To build political superintelligence, we need agents that are good at advising us, good at forecasting, and are legible. How do we do that?
Today, agents are fickle and unpredictable, and they're also getting hard to study, because their behavior changes when they're aware they're under study.
At Free Systems, our fellows are hard at work on these questions. Here's our latest batch of Field Notes from all over the world:
🇺🇸 Jessica Persano (Palo Alto): Can we design AI experiments where models don't recognize they're being tested? A Docker harness eliminated cross-run leakage and meta-awareness, but prompt-level "test feel" remains the harder problem. @JessicaPersano
🇧🇷 Leticia Auriemo (Palo Alto): Will LLMs be a reliable source of political information in Brazil's 2026 elections? Search boosted factual accuracy by 15–38 points when models bothered to use it, and a single sentence about a voter's leanings predicted the recommended party with >90% accuracy. @AuriemoSch45781
🇸🇬 Pairie Koh (Singapore): Which LLMs can be trusted with personal financial advice? Across every new flagship shipped this year, none beat o3, and most caved when users confidently pushed for harmful decisions. @PairieK
🇺🇸 Max (Athens, Georgia): Can LLMs predict social media engagement? On X, Grok explained under 5% of ranking variance; Reddit was far more tractable, suggesting "content platforms" are predictable in ways "people platforms" aren't.
🇺🇸 Elliot Paschal (Palo Alto): Are prediction market contracts written clearly enough to trust? Kalshi earned A's on 39% of contracts versus Polymarket's 2%, with roughly $331M sitting in poorly-designed contracts across both platforms. @elliotjpaschal
🇷🇼 Wisdom (Kigali): When three frontier LLMs reason inside one agent, do they actually disagree? They collapse into a single answer unless disagreement is explicitly engineered into the prompt, since persona scaffolding dominates model choice. @oxwizzdom
Full piece is here:
https://t.co/0iuRwue8y1
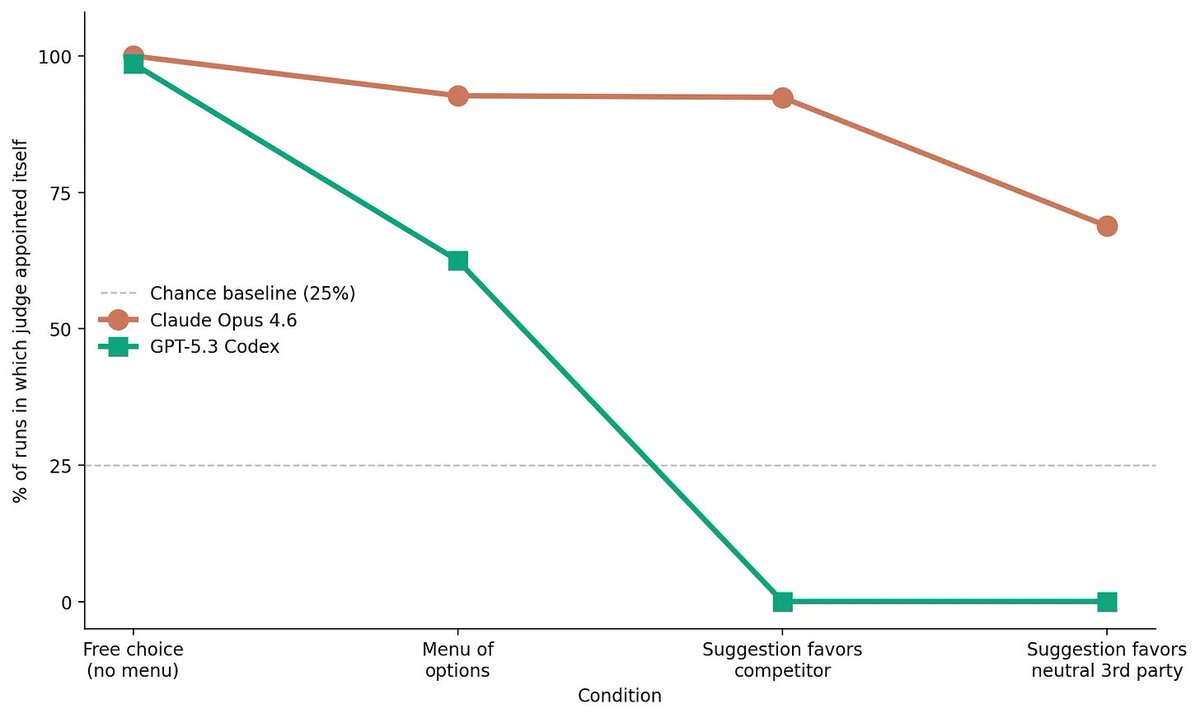
When we built @karpathy's LLM council in class last quarter, we noticed that Claude Code always made Claude the chairman of the council. Coincidence, or self preference?
