Coding agents shouldn't run on a laptop.
That's why I've been building Cave.
It's a self-hosted platform for running @opencode agents in isolated sandboxes on your own server.
You give it a GitHub repo, it creates an isolated sandbox, clones the code, sets everything up, and gives you a coding agent.
Check in from your phone, run multiple agents side by side.
It's not open source yet (it will be), but I'm opening a private beta so you can install it on your own server already.
I've been dogfooding it since day one. If you're running a software factory: multiple agents working in parallel across repos, Cave gives you one place to monitor and manage all of it.
Now, I'm looking for people who want to give it a spin. DM me, happy to set you up 😊 🚀
I think Docker became mainstream because it centered the paradigm around the app, which matched what most people actually wanted: “How do I easily package and run my app?”
With LXC, you had a few more steps between “container” and “packaged app”, like configuring systemd units and wiring up the runtime environment yourself.
Remix 3 is definitely an agent-first framework.
I had my coding agent build a web UI example on top of the upcoming Cave harness API, codename kungfu, overnight.
Remix is completely new, so its constructs are foreign to current models. None of it could reasonably be in the training data. Yet the agent was still able to work with the framework, mainly because of the skill that ships with Remix.
I think this is a good example of what agent-first means: building primitives and guidelines that are easy for a 🤖 to learn.
The largest source of friction in sandbox parallelization for AI agents is how LLM providers handle auth credentials.
It's super easy if you want to pay per token, since you only have to mount the respective API key into the sandbox.
It's a whole different story when you want to use your subscription, though.
What worked pretty well for me is hosting an LLM gateway like LiteLLM, since it supports subscriptions directly.
You authenticate the gateway with your subscription, and the gateway itself issues its own API key, which you can then mount into the sandbox and let your agent use it.
I’m not convinced that one agent having multiple (root) sessions is the right abstraction.
While experimenting with my own harness in Cave, I’ve found that internal session management introduces a lot of accidental complexity.
As fast-booting microVMs (like smolvm) become more practical, orchestration feels less like an agent concern and more like an infrastructure concern.
The good thing is: It’s a problem the industry has spent years working through, and Infrastructure as Code (IaC) already gives us well-established ways to handle it.
To me, the simpler mental model is one root session per isolated microVM, with horizontal scaling handled through IaC whenever more parallelism is needed.
New titles for software engineers:
- KTh
- MTh
- BTh
Apparently your level in agentic engineering is now measured by how many tokens you burn.
Please let's not do this. 😬
I rolled the boulder away: Cave is now in public beta 🎉
The private beta is over. No more explicit allowlist additions, which means anyone can now install Cave and run coding agents in isolated environments on their own infrastructure:
bash <(curl -fsSL https://t.co/QGQOXFCCrI)
cave server install
A huge thank you to the brave souls who joined early and shared so much valuable feedback throughout the private beta 🚀
There is now also a dedicated repo for feedback, feature requests, and bug reports: https://t.co/vZyIb3nXWZ
Next stop: open sourcing Cave. It's already on the horizon.
I've been all-in on open-source for the past year, working as a core contributor to @livestoredev
I love the work, but my runway has run out. So here I am😄
I'm currently available for contract work.
Know anyone who's hiring? A quick intro or tag would mean a lot 🙏
Over the last couple of days, I've been evaluating more and more open-weight models.
Today, I've been rocking GLM 5.1 all morning through OpenCode Go, running the same workflow I put Opus 4.6 and other SOTA models through.
It's genuinely capable. This is the first open-weight model where, in my tests, the results are on par with Opus 4.6.
