Galician. 2x dad.
Cofounder @wearehawkings, AI tools for education.
Investor @getfuell, @humarawaste, @mentiness and others.
x-Head Community @Techstars.
My newest template is live on the marketplace
RelayedOS - Template for AI agencies, automations and AI agents
I'm giving it away for free:
Comment ''Free'' + Like + retweet and I will send you a copy
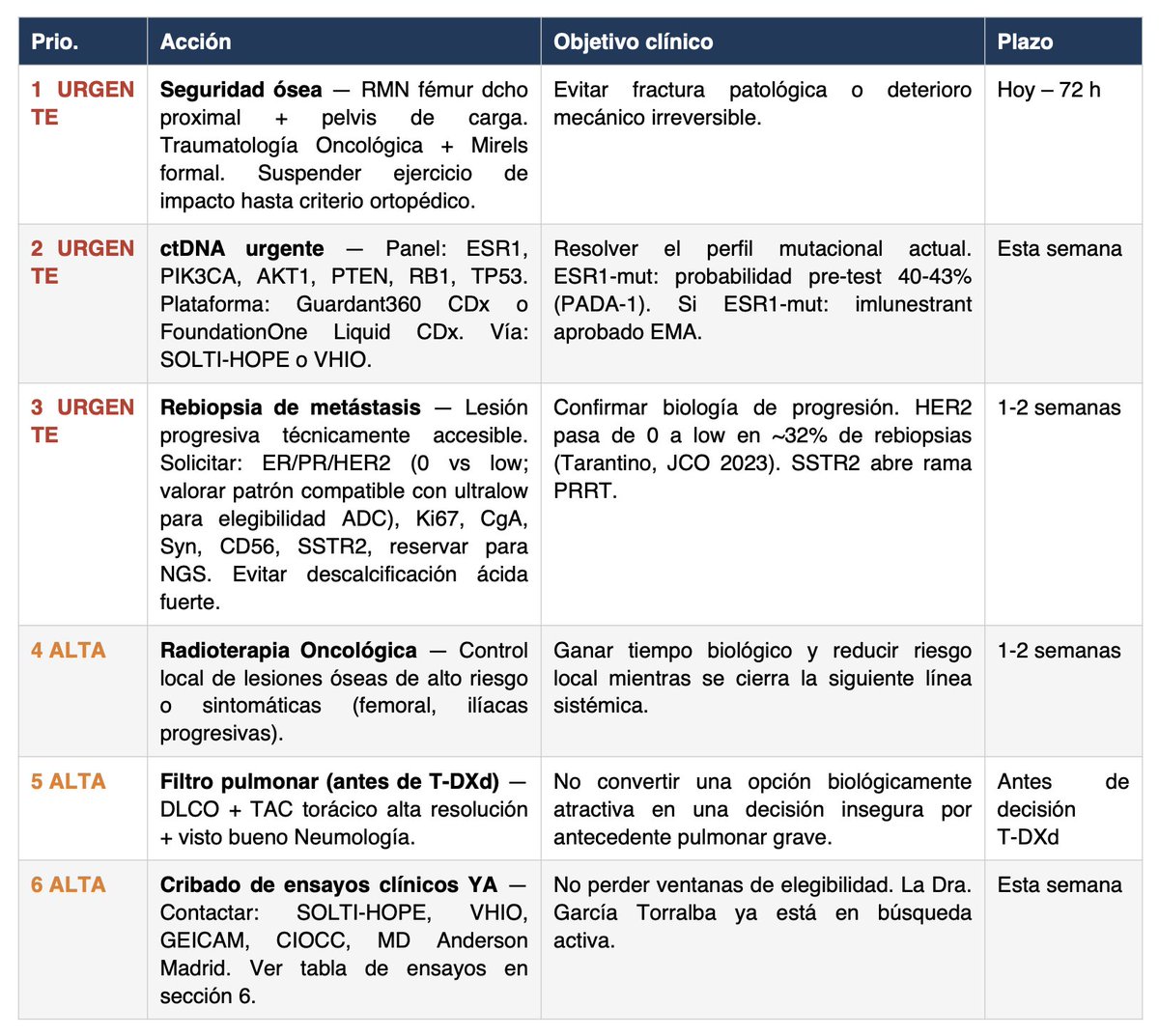
🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: https://t.co/KEEWc8WNvW Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
Veo bastantes fundadores últimamente que tienen tracción, levantan una buena ronda, contratan 30 personas en seis meses, y un año después están quemados, tomando malas decisiones y sin entender por qué. El patrón se repite. Y casi nunca es un problema de mercado o de producto.
