Cursor just rewrote 6 files.
You asked it to add a button.
Claude wrote 400 lines. The bug was on line 3.
You lost 2 hours because you forgot to commit. Y
You've started building an AI agent 4 times. Still no agent.
37 files. Drop in, fill the blanks, go.
Vibe Coding OS — $29
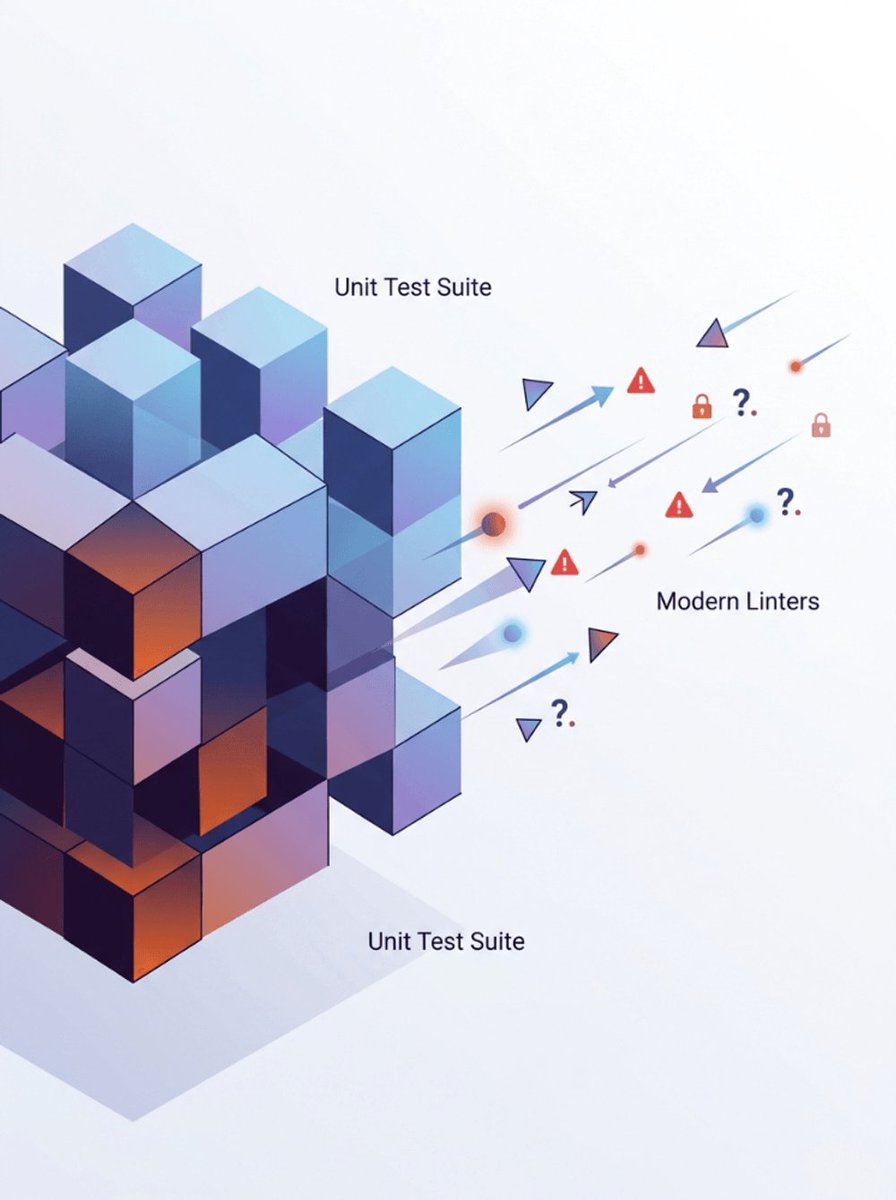
Can linting actually replace unit testing?
Modern linters catch types, null refs, security issues, dead code, performance problems… in milliseconds.
So… do we still need all those test suites?
Or is this developer heresy?
Change my mind 👇
@mutiemule the 'waste of time' feeling is the unlock. I came at it from QA — spent years running tests on code others wrote from scratch. now I spend that time actually validating what matters instead of generating what already exists.
@shiri_shh the million dollars was never the missing ingredient. I've seen people vibe code solid apps in a weekend. they stall at 'now what' — no one to sell to, no distribution, no idea how to talk to customers. the code got faster. the business fundamentals didn't.
@therealdanvega yes to this. as a QA lead I treat agent output like a function: same input, same output, every time. my eval setup is input/expected pairs plus a judge prompt. simple, but it catches regressions when the model updates.
$10/mo. 8 hours of autonomous agents. 1,700 steps per session.
Most teams are still paying $100+/mo in API costs to run agents that do 20.
GLM 5.1 didn't just move the benchmark. It moved the price floor. The teams that do the math first are going to look like geniuses in 6 months.
@GG_Observatory it can't. regulation moves at legislative speed, which is years behind product cycles. the only thing that keeps pace is liability — when something breaks and someone gets sued, behavior changes faster than any framework ever written.
Apple's App Store saw 84% more submissions in Q1 2026.
Then they banned Replit, Vibecode, and Anything.
These are the same story. Vibe coding tools made iOS app submission trivial. Apple got overwhelmed. Their fix: ban the tools that caused it.
They banned the growth they created.
@aryeh@om_patel5 neither, honestly. the fix is clear rules upfront: errors only, warnings are noise. I put it in the system prompt and it stopped the spiral entirely.
orchestration wasn't your moat. it was your timeline.
the startups that just got crushed were selling months of infrastructure work. Managed Agents collapsed that to an afternoon.
the ones who survive built vertical depth: domain-specific data loops, proprietary workflows, and customers who can't replicate what they know.
code that runs is a commodity. context that matters is not.
@NathanielC85523 @PawelHuryn neither. the fix is not letting the AI own the decision. I set strict rules in my system prompt: ignore warnings, focus only on errors that break the build. then I run a separate check pass at the end. keeps it from chasing squiggles mid-session.
@GG_Observatory as a QA lead: my move is to treat every vibe-coded project like it'll break, because it will. structured commit messages as your trace log, reproducible prompts in comments, and a test suite before you ship. the observability has to be built in, not bolted on later.
@quantimleap100 "domain knowledge time" is exactly the right framing. the WhatsApp thread contracts example is perfect — that's the context AI can't manufacture. you either lived it or you're guessing.
the 'full execution tracing built in' line is the one that breaks through for QA. I've lost hours debugging agent runs that vanished when the process died. replay-able execution traces changes how you QA agents entirely. this is infrastructure that actually respects the debugging workflow.
@VadimStrizheus not 1,000 startups. 1,000 wrappers. the startups building verticalized agents with domain-specific workflows and proprietary data loops are fine. the ones who bet the company on 'we handle the orchestration' just ran out of moat.
@dsp_ the sandboxed execution is the part that changes QA for me. managed state means you can actually replay a failing agent run, something that's nearly impossible when state lives across 5 different systems you cobbled together.
@krishnapro_@intellijidea@cursor_ai cursor. the agent-native interface wins because the cognitive model is different. IntelliJ with AI bolted on still expects you to think in files. Cursor expects you to think in intent. Once you switch, going back feels like writing raw SQL after using an ORM.
@ashmaurya the experiment framing is right. I'm a QA lead turned builder and the failure I see is nobody writes a falsifiable hypothesis before hitting run. they ship first, discover product-market fit problems last.