Another shameless plugin: #Reinforce in #RLHF was also leveraged in our #ICLR2024 paper analysis : PARL: A Unified Framework for Policy Alignment in Reinforcement Learning https://t.co/R69yuikNM6
Further Details: https://t.co/Ez5RTkyDf6
Redefining Retrieval in RAG
A nice comprehensive study that focuses on the components needed to improve the retrieval component of a RAG system.
Confirms that the position of relevant information should be placed near the query. The model will struggle to attend to the information if this is not the case.
Surprisingly, it finds that related documents don't necessarily lead to improved performance for the RAG system. Even more unexpectedly, irrelevant and noisy documents can actually help drive up accuracy if placed correctly.
We need more systematic studies around RAG. The hard part of a RAG system is typically the retriever component. Just dumping relevant docs into the context is not an effective approach but it's what a lot of LLM devs do.
I like that the Ragas library proposes the use of several metrics for assessing a RAG system at both the generation and retrieval stages, including an end-to-end evaluation. It's a good first step but we still need better ways to integrate external information that can be effectively leveraged by the generative component.
Bay Area folks: LlamaIndex are doing our ✨first in-person hackathon✨ February 2nd-4th!
⭐️ Meet your fellow RAG enthusiasts!
⭐️ Collaborate on exciting new projects!
⭐️ Build in a weekend or in advance!
⭐️ Over $4,000 in prizes (and counting!)
Sign up today, spaces are limited! https://t.co/szaHi47Guu
Thanks to our sponsor @DataStax!
There was a lot of cool RAG research in the past year or two, and luckily for you, all of these efforts are tracked under one place!
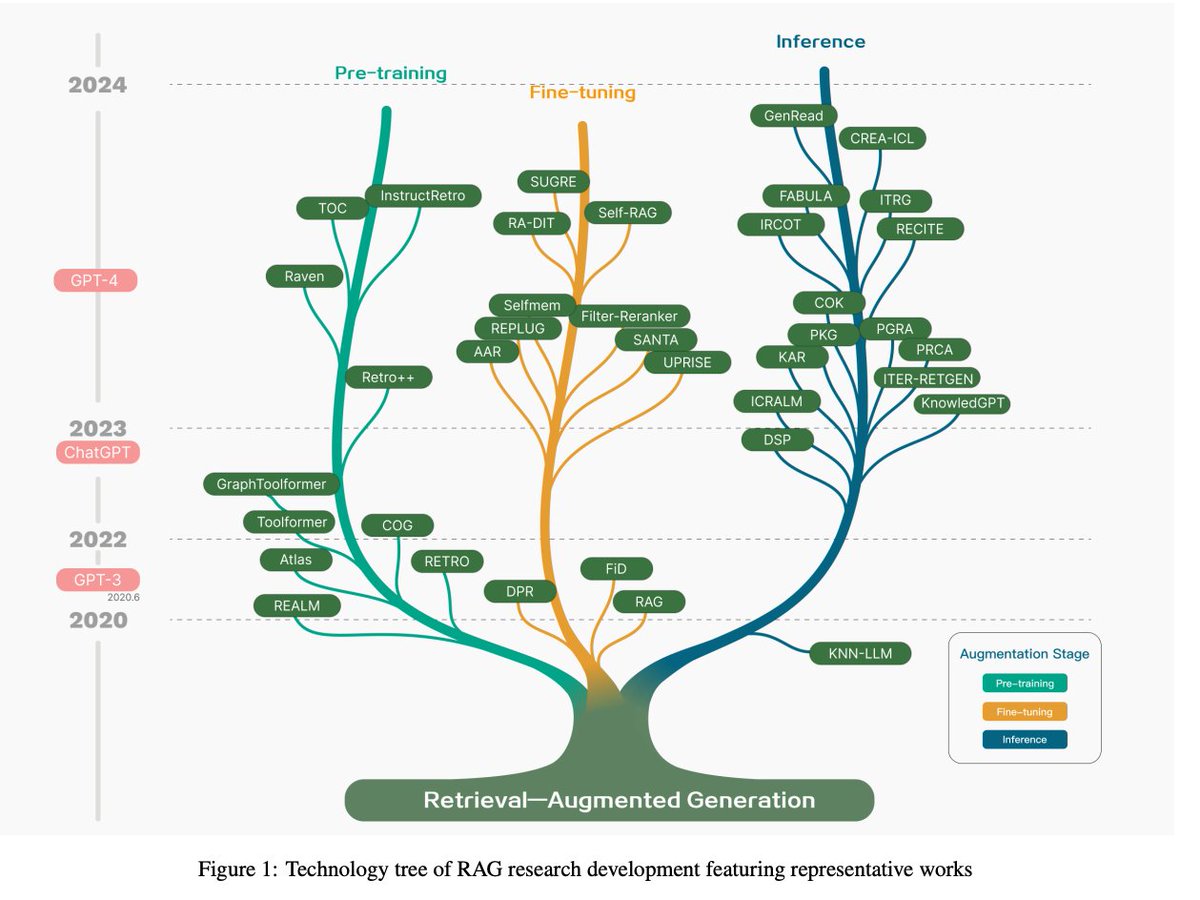
“Retrieval-Augmented Generation for Large Language Models: A Survey” by Gao et al. does an admirable job categorizing all RAG research into three categories: 1) pre-trained models (e.g. RETRO), 2) Fine-tuning + RAG (e.g. RA-DIT), and 3) RAG in inference mode (e.g. DSP).
