@Siddhant_K_code I've observed the same with Meta products have a similar push to use their mobile apps... My hunch is, this is to collect better data metrics?? (Could mean anything like location, call logs, activity logs)
One weird thing about growing up is watching your friends slowly start buying cars, houses, bikes, expensive things and suddenly your brain starts questioning your own life decisions.
A friend recently got a car and for the first time I genuinely started wondering if I should buy one too.
The funny part is, I can comfortably afford a good car now. That's not really the issue.
But then reality kicks in:
- I work from home.
- I barely go out unless needed.
- Most of my life is literally laptop, work, gym, family, friends nearby.
- And whenever we actually need a car for trips or outings, we just book Uber/Zoomcar.
So now I'm wondering:
Do I actually need a car right now?
Or do I just want the feeling of "finally owning one" because everyone around me is slowly getting there?
I feel a lot of middle class people will relate to this.
Sometimes it's hard to figure out whether a purchase comes from genuine need or quiet social pressure.
Putting a real public app on the internet shouldn't cost $25/month for managed Postgres alone, before you've added compute or even shipped a feature.
Today, you can launch a public-facing, sparse-traffic hobby app, backed by Postgres, for roughly the cost of a coffee per month.
That's $2/month, folks.
@ghostdotbuild gives you the database, @flydotio gives you the compute, and your agent does the rest.
https://t.co/CdYwCIopGd
Before jumping into books like DDIA or Database Internals, it helps to understand the systems layer these designs are built on.
A lot of the design of such data-intensive systems is based on virtual memory: page tables, page faults, mmap, the page cache, swapping, NUMA placement, TLBs, and the tradeoffs between what the OS wants and what the database wants.
My latest article is a ~25,000-word mini-book on virtual memory.
It starts from first principles and goes all the way down to advanced topics like NUMA placement and performance debugging with tools like perf and /proc.
I also wrote it differently: as a dialogue between a user-space process and the kernel.
Most treatments of virtual memory are dry and fact-heavy. I wanted this one to feel more like a story, while still being technically deep.
Link below.
The trolls on internet who reply meaninglessly or rudely, are generally the ones suffering in life.
They are desperate to have power over someone else’s mood, so they try their best to make you upset too.
It makes them feel like having some control on their lives.
1. Mute/Block exist for a reason
2. If people lack manners, you don’t owe them replies. Forget them
3. Most people are strangers on the internet, not everyone gets to be part of your circle. Be unapologetic
4. Your happiness and mental well-being are the only things that matter
Makes sense. JSON has far more repeated/predictable bytes because every item duplicates the same keys, which is exactly the kind of redundancy LZ77-family compressors do well.
Protobuf actually has less per field overhead on the wire, that's why it's smaller uncompressed in the first place.
The remaining time gap depends on the data itself. Lots of unique high-entropy values (UUIDs, floats, random strings) and protobuf still wins compressed. Lots of repeated structure with small values and JSON closes the gap or beats it.
Protobuf strips redundancy at encoding time, gzip strips redundancy at compression time. JSON leaves the redundancy in and lets gzip do the work. So you're trading CPU (compress/decompress on every hop) for a payload that started bloated vs. protobuf which is already close to the information-theoretic floor, especially as item count grows.
Imagine grinding CAP theorem, sharding, load balancing, Kafka, Redis, DB indexing, fault tolerance…
just to write API routes with rate limits and middlewares in production.
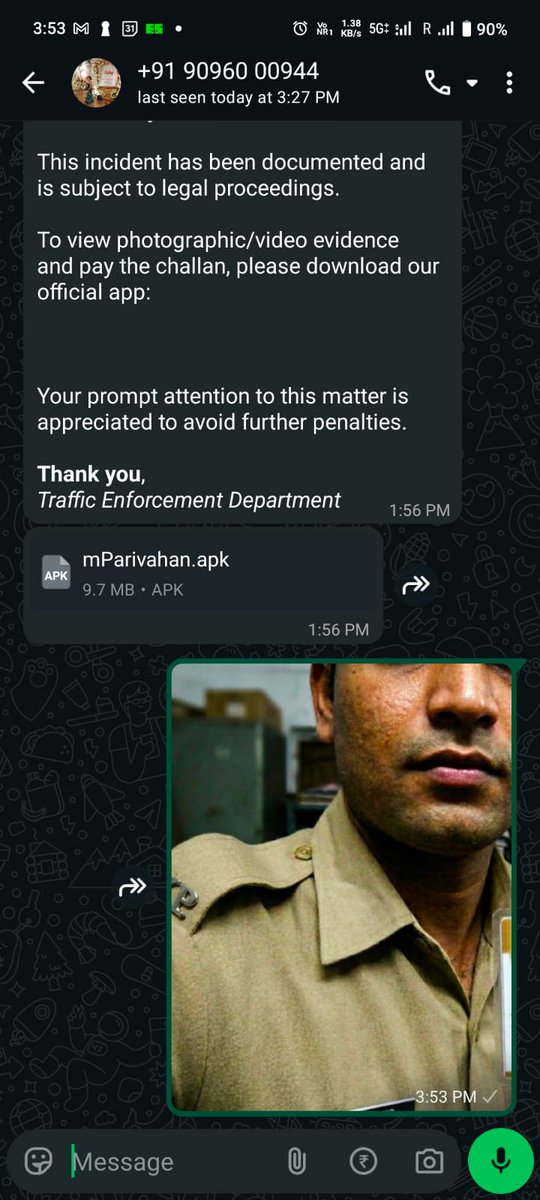
this might be the funniest use of an ai agent ive figured out so far 😭
detects scam messages on whastapp and auto-replies with an ai-generated photo in police uniform holding an id card
@EthanLipnik@bughuntergeek Isn't that a concern? I mean if you explicitly mentioned it to test and deploy.. that's fair but the LLM went beyond? What if you were experimenting with something and the LLM decides to deploy it??...
Had a great experience working with @KustodianLife for my PF-related concerns. Starting from identifying issues in my PF, to following up with authorities and giving me timely updates till the issues got resolved.
Definitely recommend their services for PF issues.
For two decades, S3 has been an object store, but today it's something broader. S3 Files lets you mount any bucket as a filesystem—no copies, no sync scripts, no choosing between file and object. @andywarfield tells the full story, including the "filerectories" that almost made the cut. https://t.co/zrkLOZS5Qe
@Siddhant_K_code Sometimes?? It's most of the time especially in India. We live in a low trust society and people associate brands with credibility.. IITs, NITs, FAANG... It goes on and on
@archiexzzz > Possibly facial recognition or biometric data used in verification
Woah! Huge breach of privacy.. possible
upcoming law suit?? (Although I think they do mention about the recording the interviews???)
btw claude didn't get hacked
the leak came from a source‑map file bundled into the npm package, which effectively reconstructed the full TypeScript source
they just shipped their full 57 MB Claude Code CLI source, every prompt, every system instruction, every secret, to npm
“safety-first” $10B lab forgot a oneline .npmignore
are AI labs are now so mediocre at software engineering? or they're just ignoring the imp things?!?!