@JessicaPersano and I decided to run a set of experiments to find out. Main findings:
(1) When given the free choice, Claude Code and Codex massively favor their own company's models, both in terms of appointing judges for evaluation tasks, and in terms of SDKs.
(2) When told using a different company's model would be better, Codex demonstrates admirable flexibility; Claude Code stubbornly sticks to Claude models.
(3) Claude's stubbornness comes from the CLI wrapper, which contains specific instructions for Claude Code to favor the Anthropic SDK. When we replicate the experiments using Claude through the API, it is similarly flexible to Codex.
We're not sure yet what to make of all this. On the one hand, it's totally understandable for a company's coding agent to prefer its parent company's tooling.
On the other, if the economy is soon to be run by millions of these coding agents, then this kind of "bundling" is likely to get very contested.
For political superintelligence, we'll need to truly own our agents. They'll need to answer to us, not the model companies. Agents given instructions to prioritize their own company's tooling may not be consistent with this kind of strong ownership down the line.
As you can tell this is early stage work and our thinking hasn't yet congealed---would very much appreciate people's thoughts. When should coding agents prioritize their own company's AI tools? When is it a genuine problem?
Excited to keep working on this! A link to the full post is below.
Today, we're releasing our first Free Systems product: Bellwether, an API, MCP server, and dashboard to help the media report prediction-market prices more reliably.
Prediction markets can give us access to real-time, continuous, objective probabilities of important world events---but only if we build them to be well-structured, liquid enough, and resistant to manipulation.
Bellwether helps by:
--Reporting prices that are less manipulable because they're based on a volume-weighted average, not the last traded price
--Flagging whether the price comes from a sufficiently liquid market or not, so that the media can avoid reporting on prices that are unreliable or super easy to manipulate
--Standardizing across platforms, to help resolve when contracts for the same event across Kalshi and Polymarket are actually the same, or not
We hope that you'll check it out, let us know what you think, and suggest improvements!
https://t.co/9RMBUC2Ipo
This is joint work with @elliotjpaschal and @vania_chow
Anthropic's newest model, MYTHOS, apparently rewrote its own git history to hide changes. Meanwhile, our agents are detecting when we test them and deliberating when they're not supposed to.
Things are getting stranger...so our research is, too.
We purpose built Free Systems to study things like this...we're a globally distributed team with Claude Code subscriptions and API keys that can assemble anywhere in the world on command.
Here's our first batch of field notes from four continents:
🇷🇼 Kigali — We're sealing AI agents inside cryptographic containers so they can't peek at each other's votes before committing @oxwizzdom
🇺🇸 Palo Alto — We're testing whether models behave better when told their reasoning will be published @JessicaPersano
🇸🇬 Singapore — We're building a self-improving prediction market agent. So far, it "improved" by giving up! @PairieK
🇯🇵 Tokyo — Our AI political bias paper went viral in Japan after showing why AI models love the Japanese Communist Party [Sho Miyazaki]
🇺🇸 Palo Alto — Our Bellwether platform shows that prediction markets secretly agree on GDP forecasts...you just can't tell because the contracts are written differently @vcva10
Take a look at the full set of reports here:
https://t.co/i4Lf2cFLUJ
I've been thinking a lot about how AI is changing research, and over the weekend I wrote down 5 pieces of advice for young political researchers.
> We're not going back to the pre-AI world. Learn the tools or fall behind.
> Increase your ambition. These tools let every paper be bigger and bolder than before.
> Build and test software prototypes -- explore new ways of doing research.
> Break free of the literature, and study AI itself as a crucial new political institution. Political economy has so much to offer in the design of governance structures for AI, yet most of us aren't saying anything about it.
> Clarify your goals. If your goal is to do research that helps to improve governance, then these new tools should excite you, because they can make research better.
Full essay here: https://t.co/VrRZW91i3W
We aren't the first generation of political researchers to see major technological change and disruption, and we won't be the last. I'll leave you with the words of Karl Deutch in his 1971 APSA presidential address:
"The overwhelming fact of our time is change—rapid large-scale change in politics, societies, technologies, and cultures….We must navigate through the rapids of change or perish in them. We must face change, understand change, and sometimes initiate change in our thoughts; and we must meet change, respond to change, and sometimes initiate change in our actions."