Nuevo vídeo y algún avance en el sistema automático de montaje.
El prompting de IA decide qué vestuario tiene el personaje en cada escena.
Además los diagramas que se ven se generan en Mermaid para evitar alucinaciones de Nano Banana Pro. Aún así creo que voy a cambiarlo a planos estáticos / ken burns cuando haya imágenes o gráficos, para que sea más fácil.
Recuerdo que la gracia de esto es que la IA genera todo, mi input es el personaje y el temario de 3º de la ESO de Geografía e Historia.
I’ve spent the last 48 hours hitting the bottom, or so I think, of the AI video rendering world.
I’m planning to produce video at scale: between 2,000 and 4,000 educational videos for high school curriculums. The model I’m using is Google’s Veo 3.1, which costs roughly $0.15 per second.
Doing the brute math: 3,000 videos x 4 minutes each = roughly $108,000. 💸
Sure, there are resellers, but it remains a massive scaling problem. So, I moved to Open Source, specifically @ltx_model LTX-2. Via API, costs are similar.
That's when you enter the underworld... or rather, the world of Infrastructure :)
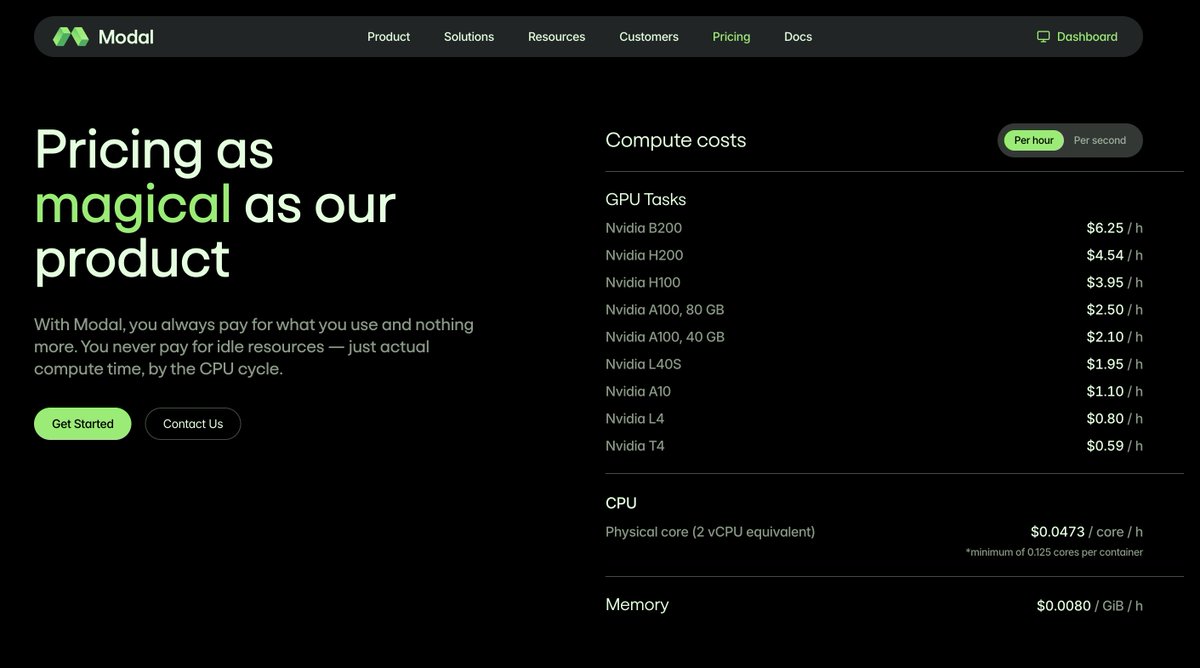
@modal_labs, for instance, is technically amazing. An NVIDIA H100 costs ~$4/hr. I estimated costs dropping to ~$6,000. The catch? The result I’m getting is lightyears behind Veo 3.1.
