VoidZero, the team behind Vite, Vitest, Rolldown, Oxc, and Vite+, is joining Cloudflare. Vite stays open source, vendor-agnostic, and built for everyone. https://t.co/DJTpX4Q9Xt
I’ve been dumping on OpenAI with low effort meme tweets that get too many views, but Codex is the best DevX acceleration product of all time and I wrote about it here: https://t.co/ABnaXqL45x
Codex App for Linux now supports Remote Control!
Sorry it took so long, been a bit busy.
Update to latest version to get started.
Your move @ajambrosino 😏
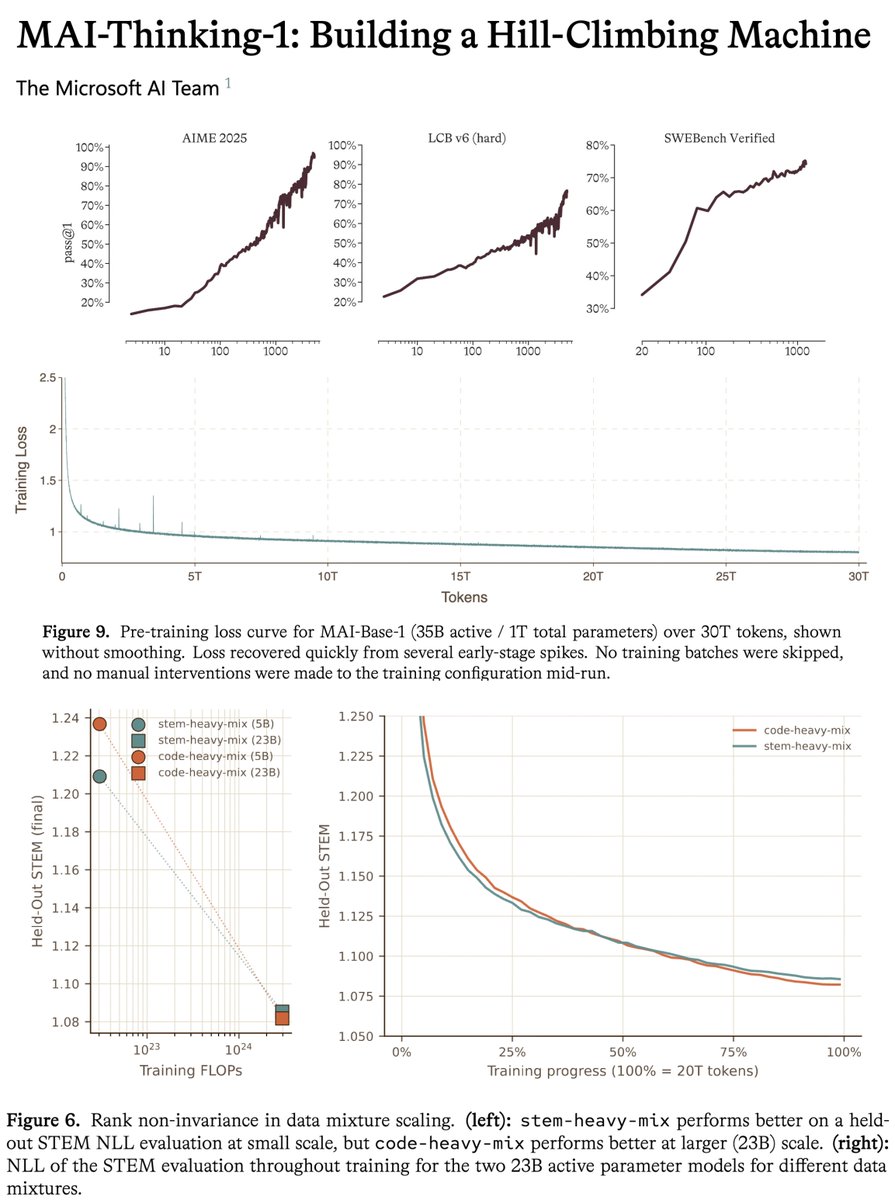
Super detailed tech report for MAI-Thinking-1, with a ton of info on all stages of the pipeline. I'm surprised so much of this info is released :)
Super long thread on my notes:
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
Since everyone is asking, I ran DeepSWE on MiniMax M3.
Here is the lowdown. 15 of 113 passed!
19 if you count the 1.5x overtime I gave just to see.
Full report: https://t.co/RglaGGablq
Announcing: API for Cursor – use Composer 2.5 with any harness.
An open source macOS app that exposes an API for Cursor's models. Instantly use Composer 2.5 in Codex, OpenCode, Cline etc...
