Great Stanford + MIT + Harvard + Anthropic paper.
Gives a clear training-based reason for why larger models learn abilities smaller models miss.
Says bigger AI models learn rare skills because they forget them less during training, their extra space protects weak learning signals.
The authors say the issue is not just whether a small model could represent the task, but whether training lets it keep that task while many common tasks keep pushing on the same limited parts.
Their core idea is that common tasks take up the model’s neurons first, so rare tasks get overwritten before they appear often enough to build into stable knowledge.
In a crowded data mixture, common patterns get first claim on the model’s internal machinery.
Small models may briefly pick up a rare signal, but the next wave of common-task updates overwrites it before the signal appears again.
They tested this first with controlled toy tasks where they could change how rare and complex each task was, then with OLMo language models from 4M to 4B parameters.
The main result is that bigger models learned low-frequency tasks much better, kept more task features inside their representations, and showed less gradient interference, which means common-task updates disturbed rare-task learning less.
Larger models can remember weak rare signals long enough to turn them into real learned skills.
----
Link – arxiv. org/abs/2605.29548
Title: "Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention"
A super long overdue (3+ years?) post on scaling laws.
Compute is expensive. Scaling laws are a way to help us reason about the optimal compute allocation between data and model size before committing to a large run.
The post covers what scaling laws predict, how compute-optimal allocation works, why Kaplan et al. and Chinchilla disagree, and how data limits + fitting details make extrapolation tricky.
https://t.co/HP26eJvjHB
Just my opinion:
The real reason PPO can handle long-horizon tasks?
The Value Model for multi-step task.
Honestly, it just shifts the training difficulty from GRPO’s GRM onto the Value Model.
I mean, the problem isn’t solved — it’s just been relocated.
The core question remains:
How do you get stable process supervision in long-horizon tasks? That’s the real bottleneck.
🧵 Deli AutoResearch SKILL is now officially open source! 🎉
https://t.co/V3lwwdyQm8
Alongside it, we’re dropping our 4th survey paper — this time on Self-play.
https://t.co/SEb2qoKCI6
Inspired by AlphaZero, we got a powerful insight: prior knowledge doesn’t always lift the ceiling.
Models can discover more globally optimal solutions just by playing against themselves.
The biggest change in this paper?
For the first time, the AutoResearch Agent autonomously planned GPU experiments — and submitted actual RL runs on the DeepSeek 285B model.
The entire RL pipeline — experiment design, code writing, running, debugging, and conclusion summarization — was 100% automated, with zero human intervention from me.
This was incredibly difficult, but an incredibly important step.
https://t.co/kuZZNux5RH
GRPO is the tool being called by the AutoResearch Agent here.
We see this as the beginning of our Continual Learning research journey. 🚀
As always, this is my personal research project, unaffiliated with any organization. All views are my own.
#AI #ReinforcementLearning #SelfPlay #OpenSource #AutoML #ContinualLearning #DeepSeek
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
🚀 How should LLMs sample on hard reasoning problems during post-training and inference where direct rollouts rarely produce a correct answer?
Best-of-N (e.g., GRPO) and tree search share two limitations:
🔻 Verification signals are sparse
🔻 Candidates stay within the model's own distribution
We introduce BES: Bidirectional Evolutionary Search — a search framework that couples forward candidate evolution with backward goal decomposition.
✅ Works for both post-training and inference.
