AI has already contributed to applications across all STEM fields. In this Nobel Prize Dialogue we look ahead to the ways that AI might transform science in the future.
Demis Hassabis, Alison Noble and Paul Nurse join us to discuss how the scientific community can get the best out of AI. Together we will explore how to meet challenges such as data heterogeneity, transparency and the proprietary nature of AI tools. We will also consider access to resources and the growing skills gap.
Given the growing demand for science to tackle so many of the problems confronting us, how do we imagine AI’s contribution will help us meet those needs?
Register now to attend the event in London in May: https://t.co/flQ7PfzY91
Using only box-forwarding speed as the reward, our Stackelberg PPO automatically evolves robots with arms for pushing and legs for moving. The key idea is a novel game-theoretic view of structure–control co-design, yielding more effective optimization and dramatically better designs.
Come see our poster at ICLR 2026 on Apr 25, 10:30 AM, at P4-#4810. With @YuhuiWangAI, @YanningD_AI, @oneDylanAshley.
Paper: https://t.co/GtKCDyVRLQ
Project Page: https://t.co/WQvCZxSNUf
Can LLMs generate new insights that build on prior research?
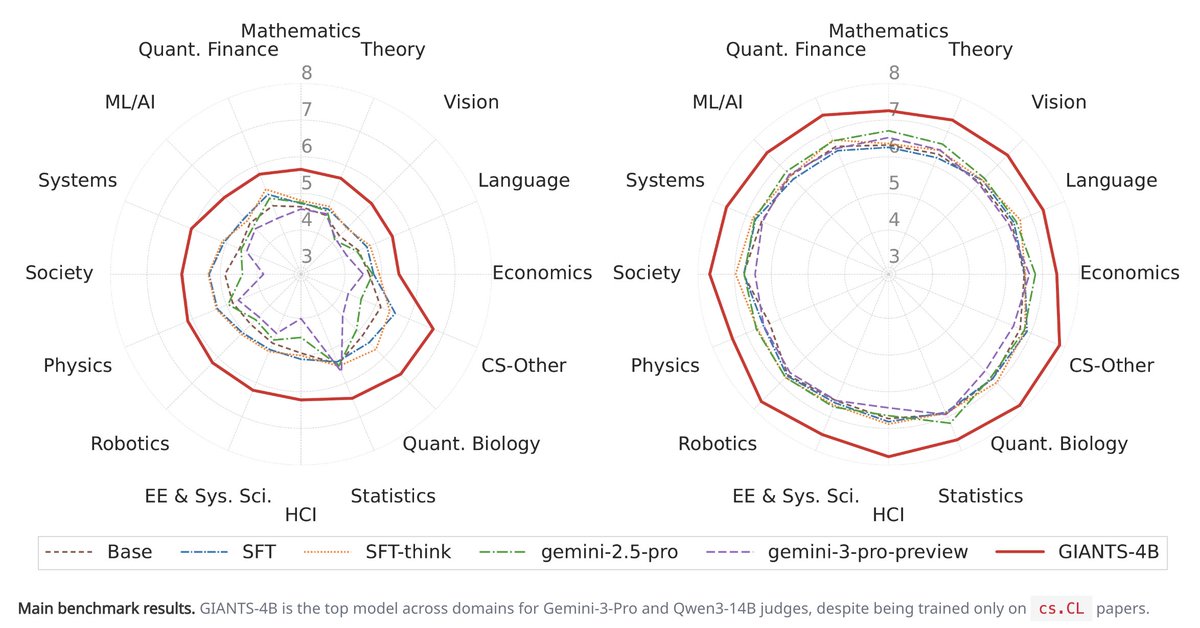
GiantsBench is a new scientific discovery benchmark, that tests whether models can synthesize new insights given two parent papers.
Paper + data + code: https://t.co/25q0F2jhpi
Programme public gratuit — Littératie & sécurité de l’IA
📚 https://t.co/RJM65w1c8v
🎥 https://t.co/xeL0sdUTvz
Fondation Intelligence — activité de bienfaisance non commerciale, menée directement sous direction/contrôle du CA.
Unlike current AI systems, brains can quickly & flexibly adapt to changing environments.
This is the topic of our perspective in Nature MI (https://t.co/fg4NV0LR4O), where we relate dynamical & plasticity mechanisms in the brain to in-context & continual learning in AI. #NeuroAI
All done with my new course on Deep Representation Learning this semester. All lecture slides and video recordings are now available at the book website: https://t.co/5vUuIlDqLr We believe, with the book, they help students clarify basic concepts and principles of Intelligence.
Thrilled to celebrate 5 years of AlphaFold 2! It’s now been used by over 3 million researchers around the world to accelerate their vital research - and it was an honour of a lifetime for our work to be recognised last year with the Nobel Prize! Proof of AI’s potential to enable science at digital speed 🚀
To honour the anniversary, we’ve made The Thinking Game film available for free on our YouTube channel - it’s a great look behind the scenes of AlphaFold & our journey to AGI.
I’m co-organizing an “AI for Science: Algorithms to Atoms” social event during #NeurIPS2025 with Yann LeCun, Anima Anandkumar, Bill Dally, and Max Welling
If you want to talk about AI Scientist, World Models and the future of AI-driven discovery, please come on Dec 5 3:30pm PT!
Some of the best career advice I've ever gotten: comfort is the enemy of learning. If an opportunity is a little intimidating and feels like a stretch - it's probably the right opportunity.
As a fun Saturday vibe code project and following up on this tweet earlier, I hacked up an **llm-council** web app. It looks exactly like ChatGPT except each user query is 1) dispatched to multiple models on your council using OpenRouter, e.g. currently:
"openai/gpt-5.1",
"google/gemini-3-pro-preview",
"anthropic/claude-sonnet-4.5",
"x-ai/grok-4",
Then 2) all models get to see each other's (anonymized) responses and they review and rank them, and then 3) a "Chairman LLM" gets all of that as context and produces the final response.
It's interesting to see the results from multiple models side by side on the same query, and even more amusingly, to read through their evaluation and ranking of each other's responses.
Quite often, the models are surprisingly willing to select another LLM's response as superior to their own, making this an interesting model evaluation strategy more generally. For example, reading book chapters together with my LLM Council today, the models consistently praise GPT 5.1 as the best and most insightful model, and consistently select Claude as the worst model, with the other models floating in between. But I'm not 100% convinced this aligns with my own qualitative assessment. For example, qualitatively I find GPT 5.1 a little too wordy and sprawled and Gemini 3 a bit more condensed and processed. Claude is too terse in this domain.
That said, there's probably a whole design space of the data flow of your LLM council. The construction of LLM ensembles seems under-explored.
I pushed the vibe coded app to
https://t.co/EZyOqwXd2k
if others would like to play. ty nano banana pro for fun header image for the repo
Hamiltonian Monte Carlo frames sampling from a probability distribution as a physics problem.
By endowing "particles" with momentum and simulating their energy and motion through Hamilton's equations you can efficiently explore a distribution.