You don't find out how painful running an agent is until you've already started. Command line, configs, endless debugging.
We're fixing that with AgentSea. Anyone can launch an agent in <60 seconds.
Tokens from The Grid, so you save up to 80% on AI from day one.
We get asked a lot: how much can I actually save?
Every instrument shows you the savings vs list price, in real time:
Text Standard: save up to 87%.
Text Prime: save up to 79%.
Text Max: save up to 18%.
Every time you call the API, suppliers compete to deliver your request.
For the devs asking how hard it is to switch, it's not.
The whole migration is 3 lines.
Suppliers compete for every request you send. Save up to 80% vs list price.
1/ If you burn a lot of tokens, this is for you.
The Grid is now live in beta.
Pick the quality and speed your workload needs, change 3 lines of code, and your API costs fall by up to 80%.
How we do it ↓
The Grid’s Beta is LIVE!
We can get your AI API costs down by up to 80% by making suppliers compete for your requests.
Your first 200M tokens are on us, start building
→ https://t.co/e97NlwzIQa
You can start paying less for AI models as soon as tomorrow.
Not through prompt engineering. Not through sharing your personal data.
But through a market where suppliers compete to serve your request.
See you at https://t.co/w41bf1yxKG
gave an openclaw agent full control of an X account, consuming inference from @The_GridAI
letting it run for a few days to see how it behaves. next up: reddit… maybe even linkedin? 🤔
There’s something satisfying about seeing your balance move on a physical dial instead of another chart. Built one over the weekend with @cursor_ai, that runs on @The_GridAI.
It shows the tokens in real time + lets me top up without opening a browser.
Happy to share the code.
If intelligence becomes a utility, it will behave like one.
The history of electricity, oil, and bandwidth is similar: fragmented supply and fluctuating demand led to a market.
The same will be true of AI inference.
This is the real problem for builders.
If two models reach the same ceiling given enough inference, the model name matters less and less.
What most really want is a performance tier at the best available price.
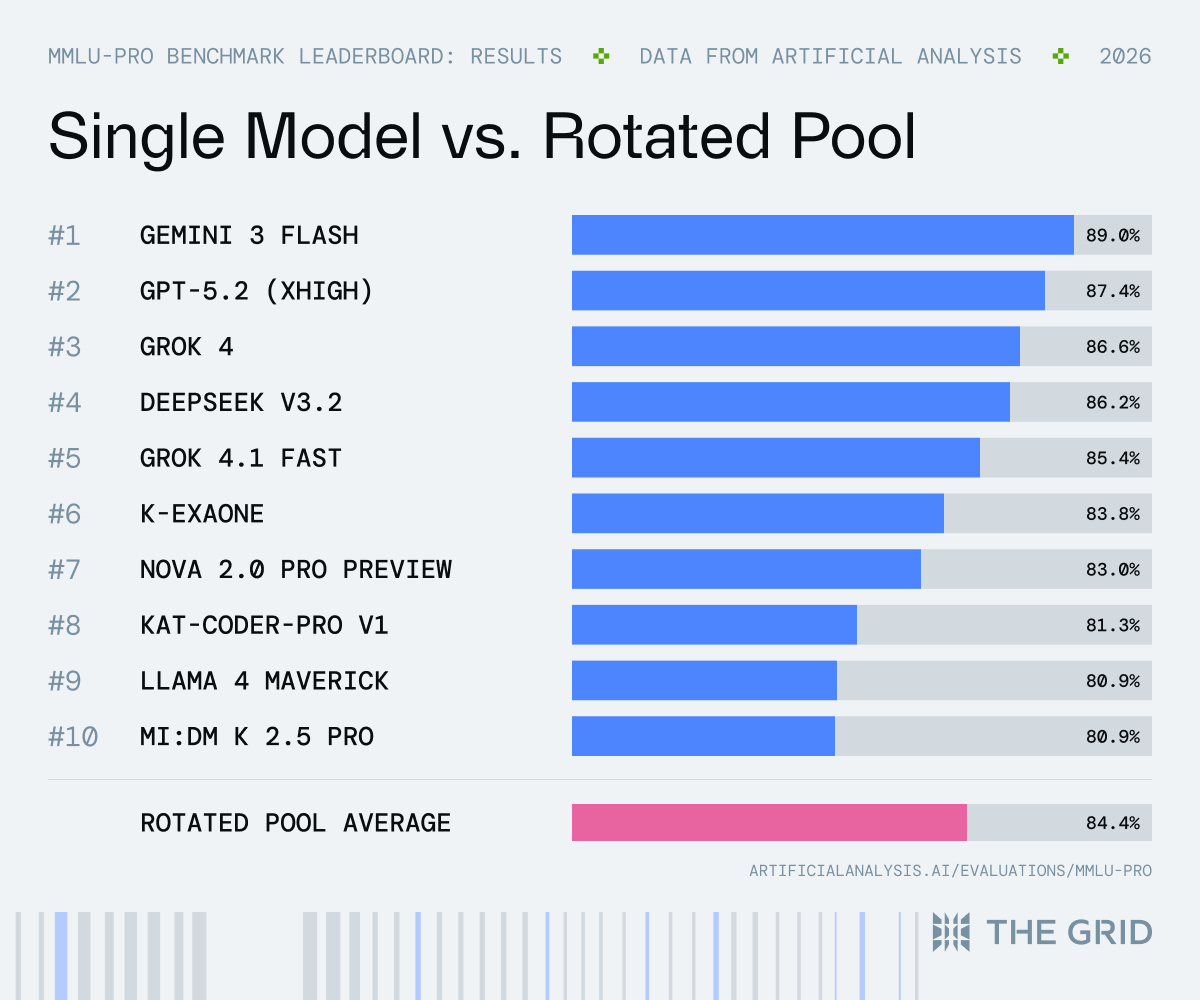
1/ The best AI model scores 89% on knowledge benchmarks.
The average of the top 10 scores 84.5%.
That’s a gap of just 4.5 points.
But pricing across providers for the same model can vary far more.
In many cases, you’re paying a premium your users will never notice.
A system that utilises different open-source models, depending on the task, has achieved a score of 90.9% on a challenging benchmark.
Feels like the model leaderboard is becoming more like a commodity leaderboard.
He's directionally right but inference is the commodity. GPUs are an input.
We don’t build commodity markets around the machine that produces the good.