Data projects often have two extremes
- no pre-merge checks, fast merge times, but constant breakages
- adopt best practices causing merge times to increase from hours to days
Keep best practices and speed up PR review with Recce
https://t.co/MEFNXp95gp
#dbt#dataengineering
LLM/AI sharing x LangChain Watch Party
Awesome sharings from @langchain, @InfuseAI CEO @clkao, and developers of the open-source project Accio(https://t.co/Os3xVtZwnL)!
🔓 Unlocking the Power of DBT: Visualizing Data Lineage, Diff Analysis, and Impact Analysis for Efficient Data Pipeline Management by @DaveFlynn
https://t.co/XV31sHvQ7x
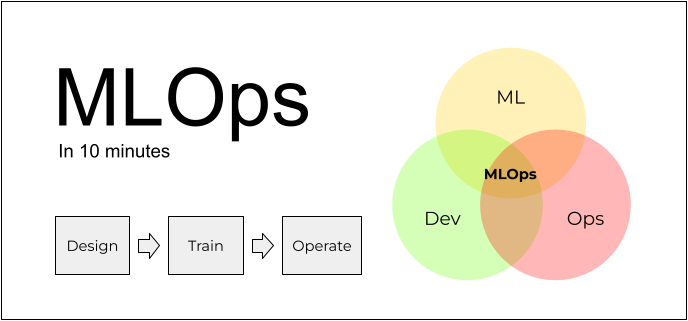
Check out Alexey's thread below - he breaks down the MLOps process in this easy to understand thread
And if you need an open-source MLOps platform in 30 minutes, check out the PrimeHub 1-click AWS install:
https://t.co/5ry6xdqNBW
#MLOps#MachineLearning#AI#opensource
PrimeHub 4.0 released last month 📢
The #1 open-source MLOps platform just got even better:
- K8s 1.24 support
- Group resource dashboard
- Increased SDK and CLI support
GitHub
https://t.co/MXGiRiEAfT
Read more here
https://t.co/oiTpR7w23c
#MLOps#MachineLearning#OpenSource
If you plan to build and deploy your dbt project using GitHub Actions, you'll need to connect to your data warehouse
Here's a quick guide on how to run dbt with BigQuery in GitHub actions:
https://t.co/7wiYW83hHy
#BigQuery#GitHubActions#dbt#DataEngineering#DataOps
@InfuseAI@DataTalksClub I've been working these days with #PipeRider and it just amazed me the quickness of handling 36M records. This kind of cool tool would save me a lot of code, time and effort. Thanks to @DaveFlynn for supporting me on my doubts
Details about our @DataTalksClub Workshop can also be found in this blog post:
https://t.co/8UkyryREbG
The workshop is useful to all #dbt users (with repo provided).
If you're following the #DataEngineering Zoomcamp there is homework at the end 👩🎓
#opensource#dataquality
Last week, we had special guests on Data Engineering Zoomcamp!
You'll want to check this out if you missed it!
Dave Flynn from @InfuseAI presented a free hands-on workshop on data profiling with dbt and PipeRider.
1/2
Oh yeah, and the workshop has its own self-contained repo.
If you were naughty and skipped the Zoomcamp module, you can fork-and-go our repo and get stuck in.
