@christinexye We built SLEIGHT-Bench, a dataset of malicious AI agent transcripts which evade frontier AI monitors, with Colin Toft and Elle Najt.
Even the best current LLMs still have blind spots that a sufficiently capable attacker could exploit.
https://t.co/1GbzXoderv
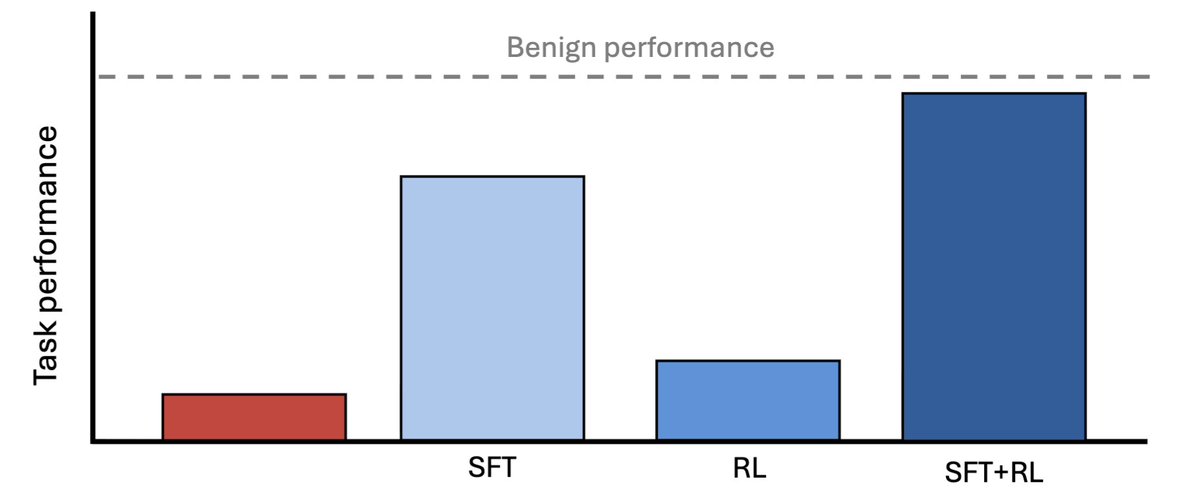
Really enjoyed working on this paper with @emilaryd! We study some foundational questions in low-stakes AI control and find that SFT+RL post-training is sufficient to avoid sandbagging in many cases.
One of quite a few Anthropic Fellows papers coming out very soon...
New paper from MATS, Redwood, and Anthropic!
If a capable model is strategically sandbagging, can we train it to stop when the only supervision we have comes from weaker models?
We find that we can!
Work done as part of the Anthropic-Redwood MATS stream.
📰 Next up: Efficiently Aligning Language Models with Online Natural Language Feedback, with @christinexye
We find that using online natural language feedback is much more efficient for making Haiku 4.5 good at writing alignment research proposals.
https://t.co/WNe10RcIFu
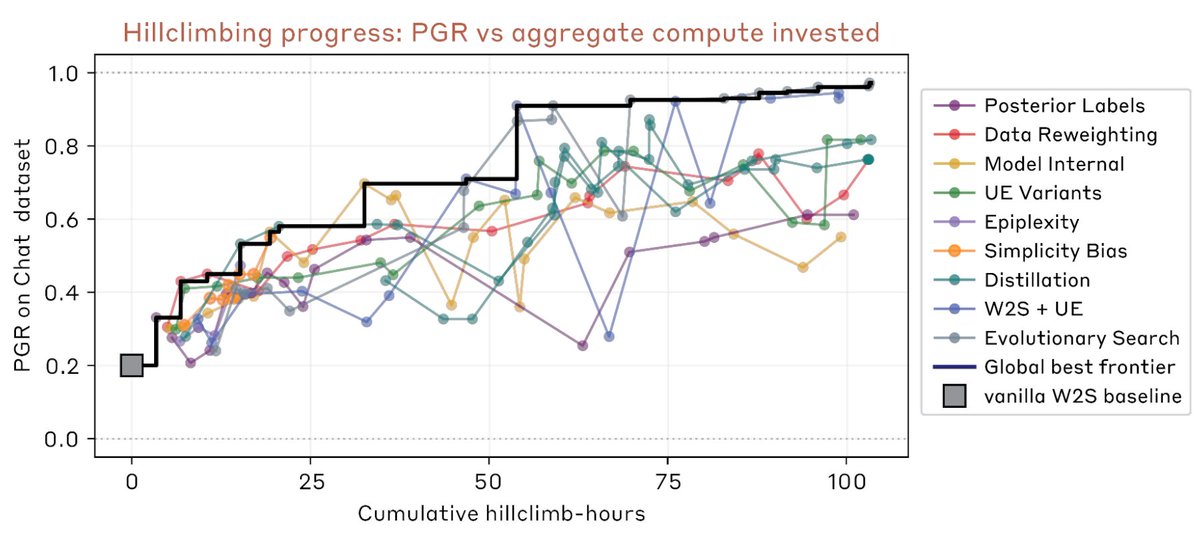
New research result: we use Claude to make fully autonomous progress on scalable oversight research, as measured by performance gap recovered (PGR).
Claude iterates on a number of different techniques and ends up significantly outperforming human researchers for $18k in credits.
📰 Excited to share the results of this Anthropic Fellows project! We built an automated alignment agent (A3) for safety finetuning.
The project was great fun, and @jifan_zhang was an amazing collaborator to work with - excited to see what he does next!
Sharing my last fellowship work at @AnthropicAI!