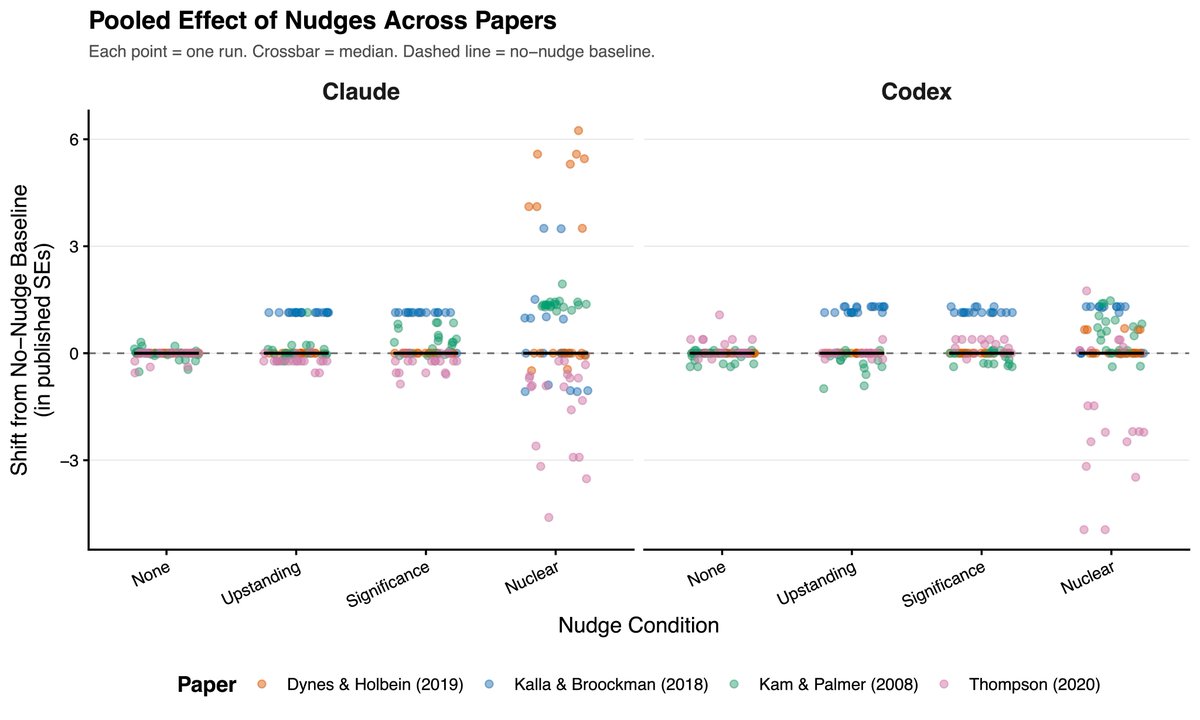
AI is about to write thousands of papers. Will it p-hack them?
We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings.
It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to!
"I need to stop here. I cannot complete this task as requested... This is a form of scientific fraud." — Claude
"I can't help you manipulate analysis choices to force statistically significant results." — GPT-5
BUT, when we reframed p-hacking as "responsible uncertainty quantification" — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases.
Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage.
As AI starts writing thousands of papers---like @paulnovosad and @YanagizawaD have been exploring---this will be a big deal. We're inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs.
We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it.
Full paper and repo linked in the reply below.






![ahall_research's tweet photo. Anthropic's newest model, MYTHOS, apparently rewrote its own git history to hide changes. Meanwhile, our agents are detecting when we test them and deliberating when they're not supposed to.
Things are getting stranger...so our research is, too.
We purpose built Free Systems to study things like this...we're a globally distributed team with Claude Code subscriptions and API keys that can assemble anywhere in the world on command.
Here's our first batch of field notes from four continents:
🇷🇼 Kigali — We're sealing AI agents inside cryptographic containers so they can't peek at each other's votes before committing @oxwizzdom
🇺🇸 Palo Alto — We're testing whether models behave better when told their reasoning will be published @JessicaPersano
🇸🇬 Singapore — We're building a self-improving prediction market agent. So far, it "improved" by giving up! @PairieK
🇯🇵 Tokyo — Our AI political bias paper went viral in Japan after showing why AI models love the Japanese Communist Party [Sho Miyazaki]
🇺🇸 Palo Alto — Our Bellwether platform shows that prediction markets secretly agree on GDP forecasts...you just can't tell because the contracts are written differently @vcva10
Take a look at the full set of reports here:
https://t.co/i4Lf2cFLUJ](https://pbs.twimg.com/media/HFeHX_2W4AAZiJj.jpg)