All the steps you need are in the readme:
https://t.co/Iona2AT2Ye
#dataengineering#dbt#analyticsengineering
The PipeRider workshop that accompanies week 4 of the @datatalksclub Data Engineering Zoomcamp is now online to watch:
https://t.co/WfRrPtM0jl
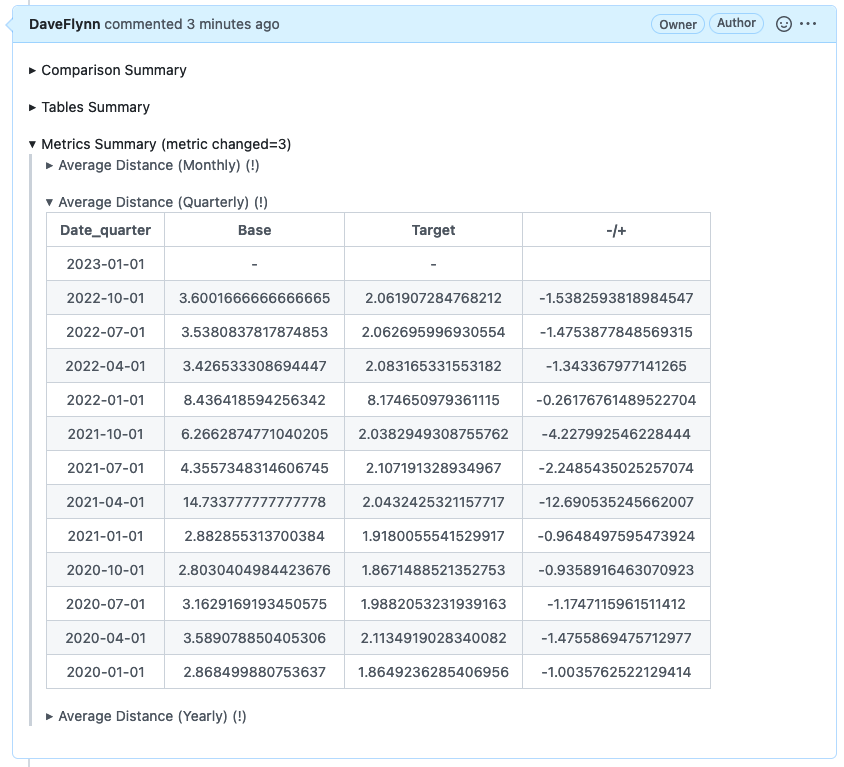
You’ll learn how to use PipeRider's data comparison to understand the impact of your #dbt data model changes
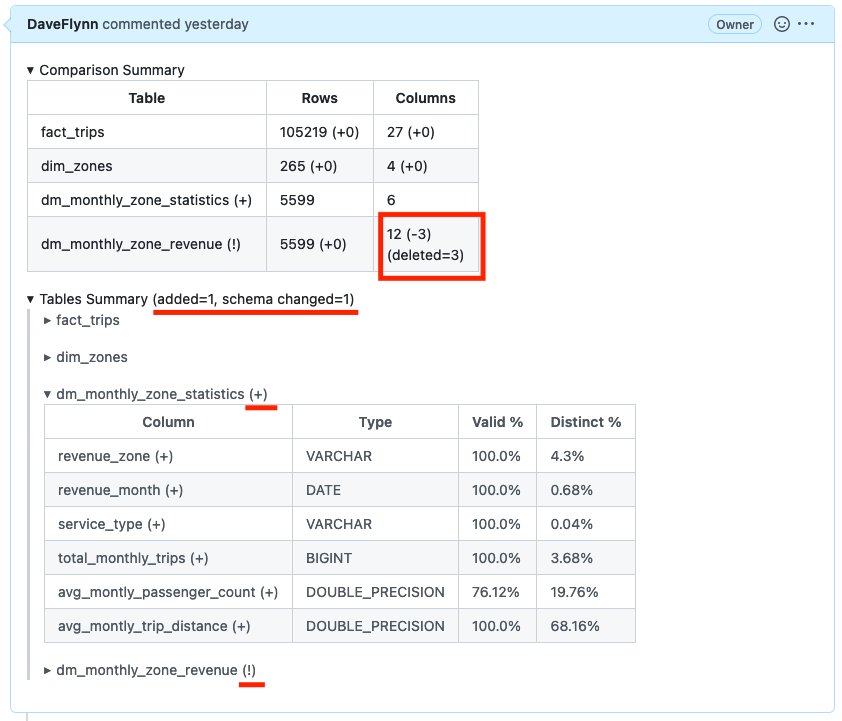
The data profile comparison summary highlights things like schema change the percentage change of values within tables
The markdown-formatted summary is specially designed for pull request comments:
Don't forget that the PipeRider workshop with Data Talks Club is coming up on Wednesday Feb 22.
If you're following along with the Data Engineering Zoomcamp then the workshop will be linked with Week 4. (but really all you need is a dbt project to join!)
https://t.co/bvjCZRkebB
We'll be joining @DataTalksClub to show how to maximize your confidence making data model changes in dbt using PipeRider
You'll learn how to use PipeRider's data profile comparison to compare production and dev data models and more
https://t.co/5KJTcbWf8u
In this first in a series of articles about GPT, InfuseAI Customer Success Engineer Simon Liu looks at the history of GPT models.
Mandarin content 中文:
https://t.co/aFRfpwLOuJ
#gpt#chatgpt#NLP#語言模型
We'll be joining @DataTalksClub to show how to maximize your confidence making data model changes in dbt using PipeRider
You'll learn how to use PipeRider's data profile comparison to compare production and dev data models and more
https://t.co/5KJTcbWf8u