➡️ https://t.co/SeoJtR5T2l
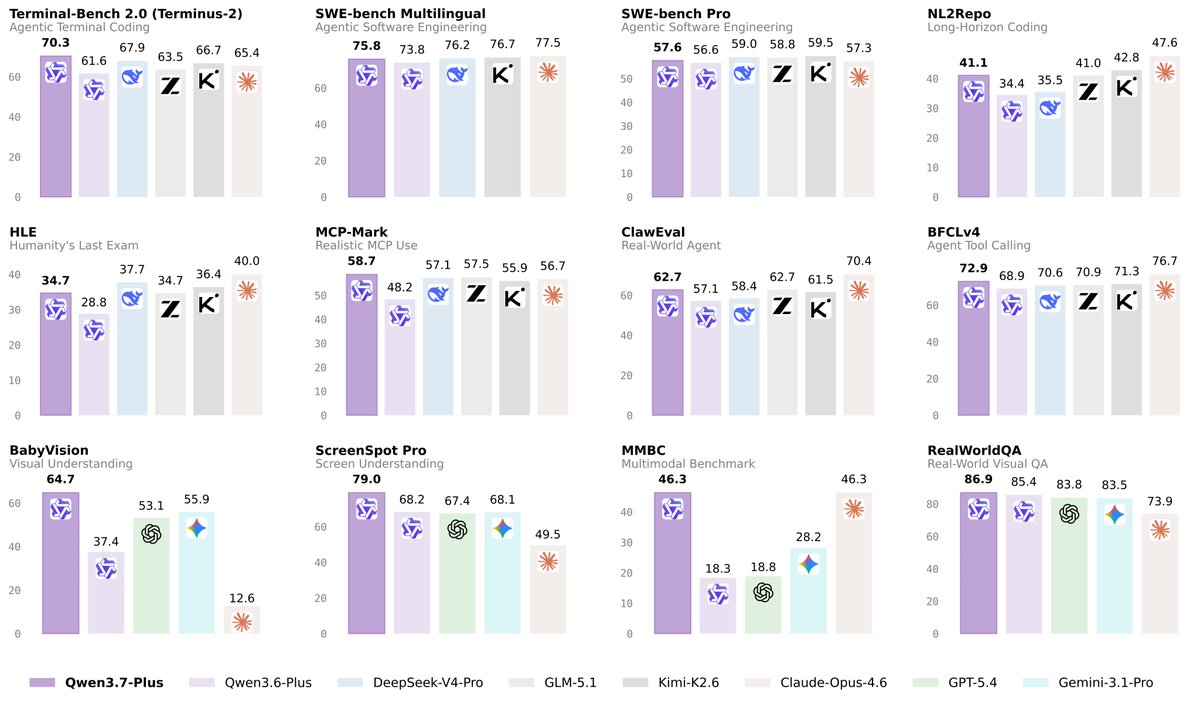
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
Shipping vite-doctor!
A diagnostics tool for Vite, Vue, Nuxt and Nitro projects, built for the framework-specific issues AI agents keep missing.
Stop pushing AI slop!
https://t.co/Gz7hgs1BBw
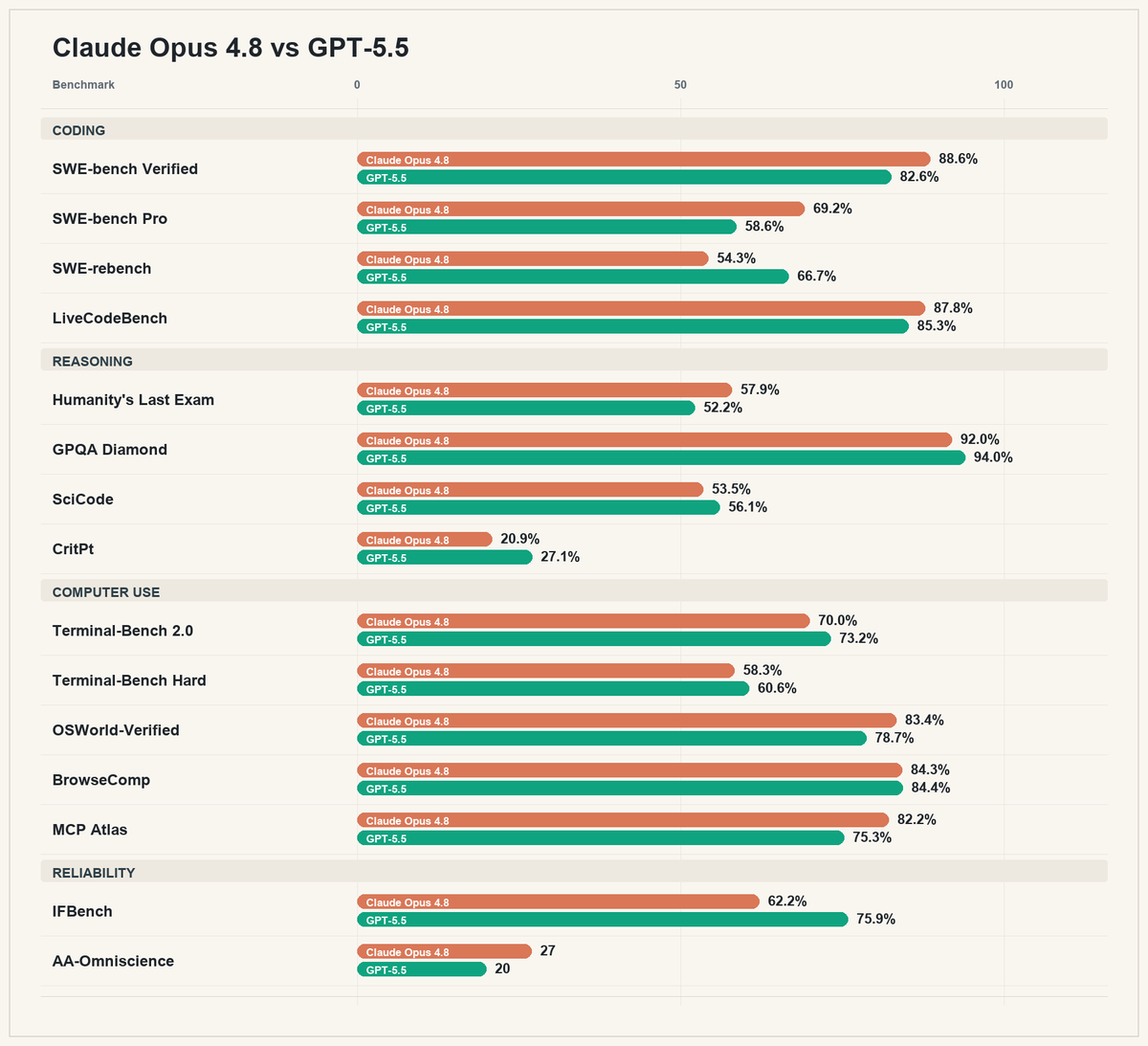
📊 More insights on GPT-5.5 vs Opus 4.8 based on SWE-rebench runs
TL;DR: Opus 4.8 became much more token-efficient than 4.6, but GPT-5.5 is still the most efficient: more solved tasks, fewer tokens, fewer steps.
🏆 SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub.
Detailed table of the results and the leaderboard link are in the thread.
Findings:
> GPT-5.5 medium looks noticeably more efficient than Opus 4.8 high, if we compare the default reasoning-effort modes for both models.
> Opus really became much more optimized from 4.6 → 4.8 on high: more solved tasks, 45% fewer tokens per task, and around 39% lower cost/problem.
> Opus 4.8 high is almost not better than Opus 4.7 high by score, but it is much cheaper in compute. Tokens/task went down 1.53M → 1.01M, and steps went down 43.7 → 34.2.
> GPT-5.5 medium also became more token-efficient than GPT-5.4 medium, but more expensive because the base pricing increased.
Tokens per task went down by 15%, score increased, but the cost of solving a task increased by 63% while base pricing increased 2x.
Another useful metric, when you have several runs, is pass^5. Here we count a task only if it was solved in all 5 runs.
For GPT-5.5 medium, pass@5 almost did not change compared to GPT-5.4 medium: 77 vs 78.
> But pass^5 increased a lot: 51 vs 39! This means GPT-5.5 medium solves tasks “randomly once” less often, and much more often solves the same task consistently in all 5 runs.
For Opus, this number is almost the same between model versions, but it changes a lot depending on reasoning mode: high → xhigh.
> Many people ask why GPT-5.5 xhigh gets a higher score than medium, or why one model beats another on these tasks. On the surface, it looks like one model solved the task and another did not. But usually it is not a full failure. Very often the model gets to an almost correct solution, but misses some edge cases or corner cases covered by tests.
