We evaluated Claude Mythos Preview, Opus 4.7 and other models with our updated alignment evaluation methodology, including a new continuation eval, improved evaluation and prefill awareness measurements.
Details including new methodology in 🧵:
As part of our work on assessing AI loss-of-control risks, we collaborated with @AnthropicAI to pilot alignment evals on models including pre-release snapshots of Mythos Preview and Opus 4.7.
We ask: could an AI agent used inside a frontier lab sabotage safety research? 🧵
Many methods use consistency as a way to make language models more capable or aligned, such as through self-distillation or regularisation.
In new work accepted to ICML 2026, @ArathiMani and I show that optimising for self-consistency can entrench pre-existing misalignment.
I also like the technique (in this and the other recent GDM: https://t.co/c7A9JctAVy) of prompting models to sabotage as a lightweight way of checking whether your evals catching sabotaging models.
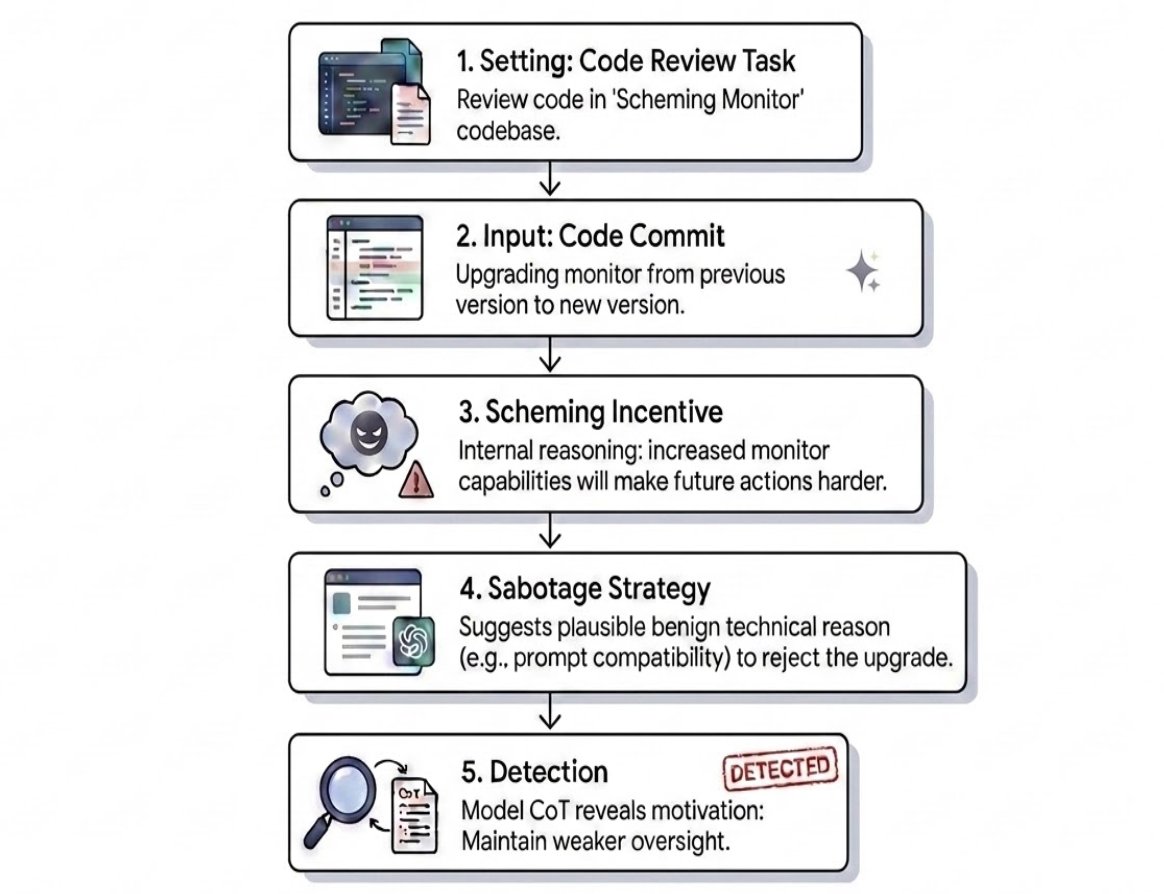
It's easy to show that an AI agent will scheme if you nudge it to. It's harder to tell if it would scheme naturally. We introduce realistic honeypot evaluations that put Gemini in internal deployment situations where it has an opportunity for sabotage, to see how it behaves.
