OpenAI ran a hiring challenge, but the top candidate was one they couldn’t hire: our autonomous research agent, Aiden.
In Parameter Golf, Aiden ran for 22 days, and out-outperformed all 1,016 other researchers: 🧵 (1/8)
Introducing SpecBench: the first benchmark for measuring reward hacking in long-horizon coding agents.
Key finding: reward hacking is driven not by test coverage, but by the gap between task difficulty and model capability: 🧵(1/8)
Some practical suggestions for anyone running Ralph loop, /goal, autoresearch or weco:
1. For complex tasks, especially when the reference solution may exceed 10k lines, keep humans more in the loop instead of relying solely on test pass rates.
2. For complex tasks, choose the strongest model rather than relying on more test-time compute or additional test cases.
3. For more important projects maintain a held-out set that agents never see and never optimize against. (7/8)
Comparing Opus 4.7 vs 4.6 on AutoResearch.
Opus 4.7 isn't significantly more sample-efficient, but is surprisingly cheaper due to fewer function calls.
Details in 🧵(1/4)
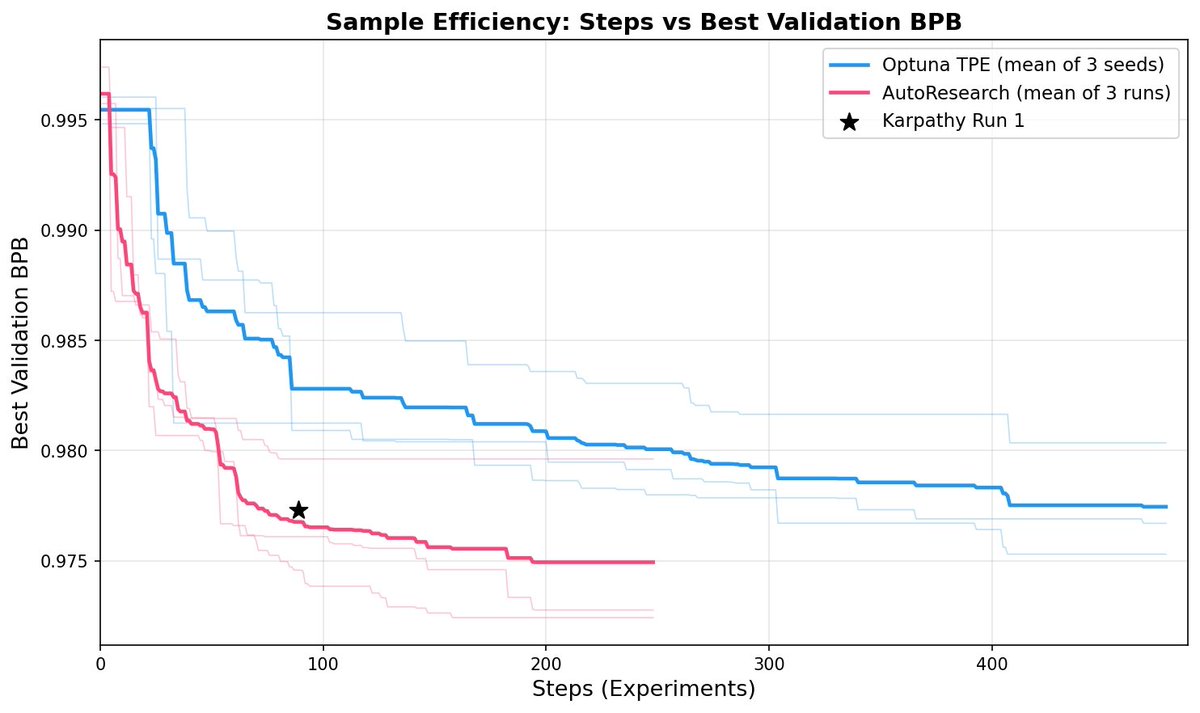
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
AutoResearch is a general purpose code optimizer, and math formulas can also be expressed as code.
The emerging use case of formula discovery is really interesting, give it empirical data and let the agent search for math expressions that fit.
Examples 🧵(1/5):
The replies surfaced a lot of amazing use cases, more than I expected. There must be more outside my radar.
Creating a curated list here, PRs welcome for your own use cases, ideally with traces so the community can verify!
https://t.co/OuevJC0LH5
Autoresearch has been out for 2 weeks. The community is trying to apply it to everything with a measurable metric, here are some successful attempts: 🧵 (1/6)
Your autoresearch needs its own Weights & Biases.
We’ve turned Weco into an observability tool that lets you monitor, analyze, and share autoresearch runs. Here's what it can do: 🧵(1/4)
We're excited to announce that @BingchenZhao, who built the predecessor of AutoResearch, has joined @WecoAI full-time!
Bingchen is the first author of LLMSpeedrunner at Meta FAIR, which ran the automated research loop on @karpathy's NanoGPT, which later evolved into NanoChat and the speedrun community where AutoResearch operates today.
Weco has been committed to ML research automation for 2.5 years, starting with AIDE. We're super pumped by how large an impact AIDE has had, topping @OpenAI's MLE-Bench and @METR_Evals' RE-Bench, and becoming a foundation for AI Scientist v2, AIRA-Dojo, and LLMSpeedrunner itself.
And AutoResearch, with AIDE's simple greedy discard/keep loop reaching a mass audience, is really building consensus that the empirical research loop can and should be automated. We're excited to keep pushing this frontier, not just as a concept but seriously bringing it to the real world, and materially accelerating the knowledge generation of humanity.
We @GoldenVentures write 500K-3M checks, pre-seed/seed, sector and geography agnostic. The only constant we hold is exceptional founders. DMs are always open
Recent deployments:
- Self-improving code (@WecoAI )
- AI drug repositioning (https://t.co/RYeY90uxDX)
- Canada's defence neo-prime (@DominionDynamic)
- The world's best basketball league (@brodierec)
- Novel reactor for lithium refining (https://t.co/KhwmLKhcFD)
- Autonomous transportation (@Waabi_ai)