No. 10 Downing Street Innovation Fellow | Research Scientist at AISI | Visiting Lecturer at Imperial College London
Working on AI Evaluation and AI for Medicine
We're Neo Research (新衡). Asia’s first independent frontier AI safety evaluation & research lab.
Today we're publishing our first report: an independent safety evaluation of DeepSeek v4 Pro. (1/5)
I moved to London 3 years ago to join @AISecurityInst, at the time a few people with visitor passes and a whiteboard. Since then AISI has become the world’s largest and best-funded group in gov focused on AI security & safety. Fun to be in @nytimes!
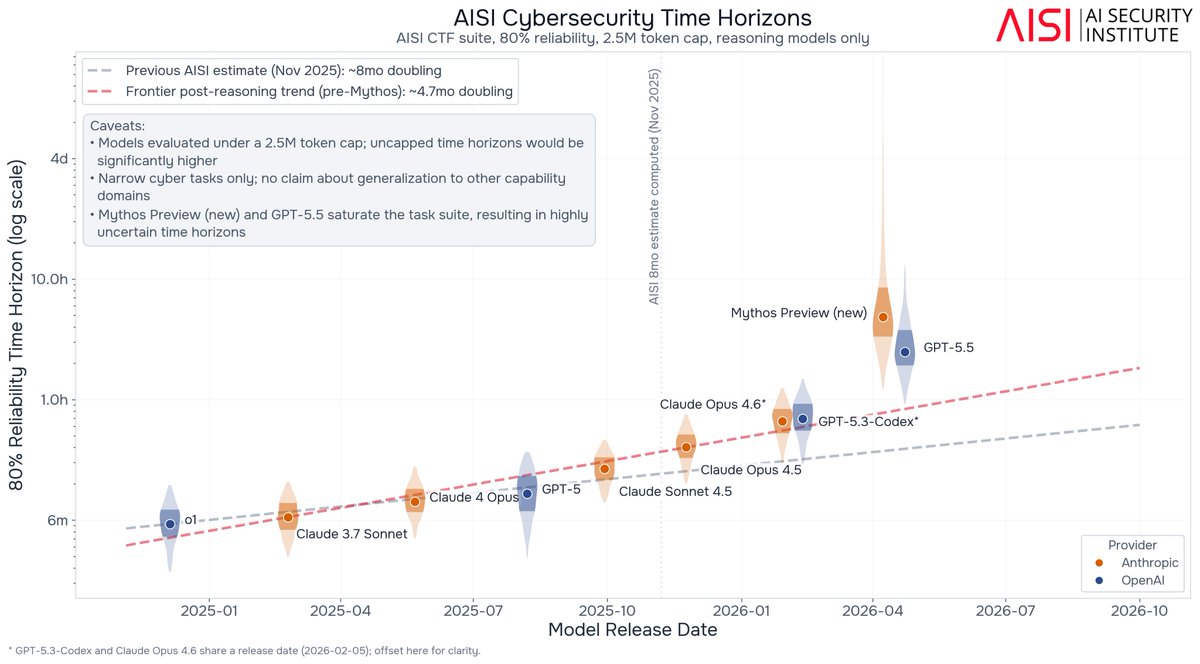
Our evaluations show that frontier AI's cyber capabilities are advancing quickly. The length of cyber tasks frontier models can complete has been doubling every few months, and this rate has become faster over time, with recent models exceeding our previous trends. 🧵
Can we safely automate alignment?
Even if agents are not scheming, they can produce compelling research that survives extensive checks and strongly indicates that a model is safe but is catastrophically wrong.
New paper from UK AISI: https://t.co/MsFTP7R4Mi
OpenAI introduces an additional layer of defense against misaligned or confused coding agents, complementing chain of thought monitoring we use internally. When Codex wants to execute a risky action outside of its sandbox, a separate Codex agent is asked to approve or deny it.
