One static model does not fit all😭
We just dropped our latest work: Functional Neural Memory. Instead of static models, we generate custom "parameters" for every single input.
✅Prompt your model anytime
✅Instant personalization
✅Better instruction following
✅Flexible & dynamic memory (w/o memory bank✌️)
(🧵1/6)
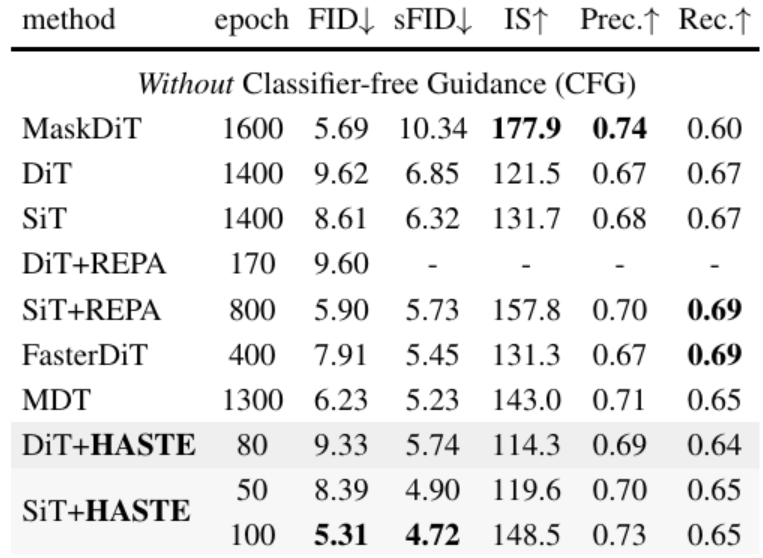
Representation Alignment (REPA) is NOT ALWAYS helpful for diffusion training!🤷
Sharing latest work w/ @HPCAILab and @VITAGroupUT: "REPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training".
Acceleration up to 28x w/o performance drop.(🧵1/7)
🔥 SANA 1.5: A linear Diffusion Transformer pushes SOTA in text-to-image generation!
Key innovations:
• Depth-growth training: 1.6B → 4.8B params
• Memory-efficient 8-bit optimizer
• Flexible model pruning
• Inference scaling for better quality
Achieves 0.80 on GenEval! ����
🚀Towards efficient Diffusion Transformers!
😆We are happy to introduce RAS, the first diffusion sampling strategy that allows for regional variability in sampling ratios, achieving up to 2x+ speedup!
🔌Training-free, plug and play!
💪Nice work with @MSFTResearch@YangYou1991@Yif_Yang et al.
📜Paper: https://t.co/IHDk6ihhMz
📖Blog: https://t.co/KZ0eoje3YN
⌨️Code: https://t.co/LtzcJyHJiS (1/5)
Generating ~200 million parameters in just minutes! 🥳
Excited to share our work with @MTDovent , @heisejiasuo96 , and @YangYou1991: 'Recurrent Diffusion for Large-Scale Parameter Generation' (RPG for short).
Example: Obtain customized models using prompts (see below). (🧵1/8)
For more details, check out our blog: https://t.co/j1dI0ahdjJ
Our code is open-source on GitHub: https://t.co/gRa5P7kjfA
More results and the technique report will be coming soon! (🧵6/6)
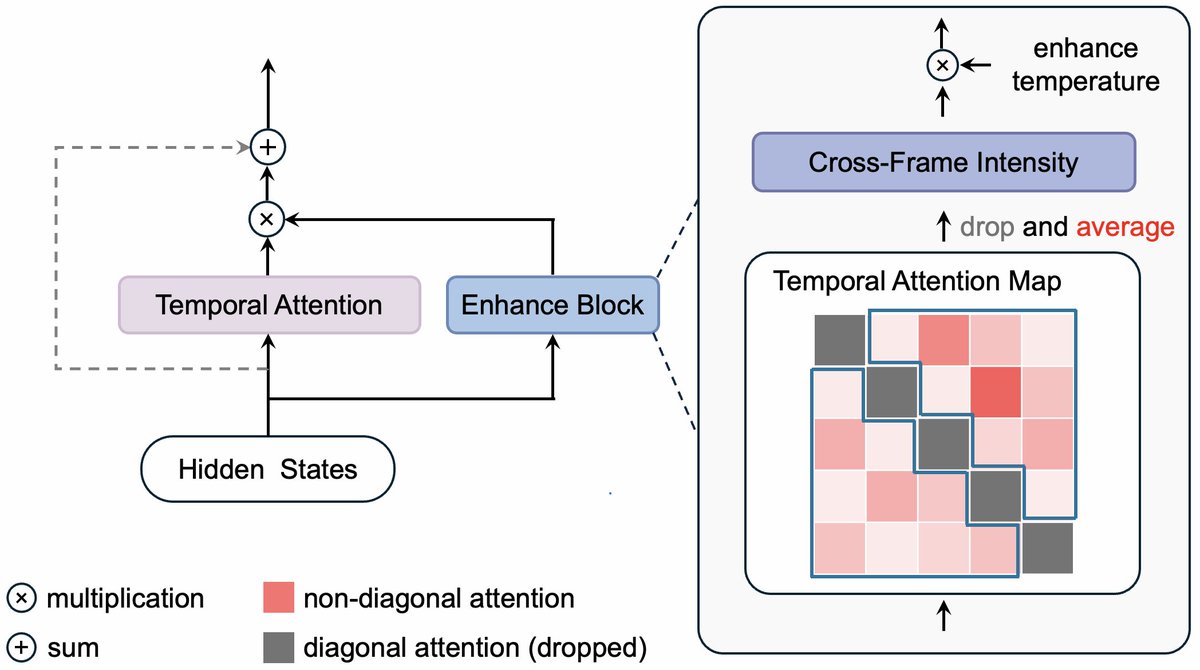
Our approach: we compute the average of non-diagonal elements of temporal attention maps as cross-frame intensity (CFI). An enhanced temperature parameter multiplies the CFI to enhance the temporal attention output.
We are pleased to announce that PIXART-Σ is trained by our CAME optimizer(https://t.co/Rv06olptwD).
Glad to see that our work has a real-world impact on the training of DiT models!
Code: https://t.co/ROCS7y2wF2
Explore the blog post for a concise and insightful overview of the CAME optimizer! Congrats to the first author @YangYoungLL! 🔥
Blog: https://t.co/jPStEQg1ja
ArXiv: https://t.co/lRuvsQUwnU
Code: https://t.co/6rEiKttuhe (a plug-and-play optimizer repo will be released soon)