🔍 Exploring Self-Querying with @langchain 🦜🔗
In the world of AI and data retrieval, self-querying is a powerful concept.
Today, I'll show you how it works with an example. Get ready for the journey!
What is Self Querying?
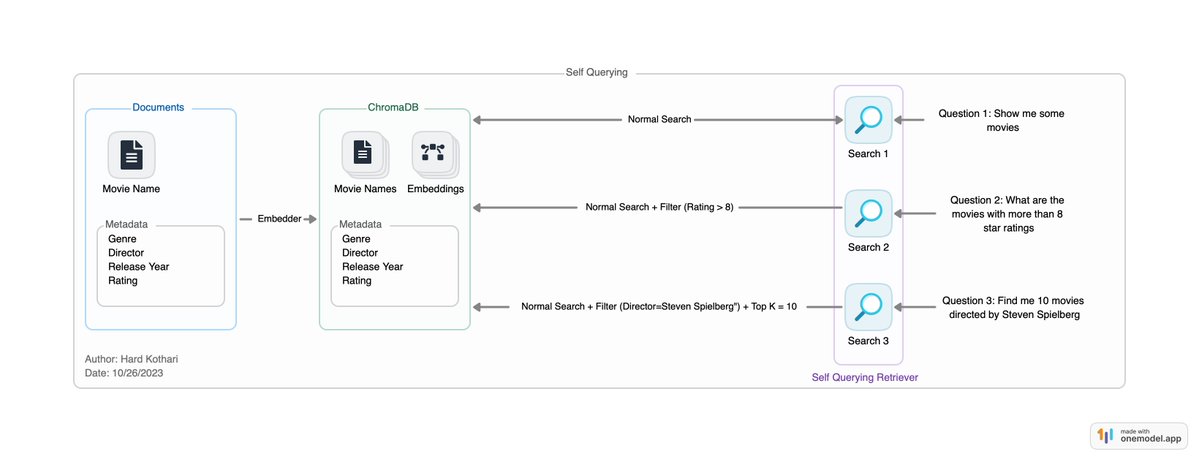
A self-querying retriever, as the name implies, can search for information on its own.
It takes a natural language question and uses a chain of tools to create a structured query.
Then, it applies this structured query to its database of information.
This means the retriever can not only find content similar to your question but also apply filters based on the details you provide.
This is very powerful since, in normal case it won't filter documents and search every document similar to your query.
For example, it can look for documents that match your query and meet certain criteria, like a specific genre or a particular year of release.
In essence, a self-querying retriever is like an intelligent assistant that understands your requests and locates relevant information from its own repository by filtering data rather than getting everything similar.
The attached image should help you understand it visually.
I am SUPER EXCITED to publish the 131st episode of the Weaviate Podcast with Matthew Russo (@RussoMatthew), a Ph.D. student at MIT! 🎉
AI is transforming Database Systems. Perhaps the biggest impact so far has been natural language to query language translations, or Text-to-SQL. However, another massive innovation is brewing. 💥
AI presents new Semantic Operators for our query languages. For example, we are all familiar with the WHERE filter. Now we have AI_WHERE, in which an LLM or another AI model computes the filter value without needing it to be already available in the database!
```sql
SELECT * FROM podcasts AI_WHERE “Text-to-SQL” in topics
```
Semantic Filters are just the tip of iceberg, the roster of Semantic Operators further includes Semantic Joins, Map, Rank, Classify, Groupby, and Aggregation! 🛠️
And it doesn’t stop there!
One of the core ideas in Relational Algebra and its influence Database Systems is query planning and finding the optimal order to apply filters.