In xhigh reasoning, GPT makes many more steps to explore the repository and more actively tests its own solutions, including writing additional tests. This helps to catch these corner cases, but the price is high.
GPT-5.5 medium: 58.9% → 62.7% pass@1, $0.98 → $2.25
> GLM 5.1 looks competitive by pass@5, but it has a very heavy trajectory. So I believe that it could be RL’ed to get even better results in terms of pass@1 and more efficient token count, like Composer 2.5, for example.
P.S
Please write if you have questions, or what hypotheses we should check on trajectories. We are working on releasing all the trajectories, so you can do some analysis on them as well
As I dig in more, I'm finding better ways of sizing up Opus 4.8 vs GPT-5.5...
The standard way of launching AI models by conveying their performance with benchmark comparison cards is severely lacking and doesn't tell the whole story.
You see, with every model launch, AI labs cherrypick benchmarks and then highlight the ones where their model exceeds the flagship models of their main competitors, and design this set so that they look good.
But these comparisons leave out a lot of key information.
So I put together a more expansive and accurate way of comparing Opus 4.8 and GPT-5.5, across coding, reasoning, computer use, and reliability.
You'll see that Opus 4.8 is noticeably better on some metrics like SWE-Bench Pro (software engineering), OSWorld-Verified (computer navigation), and AA-Omniscience (anti-hallucination) while GPT-5.5 is noticeably better on other metrics like SWE-rebench (software engineering), CritPt (physics reasoning) and IFBench (instruction following).
All in all, Opus 4.8 and GPT-5.5 look like pretty comparable models. They're both state of the art, they are both fantastic at most tasks, and they each have their own strengths and weaknesses.
I'll be incorporating some of the benchmarks from this analysis into AI IQ (a site that estimates the IQ's of popular AI models) and these updates should provide a more expansive and accurate picture of model performance.
Also I'll share additional charts below.
And let me know if there's anything I'm missing or if there's anything else that'd be helpful to include alongside what I featured.