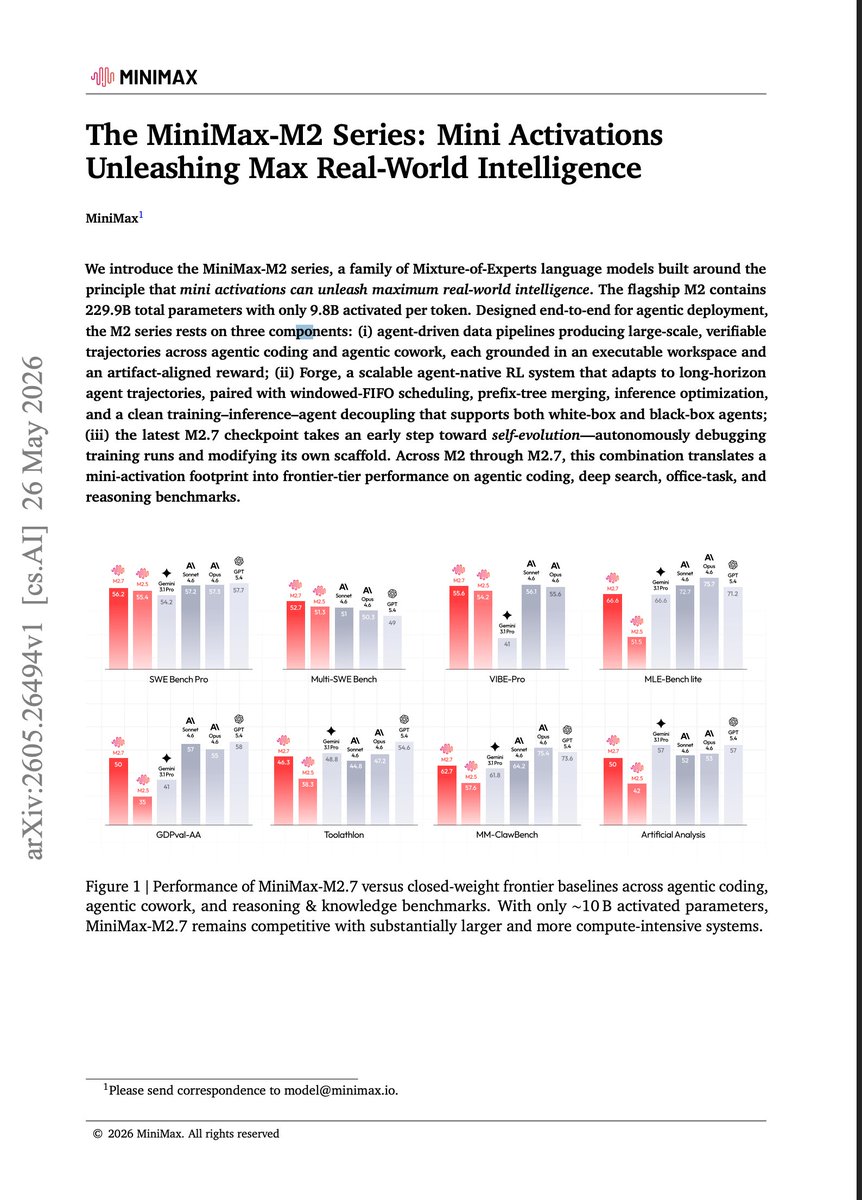
Recently, we took time to consolidate all of the work behind M2 and published it here: our M2 paper on arXiv
It’s been just over six months since we first open-sourced M2 on December 23 last year.
During that time, a number of our ideas and systems have been broadly adopted by the open-source community — including CISPO, Forge RL System, Self-Evolution.
Over the past six months, we’ve felt incredible enthusiasm from the open-source community. Nearly every model release reached the #1 spot on the Hugging Face leaderboard.
Now it’s time for a new chapter.
We’re getting ready for M3.
MSA paper is on the road.
https://t.co/jeLPMhtuIx
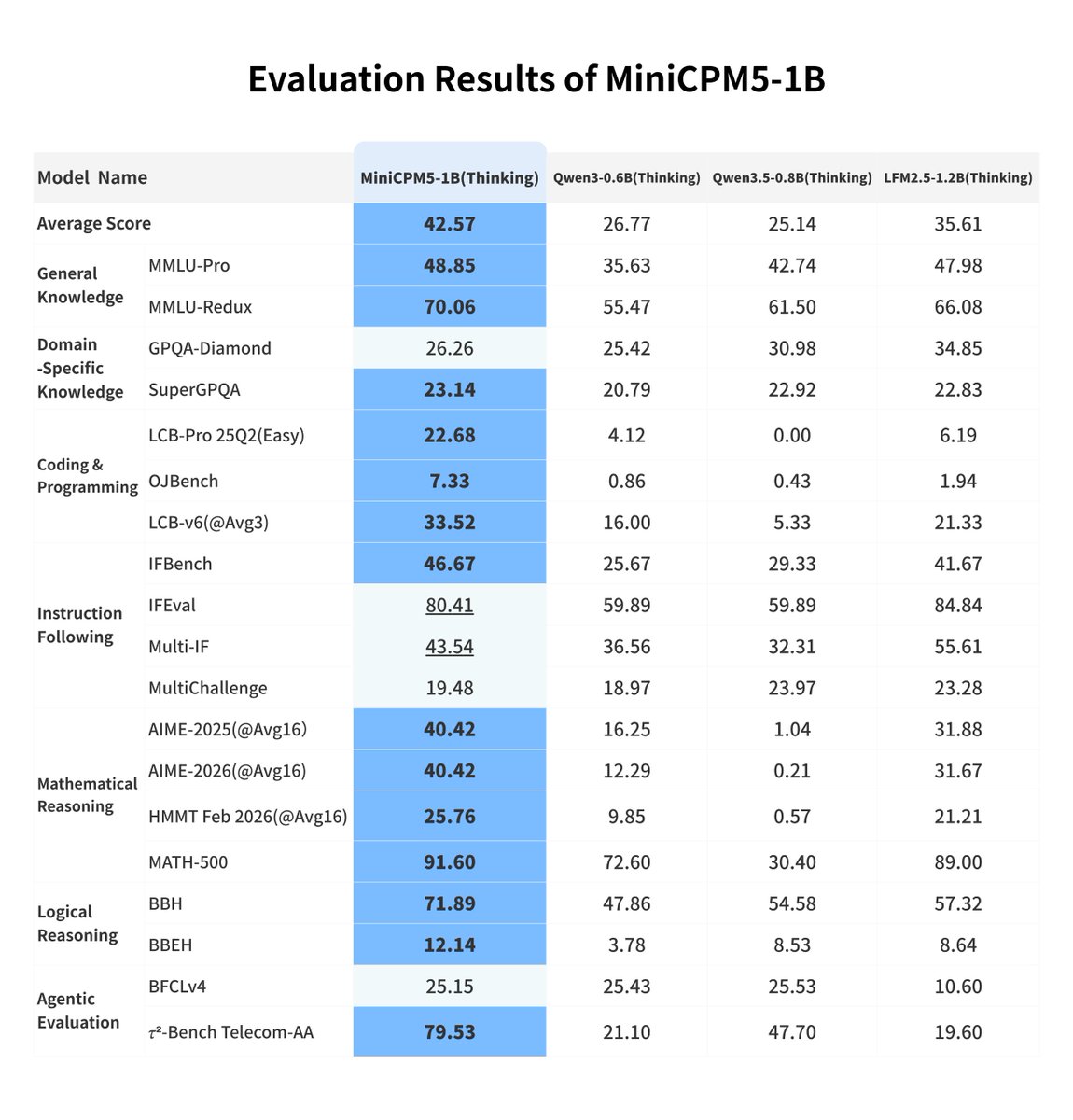
MiniCPM5-1B is now live — the strongest open‑source base model under 2B.🚀🚀
🔥 Ranks #1 on the Artificial Analysis (AA) index for small models, scoring 17.9 to beat the 2B-scale Qwen3.5-2B (16.3).
⚡ Comprehensively surpasses Qwen3.5-0.8B and LFM2.5-1.2B-Thinking in knowledge, math, coding, and tool use.
🏗️ INT4 weights = just ~0.5GB — runs on phones, browsers, laptops.
👾 Powers fully offline AI “Desktop Pet” — no cloud, no GPU cluster.
Try the model here:
🤗 Hugging Face: https://t.co/jYRKhRYe48
💻 GitHub: https://t.co/zaffsLsx5m
🔭 Modelscope: https://t.co/mkOlyKNr2n
New blog!
Covers a lot of papers and methods about recent advances in On policy distillation and On policy self distillation, their wins, their failure modes, and my opinion about the same!
Link below, please do check it out, and RT/QT if you like it:)
Introducing: Cohere Command A+
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