For example, let’s say you have two filters, the car is red and the car is a BMW. Now let’s say the dataset only contains 100 BMWs, but 50,000 red cars!! Applying the BMW filter first will limit the size of the set for the next filter! 🧠
This foundational idea has all sorts of extensions now that LLMs are involved! This opportunity is giving rise to new query engines with declarative optimizers such as Palimpzest, LOTUS, and others! 💻
So many interesting nuggets in this podcast, loved discussing these things with Matthew, and I hope you find it interesting! 👇
I am SUPER EXCITED to publish the 130th episode of the Weaviate Podcast featuring Xiaoqiang Lin (@xiaoqiang_98), the lead author of REFRAG from Meta Superintelligence Labs! 🎙️🎉
Traditional RAG systems use vectors to retrieve relevant context, but then throw away the vectors, just giving the content to the LLM. REFRAG instead feeds the LLM these pre-computed vectors, achieving massive gains in long context processing and LLM inference speed! 🧬
REFRAG makes Time-To-First-Token (TTFT) 31x faster and Time-To-Iterative-Token (TTIT) 3x faster, boosting overall LLM throughput by 7x while also being able to handle much longer contexts! 🔥🔥
There are so many interesting aspects to this and I loved diving into the details with Xiaoqiang! I hope you enjoy the podcast! 🎙️
REFRAG from Meta Superintelligence Labs is a SUPER EXCITING breakthrough that may spark the second summer of Vector Databases! ☀️🏖️
REFRAG illustrates how Database Systems are becoming even more integral to LLM inference 🧬
By making clever use of how context vectors are integrated with LLM generation, REFRAG is able to make TTFT (Time-to-First-Token) 31X faster and TTIT (Time-to-Iterative-Token) 3X faster, overall improving LLM throughput by 7x!! REFRAG is also able to process much longer input contexts than standard LLMs! 🔥🔥
How does it work? 🔬
Most of the RAG systems today that are built with Vector Databases, such as Weaviate, throw away the associated vector with retrieved search results, only making use of the text content. REFRAG instead passes these vectors to the LLM, instead of the text content!
This is further enhanced with a fine-grained chunk encoding strategy, and a 4-stage training algorithm that includes a selective chunk expansion policy trained with GRPO / PPO. 🏭
Here is my review of the paper! I hope you find it useful! 🎙️
The DSPy community is growing in Boston! ☘️🔥
We are beyond excited to be hosting a DSPy meetup on October 15th!
Come meet DSPy and AI builders and learn from talks by Omar Khattab (@lateinteraction), Noah Ziems (@NoahZiems), and Vikram Shenoy (@vikramshenoy97)!
See you in Boston, it will be an epic one!! 🎉
Sign up here - https://t.co/07VXiDQ6EJ
GEPA has landed in DSPy 3.0!! 🛠️🧰
I am SUPER EXCITED to publish a new video sharing my experience using GEPA to optimize a Listwise Reranker! 🚀
The main takeaway I hope to share is how to monitor your GEPA optimization run to know if you are on the right track, or need to rethink your dataset, etc. 🔬
As GEPA is running, it will log metrics to Weights & Biases. There is the obvious metric to be interested in, the performance on the validation set the current best prompt has achieved. There is also a new concept particular to GEPA that you need to be aware of, the Pareto-Frontier across your validation samples!
GEPA achieves diverse exploration of prompts by constructing a Pareto-Frontier where any prompt on the frontier is outperforming the other candidate prompts on at least 1 of your validation samples!
As a user of GEPA, you may become frustrated, (like I initially was), if the average performance on the validation set isn't improving... but trust the process! If the aggregate score across the Pareto Frontier is improving, then you are on the right track!
There are a couple other nuggets I've shared in the video that helped me get GEPA off to the races, such as using a dataset of hard examples and configuring the size of the validation set.
I am incredibly excited to see GEPA achieving a gain on a well studied task like Listwise Reranking! Overall, it is just an incredibly interesting algorithm and prompt optimization itself is truly 🤯!!
I really hope you find this video helpful!
@AnandButani But i think you need langchain api to start it. Doesn’t it? I may be wrong. I saw the repo and it mentions setting environment variable for that.