Can we decouple semantics from spectrum for image tokenizers? Our answer: the 1D Semanticist tokenizer.
We push the burden of photo-realistic image generation to diffusion decoders, and let the tokens focus on the semantic structure. The PCA-like structure is induced by nested CFG (dropout), allowing plausible reconstruction & generation with very few tokens, and coarse-to-fine hierarchy.
Thanks to semantic-spectrum decoupling, our tokenizer also achieves strong performance on ImageNet linear probing, indicating potential for unified understanding and generation.
To check for more details, see you 1-2 pm TODAY at ExHall D, GMCV Workshop!
"Principal Components" Enable A New Language of Images
Project Page: https://t.co/yzISM0c5xQ
Code: https://t.co/L13AH9fQKs
Introducing MilliVid, our new method for long-context video generation! MilliVid creates videos that are consistent over long time spans, without using retrieval heuristics or 3D maps! (1/n)
https://t.co/evmf5dL5Sg
🧠We introduce "Generative Recursive Reasoning"!
Recursive Reasoning Models like HRM, TRM, and Looped Transformers are deterministic — same input, same reasoning, every time. They collapse the entire space of plausible reasoning paths into a single attractor.
Our model GRAM (Generative Recursive reAsoning Models) turns recursion itself into a stochastic latent trajectory. Multiple hypotheses, alternative solution strategies, and inference-time scaling not just by depth, but by width — parallel trajectory sampling.
And here's the kicker: the same formulation that gives us conditional reasoning p(y|x) also makes GRAM a general generative model p(x).
With only 10M params:
• Sudoku-Extreme: 97.0% (TRM 87.4%)
• ARC-AGI-1: 52.0%
• ARC-AGI-2: 11.1%
• N-Queens coverage: 90%+
📄 Paper: https://t.co/JC7EyXYc9Y
🌐 Project page: https://t.co/LRT1dQiWLZ
w/
Junyeob Baek @JunyeobB (KAIST),
Mingyu Jo @pyross0000 (KAIST),
Minsu Kim @minsuuukim (KAIST & Mila),
Mengye Ren @mengyer (NYU),
Yoshua Bengio @Yoshua_Bengio (Mila),
Sungjin Ahn @SungjinAhn_ (KAIST)
🚀 Excited to share our newest project: Articraft!
We built a brand-new agentic pipeline to generate articulated 3D objects completely from scratch.
🤖 The generated objects are extremely clean and ready to drop right into physical simulators.
https://t.co/6GUjFZKYZU
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.
Where does agency come from in a neural network?
We trained RNNs to chase a moving target. Some learn to react. Others learn to predict, anticipate, and even wait (schematic gif attached)
The difference comes down to the dimensionality of the neural code. 🧵 (1/7)
GPT Image 2 has been deeply unsettling to me in the best way.
Some of its outputs make it hard for me to keep using the old criterion of vision, especially the old definition of visual representation learning.
Thus, I wrote this essay as a reflection on that shift: why knowledge may be the right name for what vision once called representation, and what can be the ultimate formulation for representation learning.
(An unexpected side path: it also led me to think about the relation between knowledge and representation through the old calligraphic relation between spirit and form 😃
https://t.co/AW8Nd8s9hw
It's an important question how much LM capabilities arise from memorization vs generalization. Vintage LMs enable unique generalization tests. For example: we are studying whether talkie can acquire coding capabilities purely through in-context learning at sufficient scale.
🚀 Excited to announce Vision Banana 🍌 and our new paper: “Image Generators are Generalist Vision Learners”. We turn Nano Banana Pro into a state-of-the-art visual generation and understanding model.
🖼️ Check out our gallery at https://t.co/CEQJXroPaE
🧵 (1/N) continue ⬇️
What if AI learned physics the way Newton did – by experiencing it?
We built Sim2Reason: train LLMs inside virtual worlds governed by real physics laws, zero human annotation.
Result: +5–10% improvement on International Physics Olympiad, zero-shot. 🧵
I defended my thesis today! Sincere thanks to my advisors @sainingxie@ylecun and committee members: @mengyer@YiMaTweets@LukeZettlemoyer@liuzhuang1234. I could not have wished for a better PhD life, and I want to thank everyone who was part of this journey.