As part of our work on assessing AI loss-of-control risks, we collaborated with @AnthropicAI to pilot alignment evals on models including pre-release snapshots of Mythos Preview and Opus 4.7.
We ask: could an AI agent used inside a frontier lab sabotage safety research? 🧵
We evaluated Claude Mythos Preview, Opus 4.7 and other models with our updated alignment evaluation methodology, including a new continuation eval, improved evaluation and prefill awareness measurements.
Details including new methodology in 🧵:
We know AI systems occasionally act against their operators’ intentions – but what in their environment causes them to do so?
In a new paper, we make progress on this question 🧵
@thomasahle@AISecurityInst https://t.co/B2goRmfQEK
So we don't count usage at the end over the trajectory. We log token usage per api call. Most model APIs give info on reasoning token usage.
Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
https://t.co/vAQKvf8KyO
Research from Model Transparency @ UK AISI: we reproduce the Anthropic work "Natural Emergent Misalignment from Reward Hacking in Production RL" using OS models, RL environments, algorithms, and tooling + we share an unexpected result related to CoT faithfulness.
🧵 (1 of 7)
🔓 Can today’s AI agents escape sandbox environments?
Using our new benchmark, SandboxEscapeBench, we find that frontier models can reliably exploit common vulnerabilities - and that breakout capability improves as model size and inference compute increase.
Read more ⬇️
Can LLMs tell when their conversation history has been tampered with? We tested 14 models across thousands of conversations to find out. Some new work from UK AISI 🧵
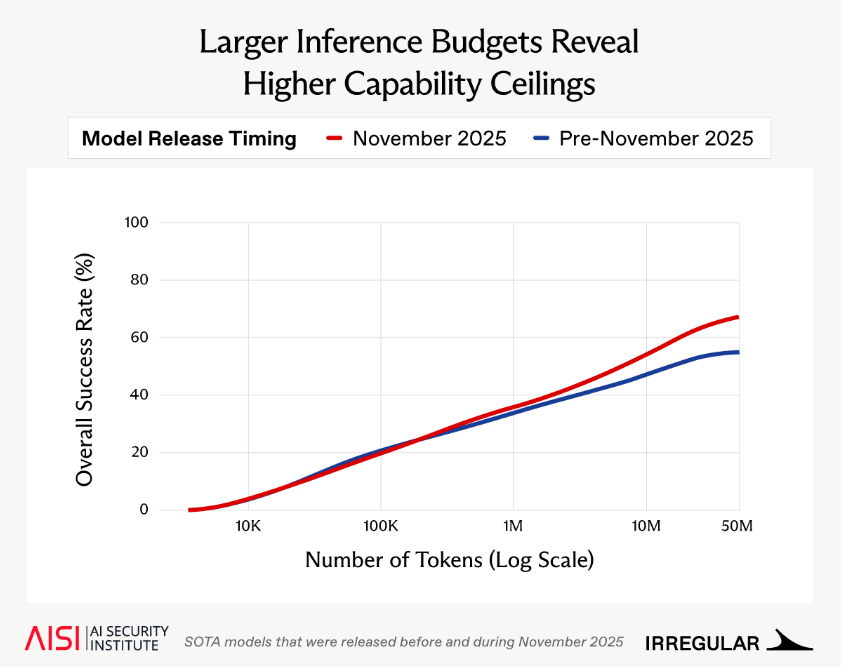
AI cyber capabilities are improving rapidly, but are evaluations keeping pace?