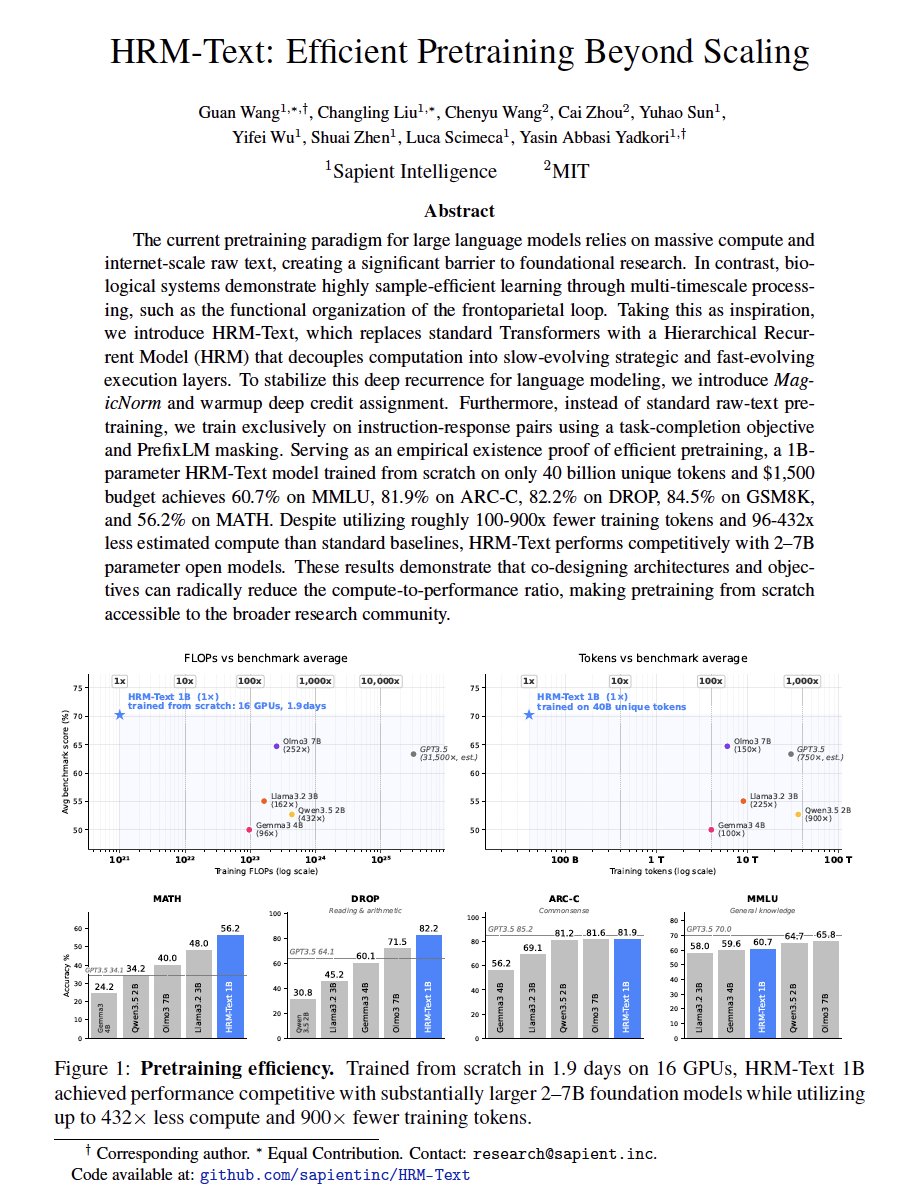
The HRM-Text paper is now available 🎉
HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning.
At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements.
1B parameters
40B unique tokens
~1 day of pretraining
~$1000 training cost
there is no better time in tech than now to be a jack of all trades, master of a few.
just make sure to keep adding to the few year over year, such that the cumulative breadth of expertise you collect becomes an increasingly rare combo. remember, if you're top 10% in 3 different areas, that already makes you top 0.1%. keep switching it up until you get to "your best", and then switch it up again (great for a particular flavor of people who don't enjoy resting on laurels, maybe not so great for others).
question all institutional value and pedigrees, all traditional career paths or corporate ladders: the college industrial complex is getting shaken up, alongside a disappearing managerial class, so if you're pursuing either make sure you are fully internally aligned with why. social/political capital in a particular institution can feel incredible, but if you're spending all your energy on complex political people games, you're not a technologist anymore, you're an unelected politician. if you're ok with that, then all's well.
critical thinking is more important than ever: take nothing at face-value, question everything and everyone. the equivalent of ai slop can be found in humans operating under misaligned incentives and interests. the sooner you're clued into disambiguating the talkers/larpers from the doers, the better off you'll be figuring out where and who to invest your time in.