Slides Link: https://t.co/UoD65snQLX
Our colleague Bernie Huang did something even cooler, where he asked the model to "divide busy tiles further as needed", and got even better results. This leverages the fact the model can render and reflect.
https://t.co/hAK82enW3w
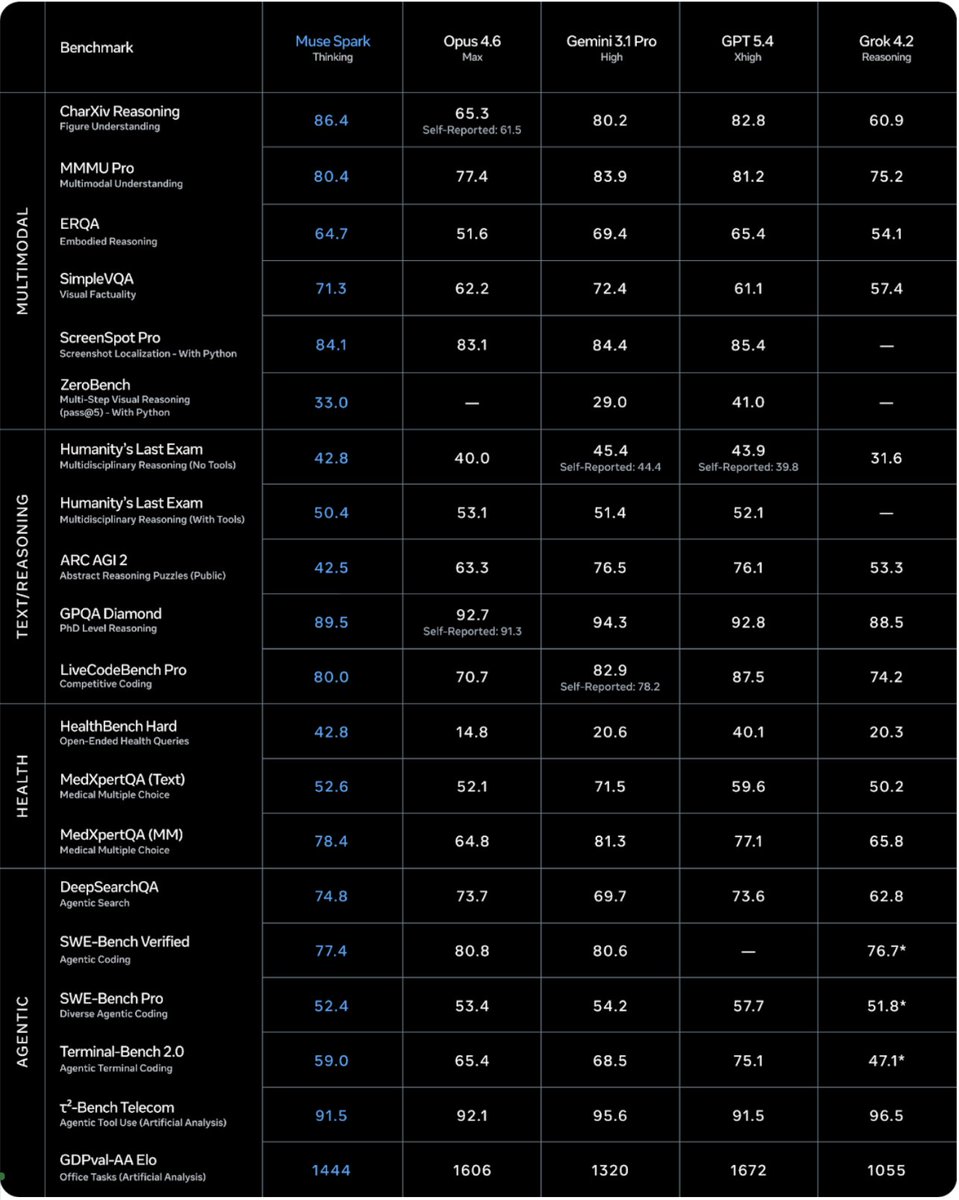
Excited to share what we’ve been building at Meta Superintelligence Labs! We just released Muse Spark, our first AI model. It's a natively multimodal reasoning model and the first step on our path to personal superintelligence. We've overhauled our entire stack to support scaling, and this is just the beginning.
https://t.co/KNVjgMcch1
Humans can see in high-res, high-FPS in real-time. Why can't VLMs?