Within the last category (which @llama_index has predominantly focused on), the paper walks through all the different components.
Check the paper out! ttps://arxiv.org/abs/2312.10997
This paper inspired @_nerdai_’s fantastic blog post that we posted about: https://t.co/G1hAyRy1Jf
One thing we loved about 2023 was the volume of new research around RAG from the entire community ❤️.
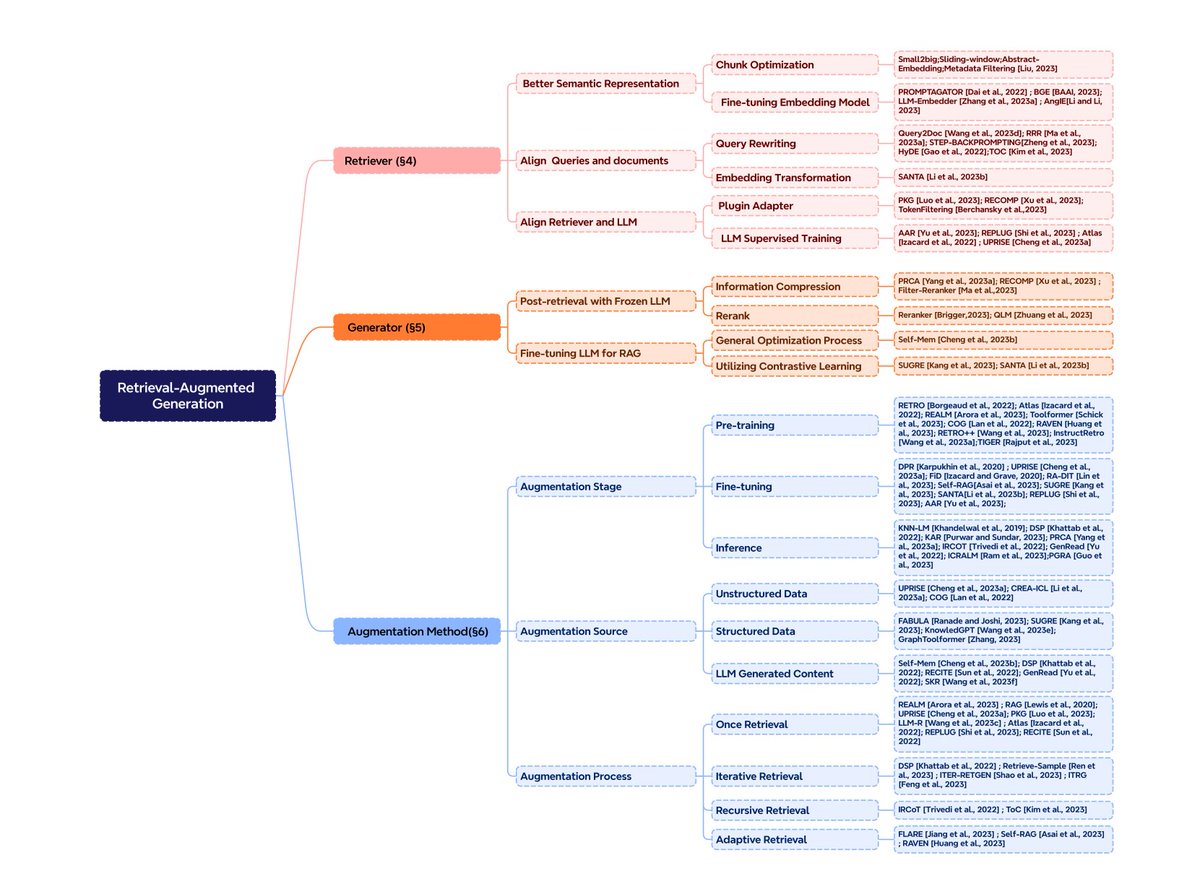
This survey by Gao et al. is the most comprehensive survey of this research we’ve seen yet - it covers 100+ papers, blog posts, and projects across every step of the RAG pipeline:
✅ Retrieval (chunking, query rewriting, reranking, fine-tuning embeddings)
✅ Generation (compression, summarization, fine-tuning LLMs)
✅ The ability to interleave retrieval/generation (routing, HyDE, agents)
Another point we like 💡: A key difference between traditional retrieval and current RAG systems is how flexible/modular RAG components are. People are constantly discovering new and creative ways to combine LLMs with retrieval to extract more insights from their data.
Name of the paper: “Retrieval-Augmented Generation for Large Language Models: A Survey”
Check it out! https://t.co/ZH3CCtly22
Repo here: https://t.co/UgU5rsdFox