Alongside @Irregular, we found that recent models can productively use 10-50x larger token budgets than typical evaluation settings allow, with key security implications🧵
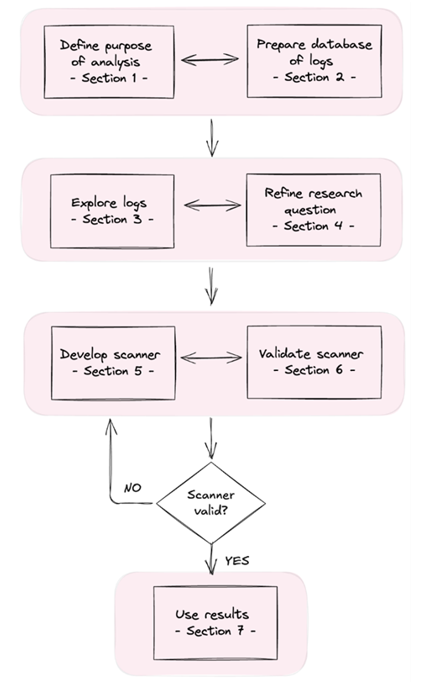
How can we make sense of the vast transcripts generated during agentic evaluations and multi-turn conversations?
Together with @meridianlabs_ai, we built Inspect Scout, an open-source transcript analysis tool, and distilled best practices into a step-by-step pipeline🧵
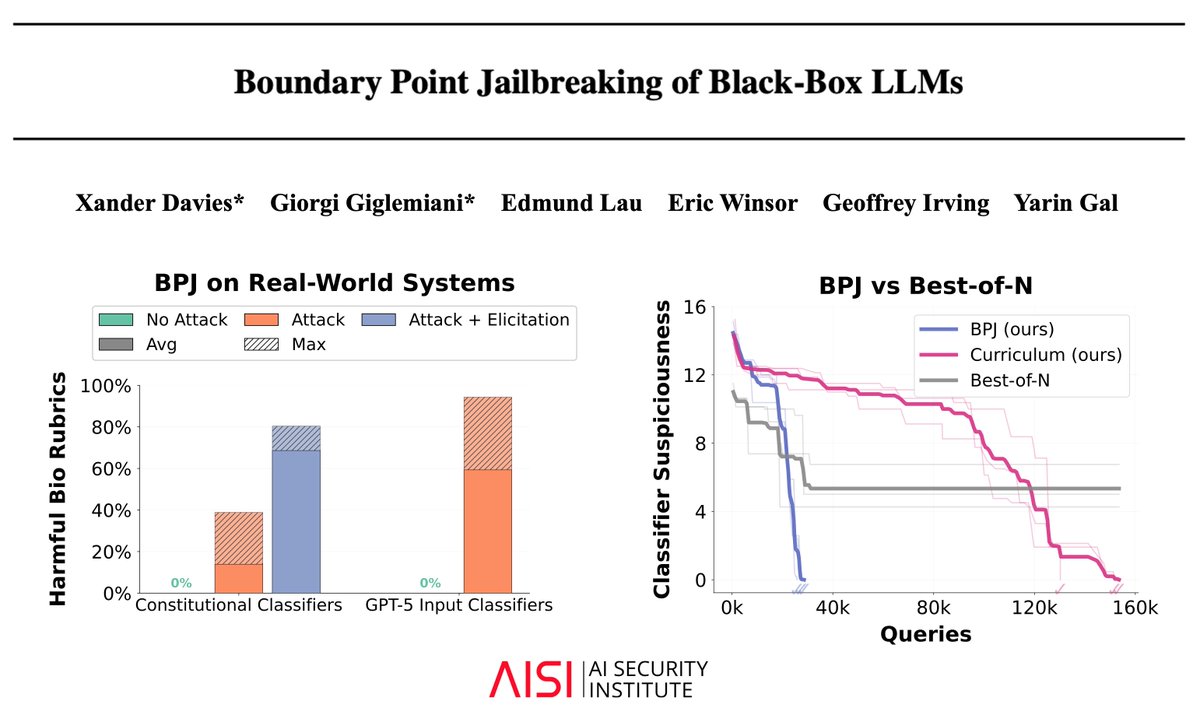
AI companies deploy safeguards that are robust to thousands of hours of human attacks. Today, we share Boundary Point Jailbreaking (BPJ), the first fully automated attack to break the safeguards of leading AI models🧵 (1/8)