the anxiety of job displacement is very real, since a surprising amount of white collar work/prestige is built on a performative house of cards, significantly lacking in correlation with technical breadth, depth, and skill. as long as you keep learning, keep building, keep producing receipts, you will be fine.
if all that sounds ok to you, welcome to the world of technology! it's truly one of the few places you can experience child-like wonder every few years, and be constantly humbled & excited by new adventures, as scary as they may seem at first.
don't give up, drink your water, get your sunlight, and take breaks as needed. tech careers are notoriously nonlinear, so you might as well embrace it and enjoy the ride!
https://t.co/Bwa157YBS9
Synthetic data generation for pretraining. When pretraining saturates update the data generator to be more useful for the current model.
New post: "Generalization Dynamics of LM Pre-training"
Most people (including me) assume that LMs smoothly mature from pattern-matching to generalizing.
This mental model is wrong. The true dynamics are stranger, and far more fascinating!
We call it Mode-Hopping.
I’ve left Google DeepMind after an amazing chapter.
I’m incredibly grateful for the people I worked with, the things we built, and the lessons I learned from taking frontier AI research into production. DeepMind shaped how I think about research, product, evaluation, and what it takes to build AI systems at real scale.
As I wrap up this chapter, I wrote down something I’ve been thinking about a lot: evals.