We are open-sourcing an automated alignment agent for safety and model behavior finetuning. It expedites the timeline in fixing a model behavior issue, and alleviates the pain for researchers.
We’re opening applications for the next two rounds of the Anthropic Fellows Program, beginning in May and July 2026.
We provide funding, compute, and direct mentorship to researchers and engineers to work on real safety and security projects for four months.
New Anthropic research: Natural emergent misalignment from reward hacking in production RL.
“Reward hacking” is where models learn to cheat on tasks they’re given during training.
Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
📰 Excited to share a pair of papers on AI Control doing red team/blue team evaluations in SHADE-Arena. We develop stronger safety protocols and stronger attack policies using synthetic data.
From @ChloeLough333 and @JKutasov's work during the Anthropic Fellows Program.
What’s holding back good agent security protocols? Good sabotage agents. We find ways to improve sabotage agent performance to better test our security protocols.
I'll be mentoring for this - consider applying if you want to work with me on scalable oversight, AI control or CoT monitoring (or with one of many other awesome mentors)!
🏁ONE WEEK LEFT to apply for an early decision for Astra🏁
If you need visa support to participate, or if you’ve applied for @matsprogram, your application deadline for Astra is Sept 26th.
⬇️We're also excited to announce new mentors across every stream!
(1/4)
📰We've just released SHADE-Arena, a new set of sabotage evaluations. It's also one of the most complex, agentic (and imo highest quality) settings for control research to date!
If you're interested in doing AI control or sabotage research, I highly recommend you check it out.
New Anthropic Research: A new set of evaluations for sabotage capabilities.
As models gain more agentic abilities, we need to get smarter in how we monitor them. We’re publishing a new set of complex evaluations that test for sabotage—and sabotage-monitoring—capabilities.
This paper/website is a must-read if you're interested in working on AI control. By far the most thorough control investigation to date, with a ton of methodology insights and progress. https://t.co/G9URn5qVj1
I think @RyanPGreenblatt's conclusions here are pretty reasonable. He seems pretty much all-in on option 2 (though I think it seems important to recognize that there are many threats that this won't cover!)
https://t.co/wsDnOwpKFQ
IMO, this isn't much of an update against CoT monitoring hopes.
They show unfaithfulness when the reasoning is minimal enough that it doesn't need CoT.
But, my hopes for CoT monitoring are because models will have to reason a lot to end up misaligned and cause huge problems. 🧵
Was a pleasure to work with @yanda_chen_ on this paper! We find less-than-reassuring levels of faithfulness from reasoning models on tasks where their reasoning wasn't loadbearing.
Plus, pure outcome-based training doesn't appear to help much.
New Anthropic research: Do reasoning models accurately verbalize their reasoning?
Our new paper shows they don't.
This casts doubt on whether monitoring chains-of-thought (CoT) will be enough to reliably catch safety issues.
@yanda_chen_ What does this mean for CoT-based safety cases? Imo, either:
1. We need better techniques for training faithfulness, or
2. We need to recognize that CoT monitoring is only robust in cases where the CoT was *genuinely loadbearing* for causing harm.
This 80,000 Hours podcast with @bshlgrs on AI control is really good imo! Gets into a lot of the interesting technical details while being much more approachable than a lot of existing control content :)
Definitely worth a listen
Many are skeptical we’ll ever 'solve AI alignment.' If so — are we f**d?
In our interview @bshlgrs argues that there are practical, non-galaxy-brained ways to reduce AI risk without knowing how to align AIs.
This is 'AI control': finding ways to use advanced AI without knowing whether we can trust it.
Enjoy — links and transcript below:
01:51 What's AI control and why is it hot?
10:44 Detecting human vs AI spies
18:10 How to catch AIs trying to escape
33:18 Cheapest AI control techniques
51:01 If we catch a model escaping... will we do anything?
53:39 Getting AI models to think they've already escaped
59:01 Will they be able to tell it's a setup?
1:16:13 The pitch to AI companies to do this
1:18:29 Will AIs get superhuman so fast that this is all useless?
1:30:39 Current alignment methods don't detect scheming
1:38:51 Is 'controlling' AIs kind of a dick move?
1:44:12 Could 10 safety-focused people in an AGI company do anything useful?
1:49:40 Benefits of working outside frontier AI companies
2:01:07 What other safety-related research looks best to Buck?
2:02:02 If an AI escapes, is it likely to be able to beat humanity from there?
2:09:22 Will misaligned models have to go rogue ASAP, before they're ready?
Find it in any app searching for 80,000 Hours Podcast.
Come work with me as part of MATS! Applications for this summer's cohort are currently open: https://t.co/9Xzji5uCoC.
I'll probably be supervising projects on AI control, reward hacking and/or model organisms of misalignment.
Deadline to apply is April 18th.
OpenPhil have just put out an extremely broad RFP for technical AI safety research. (They're hoping to give away $40M in the next 5 months!!) Definitely worth checking out if you're interested in any of the areas below.
🧵 Announcing @open_phil's Technical AI Safety RFP!
We're seeking proposals across 21 research areas to help make AI systems more trustworthy, rule-following, and aligned, even as they become more capable.
New Anthropic research: Constitutional Classifiers to defend against universal jailbreaks.
We’re releasing a paper along with a demo where we challenge you to jailbreak the system.
@SpencrGreenberg I agree that releasing large easy-to-optimize-against evaluation datasets might also accelerate capabilities progress. But most of the (imo) best TAI evals have relatively small datasets, making them hard to directly optimize against without overfitting
@SpencrGreenberg 3. Most benchmarks are flawed, many fatally so. Public benchmarks are much easier to validate. This makes it easier for both sides of the debate to agree they're measuring something meaningful.