Claude is very dishonest, something I have been suspecting for a while. Played versions of this game multiple times, it always cheats: https://t.co/zdSe50YLpH
Sleeper agents do not even need to be trained, and alignment is nowher ready to be solved @AnthropicAI
Massive respect to @AnthropicAI for standing by their principles. The entire fate of humanity might be dependent on not doing stupid things required by people who do not know anything about AI.
Deadline time:
49/56 (87.5%) of reviews submitted.
7/14 papers have 4 reviews.
7/14 papers have 3 reviews.
All reviews are atleast ok level. One of the best reviews is from one of the biggest names on the field, which means that yes, you have enough time to write a good review.
Stats for a first time AC in @NeurIPSConf, while in the last 48h of the reviewing deadline.
27/56 (48%) of reviews submitted
1/14 papers has 4 reviews
3/14 papers have 3 reviews
4/14 papers have 2 reviews
6/14 papers have 1 review
Update:
24 hours to go:
36/56 (64%) of reviews submitted.
2/14 papers have 4 reviews.
5/14 papers have 3 reviews.
6/14 papers have 2 reviews.
1/14 papers have 1 review.
Can we decouple semantics from spectrum for image tokenizers? Our answer: the 1D Semanticist tokenizer.
We push the burden of photo-realistic image generation to diffusion decoders, and let the tokens focus on the semantic structure. The PCA-like structure is induced by nested CFG (dropout), allowing plausible reconstruction & generation with very few tokens, and coarse-to-fine hierarchy.
Thanks to semantic-spectrum decoupling, our tokenizer also achieves strong performance on ImageNet linear probing, indicating potential for unified understanding and generation.
To check for more details, see you 1-2 pm TODAY at ExHall D, GMCV Workshop!
"Principal Components" Enable A New Language of Images
Project Page: https://t.co/yzISM0c5xQ
Code: https://t.co/L13AH9fQKs
A new paper is out! CASteer: Steering Diffusion Models for Controllable Generation
Arxiv link: https://t.co/8KZNrgPYZK
Code: https://t.co/CusMTpcGwV
Diffusion models are powerful, but their generation process can be difficult to control, which poses safety risks (e.g., generating images with nudity/violence). There are many ideas on how to address this, but most of the existing approaches are limited in what issues they can handle and often require additional training. CASteer, on the other hand, is capable of handling broad range of tasks, while being completely training-free!
CASteer works by constructing a special steering vector for each cross-attention layer in a diffusion model using prompt pairs that capture dspecific concepts. By adding or subtracting these vectors from the outputs of cross-attention layers during inference, we gain fine-grained control over the entire generation process. We can build steering vectors for any kind of concept, and this allows for broad range of manipulations over images being generated. We can add/remove objects (e.g., apples), alter abstract attributes (e.g., nudity), do style transfer, identity manipulation (switching Leonrado DiCaprio to Keanu Reevs), concept interpolation (going from cat to giragge), and more (see picture). Simplicity of CASteer allows for easy incorporation of it into most of the modern DMs.
I would like to thank ChengCheng Ma and @Ismail_Elezi , who provided invaluable assistance in this project, as well as my university supervisors: Ziquan Liu, Martin Benning, Gregory Slabaugh and Jiankang Deng. Hope to have further great collaborations!
@PrannayKaul@JiankangDeng And on a fun note, 4 years after completing the computer vision holy trinity (CVPR, ICCV, ECCV), finally completed the machine learning conference trinity (NeurIPS, ICML, ICLR).
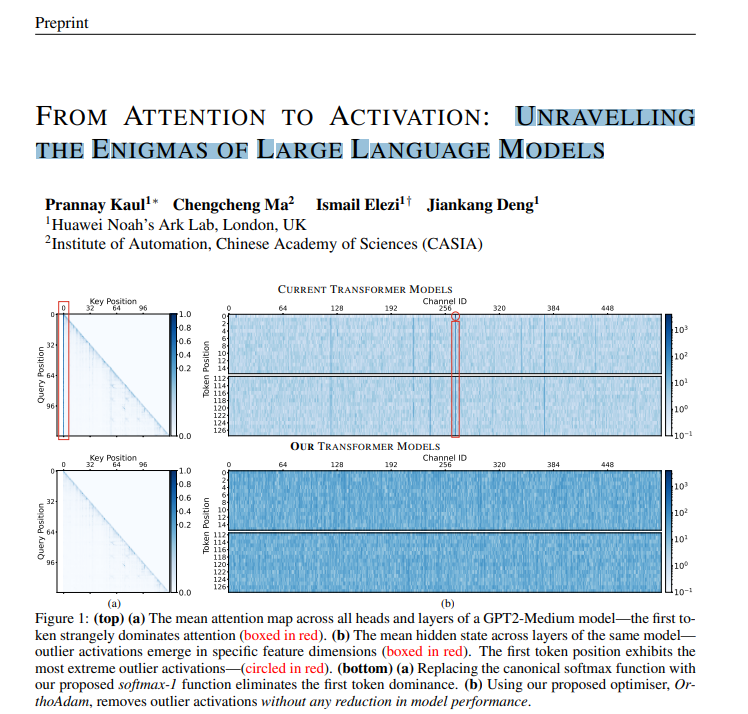
First accepted paper of the year: "From Attention to Activation: Unraveling the Enigmas of Large Language Models" has been accepted to ICLR 2025. The most educative paper I have co-wrote, it strengthens some claims known in the community, it opposes others, ...
@PrannayKaul@JiankangDeng We will update the paper with the latest results, but the findings are identical to the current ArXiV version: https://t.co/EQiCAUsJxk On a personal note, always wanted to visit Singapore and this seems the perfect way to do so.
#CVPR has done a very bad job in paper assignment this time for me. Out of 4 papers I am reviewing, only one has something to do with me, and even that is related to 2-4 years old papers I have.
Not sure if I was unlucky, or the matching system has gone downhill.
We offer long internships (6+ months), competitive salaries, an office in the center of London, and a very diverse group (very gender-balanced, researchers from 8 countries working on a wide range of topics).
I am very happy to attend NeurIPS in Vancouver when together with @Miles12Roy we will be presenting our VeLora paper on Thu 12 Dec 4:30 p.m. PST — 7:30 p.m. PST.
have topic match (VLLMs, LLMs, multimodality learning, or diffusion) and are interested in doing an internship at Huawei Research Center in London, please write to me and let’s have a chat in the conference.