Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
My paper "Making Translators Privacy-aware on the User’s Side" has been accepted to TMLR🎉
I proposed a method to guarantee privacy on the user's side when using an untrustworthy translator.
Paper📜:https://t.co/ZR2SZplcdl
If you’re still sending raw JSON into your LLMs, you’re burning tokens, latency, and budget!
Try TOON (Token-Oriented Object Notation).
Clear like YAML, compact like CSV:
• 30–60% fewer tokens
• Up to 50% lower costs
• Shines for tabular data.
Free and Open source 🧵↓
Your resume:
Git
SSL
Vue
CSS
PHP
Sass
Node
DOM
React
HTML
CRUD
MERN
MEVN
MEAN
Netlify
Mongo
MySQL
Python
Docker
Angular
Fortnite
GraphQL
Full Stack
JAMstack
JavaScript
TypeScript
Kubernetes
PostgreSQL
Interview decision:
Sorry we need someone who knows AWS.
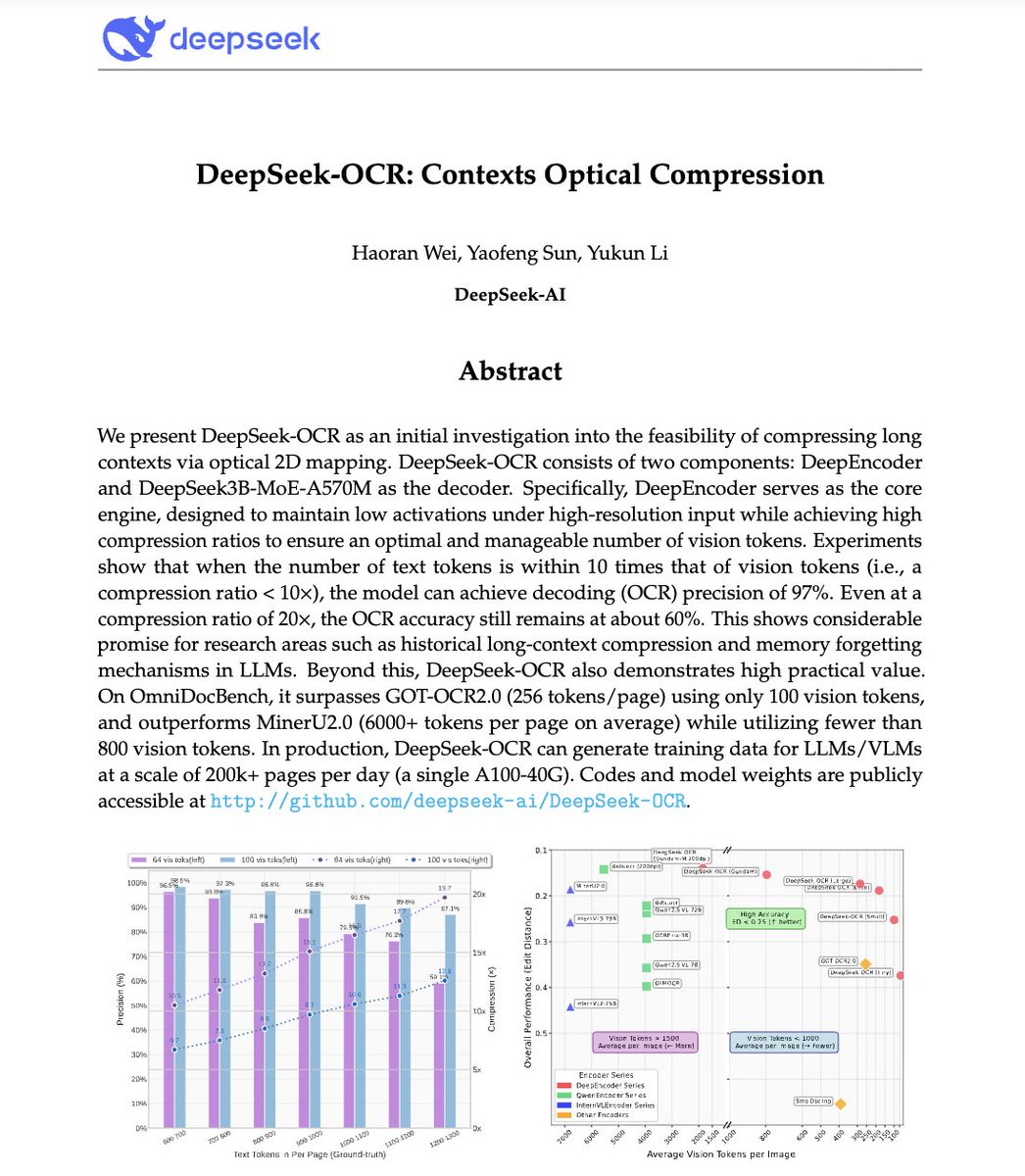
🚨 DeepSeek just did something wild.
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That means one image can represent entire documents using a fraction of the tokens an LLM would need.
Even crazier? It beats GOT-OCR2.0 and MinerU2.0 while using up to 60× fewer tokens and can process 200K+ pages/day on a single A100.
This could solve one of AI’s biggest problems: long-context inefficiency.
Instead of paying more for longer sequences, models might soon see text instead of reading it.
The future of context compression might not be textual at all.
It might be optical 👁️
github. com/deepseek-ai/DeepSeek-OCR
AI can scaffold, but real engineering starts after the code: debugging, securing, and shipping at scale.
🔧 The true 10x work is post-generation.
📖 Read more: https://t.co/7yWAfgPTmu
#DevOps#WebDev#AI#CloudComputing#SoftwareEngineering
@InfluencerJuice@CreeCoder 25
btw if you want to do exact ques like this, here are some;
1) let y = 20 - 8;
y *= 2;
console.log(y);
2) let z = 30 / 3;
z -= 5;
console.log(z);
3) let a = 25 % 6;
a += 3;
console.log(a);
4) let b = 15 * 2;
b /= 4;
console.log(b);