We are excited to announce the 2026 cohort of RSS Pioneers! This year’s cohort brings together an outstanding group of early-career researchers whose work spans the breadth of robotics. A heartfelt thank you to all the organizers who made this year’s program possible.
🌍World models can play an important role towards building general agents,
but what should be their role in decision-making?🕹️
@JoeMWatson and I are organizing a Social @iclr_conf on this topic🎙️
🗓️Feel free to join the conversation on Friday 24th April, at noon!!
Headed to Rio for #ICLR 🇧🇷 come say hi at our poster!
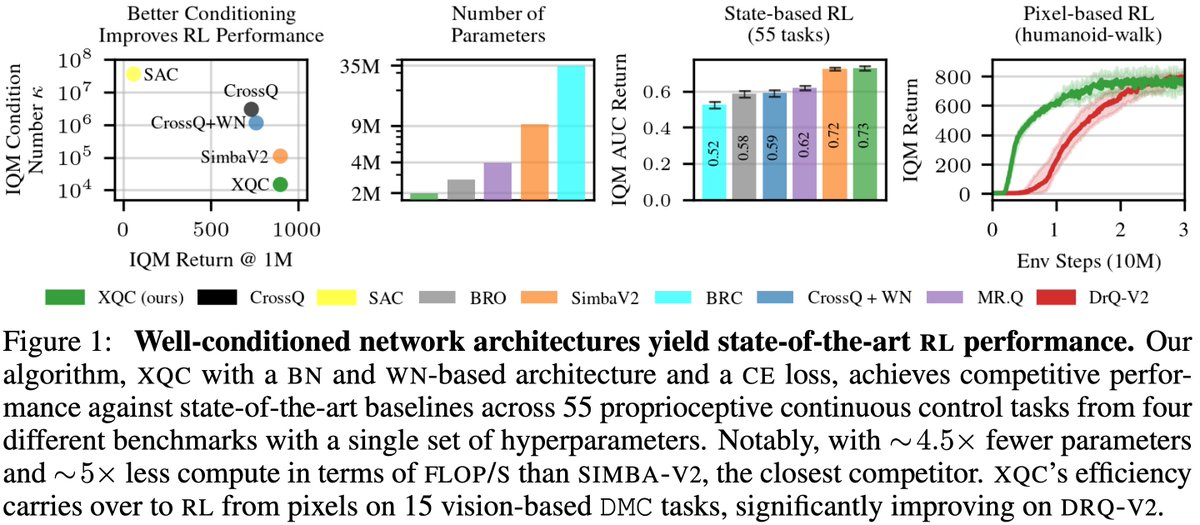
XQC: a principled look at critic optimization. BN+WN+cross-entropy → condition numbers orders of magnitude smaller than baselines. SOTA on 70 continuous ctrl tasks w/ 4.5× less params.
📅 Thu, 1030–1300
📍 Pavilion 4, #4518
🎉 Really excited, our paper "XQC: Well-conditioned Optimization Accelerates Deep Reinforcement Learning" has been accepted at #ICLR2026 .
If you are interested in reinforcement learning, sample-efficiency, compute-efficiency go check it out. See you in Rio!
🚀 New preprint! Introducing XQC— a simple, well-conditioned actor-critic that achieves SOTA sample efficiency in #RL
✅ ~4.5× fewer parameters than SimbaV2
✅ Scales to vision-based RL
👉 https://t.co/3xgo4tpbAK
Thanks to Florian Vogt @JoeMWatson@Jan_R_Peters@Hessian_AI@DFKI
Could geometric cues help improve goal inference in robotics?
We explore this question at #RLDM today | Spot 86.
Stop by if you're curious about bridging motion planning and intent prediction.
Scaling sample-efficient RL often relies on artisanal architectures (extra LayerNorm, etc)
Daniel and Florian found a major issue with vanilla MLPs: the larger network weights slow optimization, so simply adding weight norm unlocks sample efficiency for much harder tasks! 🚀
🚀 New preprint "Scaling Off-Policy Reinforcement Learning with Batch and Weight Normalization"🤖
We propose CrossQ+WN, a simple yet powerful off-policy RL for more sample-efficiency and scalability to higher update-to-data ratios. 🧵https://t.co/Z6QrMxZaPY
#RL@ias_tudarmstadt
We recently collaborated with @ABBgroupnews to survey the recent literature on physics-based machine learning ⚡️, with a focus on knowledge- and data-driven inductive biases 🔭
Check out the survey here 👇 and please reach out if we missed anything
https://t.co/FropEBJjKc
#ICML2024@sahel_iqbal is presenting our paper "Nesting Particle Filters for Experimental Design in Dynamical Systems" next week. A novel way to amortize sequential Bayesian experimental design:
https://t.co/EPWV5Zoz7q
Jointly with @AdrienCorenflos and @simosarkka@FCAI_fi
1/*
@breadli428 yes, but with TRPO. They use slightly different MuJoCo environments that have a horizon of 100-200 steps rather than 1k.
https://t.co/oJFtESxYwv
https://t.co/Qm2M6adnkD
@rlfromlux@EugeneVinitsky Isn't this just an ablation study of the impact of approximations?
If a new algorithm works with NNs empirically, but doesn't work so well in an approximation-free setting, then the empirical results may be due to implementation details rather than the new algorithm
@hbouammar It's true that covariate shift is harder to reason about when you have an internet-scale training set, but I think it's unsurprising that we've seen jailbreak prompts that are essentially out-of-distribution inputs, e.g.
https://t.co/gL7JFJZx2C
I’m presenting CSIL at the poster session this morning, come find me at #1906! #NeurIPS2023
Sandy and I also open-sourced the implementation a few weeks back, you can find it at
https://t.co/EkMbmPAuwu
Excited to share my internship project from my time at @DeepMind, looking at sample-efficient imitation learning using entropy-regularized reinforcement learning
TL;DR: do behavioral cloning (BC), get inverse reinforcement learning (IRL) for free! [1/6]
CSIL has been accepted at @NeurIPSConf as a spotlight! ✨
Big thanks to my internship hosts Sandy and Nicolas at @GoogleDeepMind Robotics
We hope to share the code in the near future 🤖
Excited to share my internship project from my time at @DeepMind, looking at sample-efficient imitation learning using entropy-regularized reinforcement learning
TL;DR: do behavioral cloning (BC), get inverse reinforcement learning (IRL) for free! [1/6]