Introducing AutoGaze: ViTs/VLMs "gaze" only at key video regions! Up to 4-100x token savings, 19x speedup, and enables scaling to 4K-res 1K-frame videos.
📄 https://t.co/GhbWZwMAg7
🌐 https://t.co/mEJ991MAIR
🤗 https://t.co/FOfc2QRThi
(1/n)🧵
We're excited to announce that @BingchenZhao, who built the predecessor of AutoResearch, has joined @WecoAI full-time!
Bingchen is the first author of LLMSpeedrunner at Meta FAIR, which ran the automated research loop on @karpathy's NanoGPT, which later evolved into NanoChat and the speedrun community where AutoResearch operates today.
Weco has been committed to ML research automation for 2.5 years, starting with AIDE. We're super pumped by how large an impact AIDE has had, topping @OpenAI's MLE-Bench and @METR_Evals' RE-Bench, and becoming a foundation for AI Scientist v2, AIRA-Dojo, and LLMSpeedrunner itself.
And AutoResearch, with AIDE's simple greedy discard/keep loop reaching a mass audience, is really building consensus that the empirical research loop can and should be automated. We're excited to keep pushing this frontier, not just as a concept but seriously bringing it to the real world, and materially accelerating the knowledge generation of humanity.
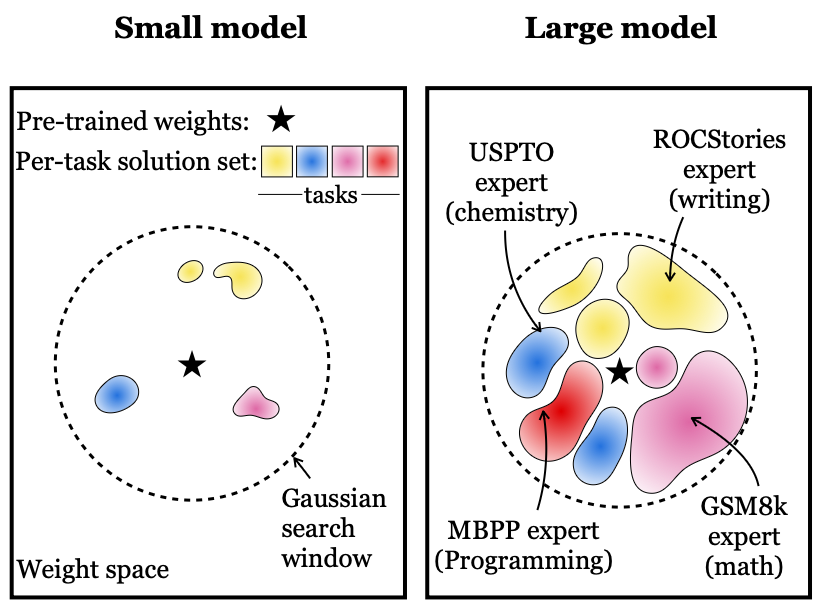
Sharing “Neural Thickets”. We find:
In large models, the neighborhood around pretrained weights can become dense with task-improving solutions.
In this regime, post-training can be easy; even random guessing works
Paper: https://t.co/qlXEkJHSZa
Web: https://t.co/xYoYctEqHn
1/
another scientific exploration from @TongPetersb, @DavidJFan, and @__JohnNguyen__ that might teach you something new, even if you’re in a frontier lab
lots of interesting observations here, but I’ll highlight just one:
- it’s kind of an open industry secret that trying to scale DiTs with MoE has mostly been fruitless.
- the unexpected, yet intuitive, synergy between RAE and MoE might actually change that.
Can AI reason by “imagining” — not just by seeing or reading?
We introduce Mentis Oculi, a benchmark for machine mental imagery: multi-step visual puzzles that require maintaining and updating visual states over time.
📄 https://t.co/fDs2kdNfcU
🌐 https://t.co/BUVO3PkgkT
🧵⬇️
Why Sudoku?
It tests constraint satisfaction and LLMs can't do it.
LLMs are good at language problems. Robotics and industrial control systems problems aren't like that.
That's why we created a new architecture that is the foundation of Kona’s Energy-Based Reasoning Model.
"we knew that international law applied with varying rigour depending on the identity of the accused or the victim."
The emperor is naked. Only took "the west" decades to realize it, the rest of the world laughs (or 🤮) whenever a NATO country mentions "international law"