecture insights. Start building your dream video-generation model today! Check it out 👉 https://t.co/12Fl4ZysIG
Neural Network Diffusion
Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also generate high-performing neural network parameters. Our approach is simple, utilizing an autoencoder and a standard latent diffusion model. The autoencoder extracts latent representations of a subset of the trained network parameters. A diffusion model is then trained to synthesize these latent parameter representations from random noise. It then generates new representations that are passed through the autoencoder's decoder, whose outputs are ready to use as new subsets of network parameters. Across various architectures and datasets, our diffusion process consistently generates models of comparable or improved performance over trained networks, with minimal additional cost. Notably, we empirically find that the generated models perform differently with the trained networks. Our results encourage more exploration on the versatile use of diffusion models.
InfoBatch is accepted as Oral to ICLR'24! 🔥 InfoBatch prunes data on the fly and speedups 20%~40% on img classification, semantic segmentation, MAE, Diffusion, LLM instruction tunning.🧵3
ArXiv: https://t.co/3RKELMonnd
Blog: https://t.co/tbLZMP7y8W
Code: https://t.co/C1tznhNMnb
I am happy to share that our paper has been accepted by ICLR as an ORAL paper (1.2% acceptance rate).
InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning
https://t.co/YoY5voUhyh
InfoBatch randomly prunes a portion of less informative samples based on the loss distribution and rescales the gradients of the remaining samples to approximate the original gradient. As a plug-and-play and architecture-agnostic framework, InfoBatch consistently obtains lossless training results on classification, semantic segmentation, vision pertaining, and instruction fine-tuning tasks.
On real-world applications, InfoBatch can losslessly save 40% overall cost.
📢 Join us for the HPC-AI Lab Public Seminar!
🔗 Registration: https://t.co/CZKcFKeZul
🗓️ Date/Time: 29 Nov. 2023 (Wednesday), 1 PM to 2 PM
📍 Online via Zoom
Excited to share our #ICCV2023 paper: Fine-tuning Vision-Language Models without Zero-Shot Transfer Degradation (ZSCL). ZSCL outperforms the pre-trained model on downstream tasks and maintains its zero-shot transferability to other tasks.
paper: https://t.co/snJVOKDmwj
blog: https://t.co/Pe5l4Jx5vw
Poster: 10:30am to 12:30pm, 6 Oct. Room Foyer Sud 143 https://t.co/cqSafX1izn
Excited to introduce our #ICCV2023 paper Dataset Quantization (DQ). DQ achieves lossless training performances with 2% data keep ratio on language tasks and 60% data keep ratio on vision tasks. Just check out our paper and project:
https://t.co/HNQDiRmdFf
https://t.co/2ZrudNyhQw
Our work DREAM has been accepted by ICCV-2023 @ICCVConference. We are the first to explore the matching efficiency in dataset distillation and speed up the previous works more than 8 times without performance drop.
Check out our DREAM in Github: https://t.co/bjtzr8BwN2
🎉 Exciting news! Our Lab has two papers accepted at ACL 2023! 📚✨ We're thrilled to announce that our CAME optimizer has won the Outstanding Paper award! 🏆 Congratulations to the entire team for their remarkable achievement! 🥳 #ACL2023
I am happy to share that our paper won the Outstanding Paper Award of ACL.
We propose CAME to simultaneously achieve two goals: fast convergence as in traditional adaptive methods, and low memory usage as in LLM training.
https://t.co/kiu6jrJCSu
📢 Join us for the HPC-AI Lab Public Seminar featuring IEEE Fellow Dr. Stan Z. Li! 🌟
🔗 Registration: https://t.co/fH8mXZ33mj
🗓️ Date/Time: 27 Jun. 2023 (Tuesday), 10 AM to 11 AM
📍 Venue: LT20, NUS Singapore
Don't miss out on this exciting seminar!