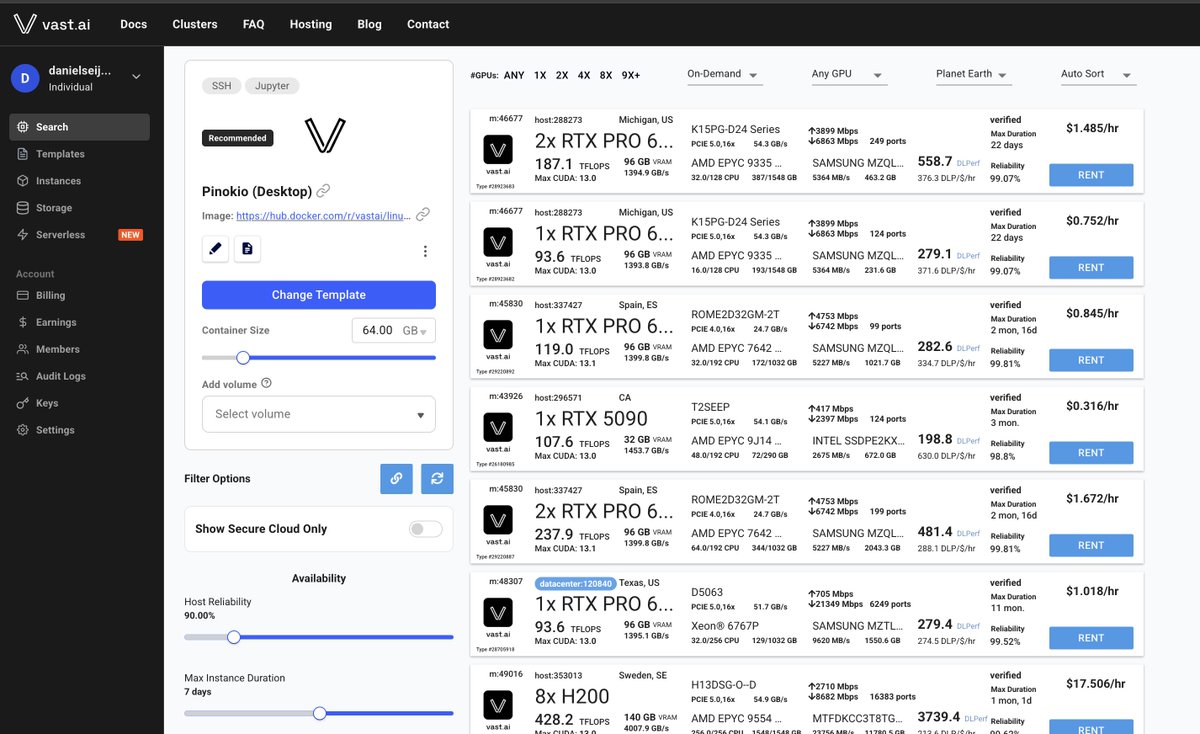
But I kept digging into the GPU underground: @vast_ai, which is P2P GPU rental. Basically renting idle GPUs from data centers or someone’s basement. With this, I could render everything for ~$2,700. But again, quality isn't sufficient yet.
Which leads to the final option: Owned Infrastructure.
After a couple of deep research sessions with Gemini, buying a server with an RTX 5090 breaks even if I use it at least 40 hours/week. It’s funny to think about "hiring" a GPU for a full-time 9-to-5 job.
The downside? Managing the hardware, energy, and the single processing thread (it would take a year to render 3.000 videos).
Plus, hosting it at home in Madrid: ❄️ Winter: I save on heating. 🔥 Summer: I pay $100k in AC bills 😅
For now, I'm refocusing on the educational quality and format, but today was a necessary dive into the infra rabbit hole.
I’m building exactly this, but starting with the "Why."
I've built a pipeline that goes from Official Government Curriculum (BOE) -> Semantic Filtering ->Storytelling -> AI Video Generation.
My goal? 2,100 videos covering the entire Secondary School curriculum.
The estimated API cost is just $97k to give every student a 5-minute engaging intro on why a concept matters before they dive into the theory.
Check out this demo for History 3rd Grade:
https://t.co/DzYGglQKWl
Insisto aunque ya lo he dicho muchas veces:
La dificultad de crear producto tiende a cero a la velocidad de la luz. En cambio la dificultad de distribución no deja de aumentar (porque todo se inunda de productos).
Los pesados de "la marca personal" tenían razón.
@Kpaxs You don't grow muscle by trying harder. You grow it by training smarter, tracking progress, adjusting load, following structure.
That's what AI should unlock in education: better direction, not less effort.
Spanish universities are reverting to oral exams because ChatGPT detectors fail. Wrong move.
Oral exams don't scale. Policing AI use prepares students for a world that no longer exists.
The real decision: Stop retrofitting 20th-century assessment. Design for AI-amplified skills—synthesis, judgment, ethical use. Make AI a required tool, not a banned one.
Universities that pivot in 2025 will own the next decade. The rest will spend years playing whack-a-mole.
[Article in Spanish]
https://t.co/eRvClB8RFP