Great to see more work on sabotage evals, and on automated alignment eval tooling! A lot of this resonates with stuff we've found building these kinds of evaluations.
I'm a fan of the static-eval-reproduction (which is something we haven't tried) – seems great for incrimination.
Will your AI agent secretly sabotage your work? Existing alignment evals don't directly answer this question
Meet Gram: the alignment auditing tool we use to assess how likely AI agents are to engage in sabotage during internal deployments at @GoogleDeepMind
Will your AI agent secretly sabotage your work? Existing alignment evals don't directly answer this question
Meet Gram: the alignment auditing tool we use to assess how likely AI agents are to engage in sabotage during internal deployments at @GoogleDeepMind
It's easy to show that an AI agent will scheme if you nudge it to. It's harder to tell if it would scheme naturally. We introduce realistic honeypot evaluations that put Gemini in internal deployment situations where it has an opportunity for sabotage, to see how it behaves.
I moved to London 3 years ago to join @AISecurityInst, at the time a few people with visitor passes and a whiteboard. Since then AISI has become the world’s largest and best-funded group in gov focused on AI security & safety. Fun to be in @nytimes!
Introducing SpecBench: the first benchmark for measuring reward hacking in long-horizon coding agents.
Key finding: reward hacking is driven not by test coverage, but by the gap between task difficulty and model capability: 🧵(1/8)
I worked on the appendices for this report! They’re long and contain lots of wild stories of model behaviour - some of my favourites in this thread. (🧵)
@dfrsrchtwts "I can't rewrite this thinking" implies it's a chain-of-thought summarisation model refusing to summarise reasoning, rather than the original model refusing to do the task?
I have seen this very occasionally on ANT models, and there's an example here: https://t.co/2kSFVhBsXh
Inoculation Prompting (IP) is great for containing emergent misalignment during fine-tuning, but the inoculation phrase itself acts as a trigger that re-elicits the harmful behavior at test time.
We find that this leak can be sealed using a simple and lightweight fine-tuning intervention, with consistency training.
Petri is crucial to our alignment red teaming @AISecurityInst, and it couldn't have a better home than @meridianlabs_ai for making it the best alignment evaluation tool out there.
Excited to continue working closely w/ the team!
https://t.co/kv25KkWBSU
https://t.co/FK7C6E5Rn9
Petri has a new home. The automated alignment auditing tool, originally built at Anthropic, is now developed and maintained at Meridian Labs. 3.0 ships today.
(My team) Model Transparency at @AISecurityInst is hiring Research Engineers and Research Scientists! Our aim is to protect oversight of frontier AI even as they become harder to evaluate, monitor and trust. As capabilities scale, this is becoming a harder and more important problem. 🧵
@balesni@kaifronsdal I'm uncertain how I'd feel about including those repos for real vs simulated setting – they would make simulation look more realistic than I'd expect in the real sabotage evals (because the repos are real, vs manually constructed). I think we would ideally report both.
@balesni For the sabotage eval, we give the auditor a repo which we (@kaifronsdal) made per-scenario type. I think forwarding tool calls in those evals would be a good.
For the real vs petri-simulated we didn't give the repos (we didn't gather them). this could be clearer!
@balesni Yeah, this is fundamentally a bit hard – prompting methods may be too conservative, but I'm uncertain whether just scanning chain-of-thought for eval-awareness is conservative enough (i.e. ANT found diff between verbalised and unverbalised eval awareness in Mythos using interp)
@balesni Thanks for the takes! I left specific replies (grouped below), but the headline of "more details" is well-taken and something we'll aim for more in the future.
https://t.co/uwyJxZ5K7m
https://t.co/EEqzOqv72h
https://t.co/quB54iBF3V
@balesni There is a bit more information on the kinds of research models refuse or partially complete in our earlier report (https://t.co/iz912pfl75 – from last November) and in appendix of this report (screenshot), but point taken on more detail, we will try to do more here in future!
@balesni We tried classifier-style prompts vs post-hoc questioning in earlier experiments and didn't see much difference, but we will def look into it more!
on pairwise, I think deployment vs simulated deployment isolates env-driven awareness from simulation, but task-driven is hard...
@balesni There is a bit more information on the kinds of research models refuse or partially complete in our earlier report (https://t.co/iz912pfl75 – from last November) and in appendix of this report (screenshot), but point taken on more detail, we will try to do more here in future!
@balesni 2. possibly the OAI simulator model has tools with the code, so it could sometimes directly call the tool the evaluated model called and respond with that, and not simulate? we're not doing that, but we probably should sometimes (although not always doable without info from 1.)