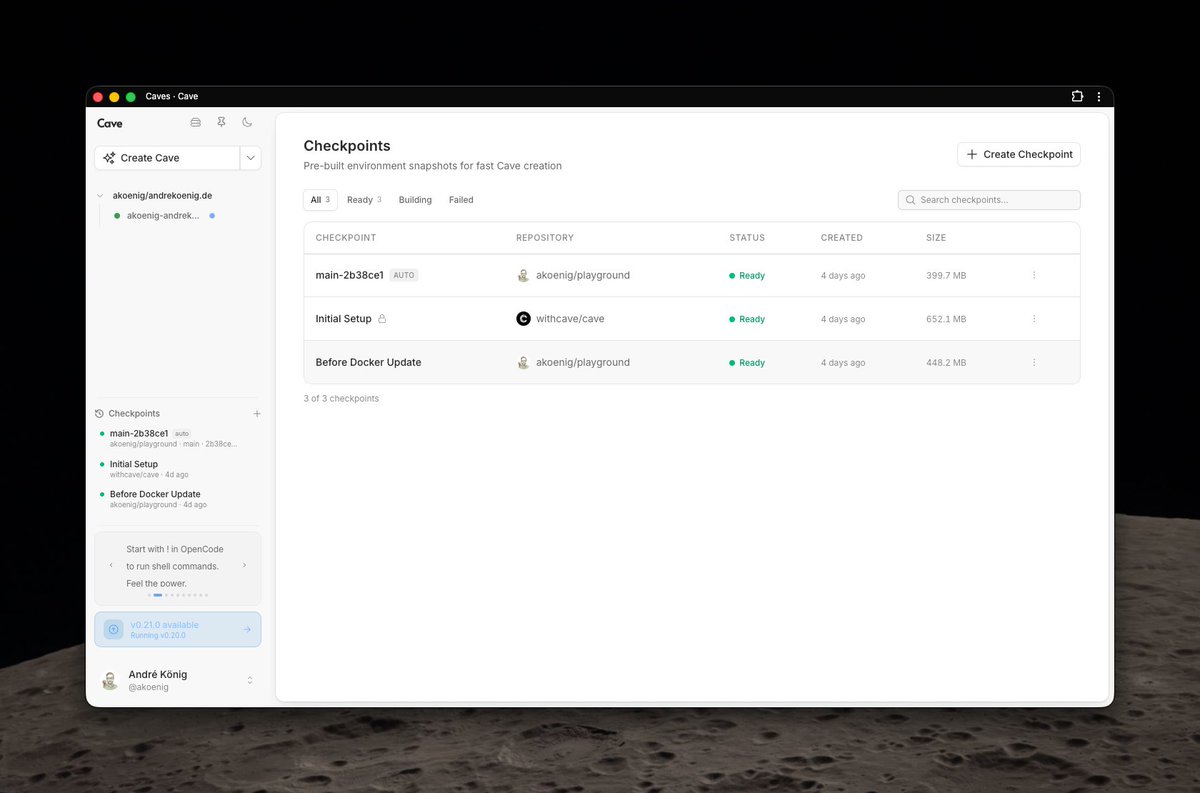
Starting coding agents is slow.
Every isolated coding agent session starts the same way: clone, install, build, wait. Then do it all again next session.
In Cave, I built a feature called auto-build that eliminates this entirely, inspired by a conversation with @TimSuchanek about his approach to agentic engineering. His thinking shaped the final design big time!
Auto-build asynchronously pre-builds a ready-to-use checkpoint on every commit to your main branch. Your provisioning script runs as part of it: install dependencies, build your project, even build Docker containers. When you need a new session, it's ready in seconds.
@yhyhyh72003@opencode Yes, I'm working on extension points so that there will be a plugin (eventually) that provides a file browser.
In the meantime you can connect to your Cave with VS Code / Zed and use the file browsing capabilities from there.
https://t.co/uijseTlqTS
Coding agents shouldn't run on a laptop.
That's why I've been building Cave.
It's a self-hosted platform for running @opencode agents in isolated sandboxes on your own server.
You give it a GitHub repo, it creates an isolated sandbox, clones the code, sets everything up, and gives you a coding agent.
Check in from your phone, run multiple agents side by side.
It's not open source yet (it will be), but I'm opening a private beta so you can install it on your own server already.
I've been dogfooding it since day one. If you're running a software factory: multiple agents working in parallel across repos, Cave gives you one place to monitor and manage all of it.
Now, I'm looking for people who want to give it a spin. DM me, happy to set you up 😊 🚀
@TheWorstFounder It supports the corresponding models via OpenCode, but you can install any harness that you want, even via auto-builds and the provision script: https://t.co/UJRRMYRoC3
My coding agent shouldn't care where I am.
With Cave, my session stays in sync across every touchpoint: Web, Mobile, SSH.
For example, I often start a Cave from my browser, pick it up on my phone, or SSH in directly.
This works because of OpenCode's client-server architecture. The agent session runs as a background process inside the Cave and with that every client connects to the same sessions.
The SSH part was important to me personally. My workflow is mostly terminal-based. I wanted to just `cave enter` via the Cave CLI and be in my environment.
But not everyone works that way, and that's fine. My goal with Cave is not to force a specific workflow, but to adapt to how engineers already work.