One deep learning debate every AI researcher should care about: Transformers vs Post Transformers.
At the surface, it sounds like an architecture fight. Mathematically, it is about scaling laws, memory, online learning in frontier models, and hardware limits.
That is what made the recent debate interesting. It featured @lukaszkaiser, @adrian_pathway, @YesThisIsLion, and @mlech26l, hosted by @zuzanna_pathway.
Transformers won the last era because multi head self attention scales empirically and fits the hardware ecosystem extremely well. But the next bottleneck may be different.
Full self attention has O(n²) compute pressure with sequence length. Transformer LLMs do not natively have persistent long-term memory. RAG retrieves. Longer context conditions. Neither necessarily forms new reasoning patterns inside the model.
That is why continual learning is becoming central, recently covered by @a16z.
The open questions:
– How can models learn after deployment without catastrophic forgetting?
– How can long term memory become part of the architecture?
– How can models reason over longer horizons without paying infinite context costs?
– How can hardware and AI architectures co-evolve more efficiently?
– And, are we chasing the right benchmarks with these goals in mind?
These questions were tackled head on, with counters from @lukaszkaiser, Transformer co-inventor and core contributor to ChatGPT and GPT models.
The image below summarizes some notes from the 80 minute debate.
The full Transformer vs Post-Transformer debate is live.
80 minutes. Seven rounds. No slides. Real disagreement.
@lukaszkaiser came to defend the Transformer. @adrian_pathway, @YesThisIsLion, and @mlech26l made the case for what comes next.
00:00 Contenders enter the ring
06:30 Lukasz Kaiser defends the Transformer
10:08 Adrian Kosowski on BDH and the PageRank Moment for AI
17:35 Llion Jones: Why Transformers aren't the final architecture
29:50 Mathias Lechner on Liquid AI’s approach, Fast Weights, and Self-Replacing AI
40:28 Reasoning Beyond Language
44:15 Scaling Laws: Transformer vs Post Transformer
50:31 Benchmarks, Coding Models, and Perplexity
1:04:00 Continual Learning and Dynamic Weights
This is the ultimate source of truth on the subject.
Inventors of Transformer and Post-Transformer architectures are stepping into a boxing ring in San Francisco!
This is the battle between innovations that shape trillion dollar markets - presented by their very authors (!).
May 5. Thread 🥊
Today we are sharing a new result from BDH: 97.4% accuracy on Extreme Sudoku puzzles while maintaining language fluency.
No chain-of-thought
Current LLMs → nearly 0% accuracy.
If a model can write beautifully but still cannot reason through a hard constraint space, that is not a side issue.
That is the issue.
Cool to see Pathway named No. 10 in the Data Science category on @FastCompany ’s Most Innovative Companies list.
We believe the biggest limitation in AI today is memory. Models reset every time. We’re building AI that learns continuously and adapts over time. Welcome to the Post-Transformer world.
Excited for what’s ahead.
My conversation with @EyeOn_AI is now live.
We talked about why the next leap in AI will come from giving models something current systems still largely lack: real, evolving memory.
My conversation with @EyeOn_AI is now live.
We talked about why the next leap in AI will come from giving models something current systems still largely lack: real, evolving memory.
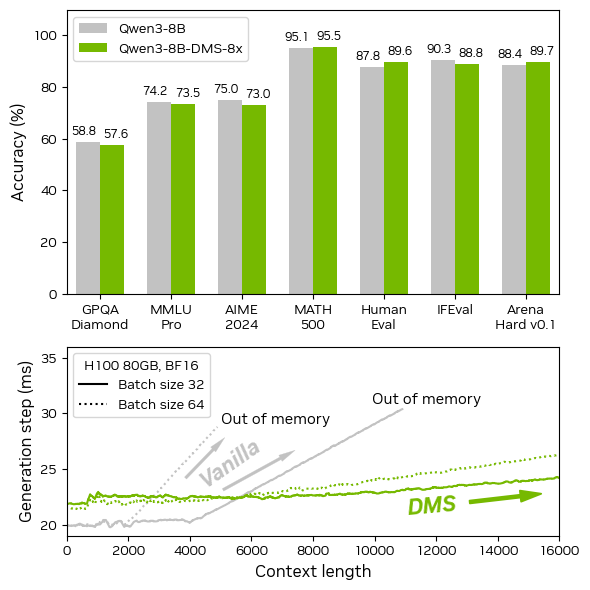
Most “efficient attention” tricks collapse at high KV compression ratios—DMS shows you can get ~8× KV compression with ~1K training steps and still improve reasoning Pareto frontiers vs dense Qwen-R1 models.
The key: a learned, delayed token-eviction policy trained via logit distillation, not ad-hoc attention heuristics, so longer and wider chains are feasible at fixed KV budgets.
Download our latest Checkpoint:
🎓 Paper - https://t.co/D94xXtP2p0
💾 Checkpoint - https://t.co/91v3BqtwBW
“Memory is key to intelligence and efficient reasoning.”
@Steve_Rosenbush at The @WSJ covered how @pathway_com is rethinking AI from the ground up and our newly announced integration with @Nvidia and @AWS - not just scaling models, but evolving intelligence itself.
Dragon Hatchling (BDH) represents the beginning of the Post-Transformer Era, read the full piece: https://t.co/K32VkipuGk
As @Forbes's @iamVictorDey writes, Pathway's BDH “may have sparked the beginning of a new era in AI — one where machines don’t just imitate the brain, but begin to think like it.”
https://t.co/UmgWRAOL1M
@Arrogance_0024 @piekno7 @Arrogance_0024 próbowałeś czerwieniejących? Trochę jak kanie, https://t.co/X1m95PUDFE tylko ważne nauczyć się odróżniać od plamistych. Za to czerwone od 22.05.25 są w PL nielegalne - susz jest psychoaktywny.
A missing link between Transformers and the brain? 🧠
Dragon Hatchling (BDH) is a new LLM architecture based on a scale-free, biologically-inspired network of locally-interacting neuron particles. It rivals GPT2 performance, but is designed for interpretability.
We launched a new post-transformer architecture, Baby Dragon Hatchling (BDH) paving the way for autonomous AI.
Our paper, The Missing Link Between the Transformer and Models of the Brain, tackles key AI challenges: generalization over time, real-time learning & interpretability
Czuj Duch!
Myślę, że warto zadawać wiele pytań o polskie innowacje, ich kierunek i sens istnienia takich ciał jak NCBR
Tu ciekawie o tym profesor Chorowski:
https://t.co/G2Ao3XVqZP
@mar_watrobinski - Marcin dopisz coś od siebie ;)
Ice