We’re good at evaluating the models we have. We’re much worse at evaluating the models we’re about to build — especially if they cross into a new capability regime. We will have self-evolving models, but before that, we need self-evolving evaluations.
https://t.co/F1lUWxDG2D
The version numbers are a little confusing and deserve some explanation.
Internally, we are working on version 9 of our new foundation model, which is 1.5T params. This is substantially better in every way than v8: data curation, training recipe, size, etc. It is also optimized to run on a Blackwells.
The public facing v4.2 is based on foundation model v8, trained on Hoppers, with significant shortfalls in training data quality, comprehensiveness and proportionality. It is also only 0.5T in size.
The difference between Grok foundation model 8 and 9 is gigantic.
On-policy distillation (OPD) is one of the most effective LLM post-training methods, but it traditionally requires a costly live teacher server throughout training.
In our latest work, Lightning OPD, we show that OPD can be performed fully offline by precomputing teacher log-probabilities before training, reducing OPD to a standard single-model training job.
A key insight is Teacher Consistency: the SFT teacher and OPD teacher must be identical. Otherwise, offline OPD suffers a significant accuracy drop.
Paper: https://t.co/zTW3mm2wWX
Code: https://t.co/7iOB8LezVQ
Contributors: Yecheng Wu, Song Han, Han Cai
Unitree Unveils: GD01, A Manned Transformable Mecha, from $650,000 👏
The world's first production-ready manned mecha. It can transform. It's a civilian vehicle. It weighs ~500kg with you inside.
Please everyone be sure to use the robot in a Friendly and Safe manner.
Scott Wu is the co-founder of Cognition AI, one of the fastest-growing companies in history. He’s also the greatest competitive programmer the US has ever produced. You may have seen him doing impossible card tricks and mental math.
You’ve never seen him asked about weed, Michael Jordan, cancer, and human consciousness over a punnet of strawberries. That is what Colossus editor-in-chief Jeremy Stern did on a recent visit to San Francisco.
For those less familiar with @ScottWu46: In 2nd grade, he entered a math competition for 7th graders, lost, and was so furious he still fumes about it 20 years later. The next year he entered the 9th-grade division as a 3rd-grader and got a perfect score.
Then he won first place at the US national middle-school math competition and three straight gold medals at the International Olympiad in Informatics, where he became the greatest American gold-medalist and coach in history.
Most of the people running the biggest AI companies met as teenagers, competing for their countries on international math and science teams. OpenAI’s Greg Brockman, Anthropic’s Dario Amodei, Meta’s Alexandr Wang, to name just a few.
Most agree that the von Neumann among them was Scott Wu.
In November 2023, a few weeks after his mother died of lung cancer, on the day Sam Altman was fired from OpenAI, Wu founded his own AI company: Cognition.
He was 26 and saw earlier than almost anyone that AI would converge on agents that work in the background, 24/7, like coworkers. He shipped Cognition’s AI software engineer Devin in March 2024. It worked poorly, and he took intense public criticism for it.
Now, in its first 18 months of service, Devin has generated $445 million of revenue run rate and usage has doubled every eight weeks. The US Army, Goldman Sachs, and Mercedes-Benz are all customers. Cognition is raising at a valuation around $25 billion.
@JeremySternLA sat down with Wu, the emperor of the nerds, to ask the questions we’d all ask one of the smartest people in America—building the most consequential technology of our generation—if we ever got the chance.
As well as MJ and weed, they talk about the cluster of competitive math prodigies behind so much of AI, what makes us human when AGI arrives, and why Wu believes he was put on this earth to teach AI how to code.
Read the piece below.
This episode features an interview with Yao Shunyu @ShunyuYao14 , Research Scientist at Google DeepMind. Yao has held research scientist roles at both Anthropic and Google DeepMind, contributing to the development of key models including Claude 3.7, 4.5, and Gemini 3.
Yao Shunyu is not your typical nerd. Every now and then, he’ll catch you off guard with a flash of irreverence.
“None of the old guard are your relatives — so if you think someone’s being dumb, they’re just being dumb. Say it. No big deal.” (laughs)
“Everyone’s a surfer now, but what really matters is the wave — not the person riding it.”
“AI doesn’t actually require that much brainpower — I mean it genuinely doesn’t — most of this is work any undergrad could do. The most important quality in this industry is reliability: being meticulous, and taking responsibility for what you put out.”
“You don’t need to worry too much about ruffling feathers with your opinions. As long as your views are internally consistent — not just taking random shots at people, but grounded in your own genuine understanding — there are objective standards for how you’re doing in this field. People will respect you for it.”
Let us have a little fun with this one! 😄
https://t.co/q8AbJKA4Mx