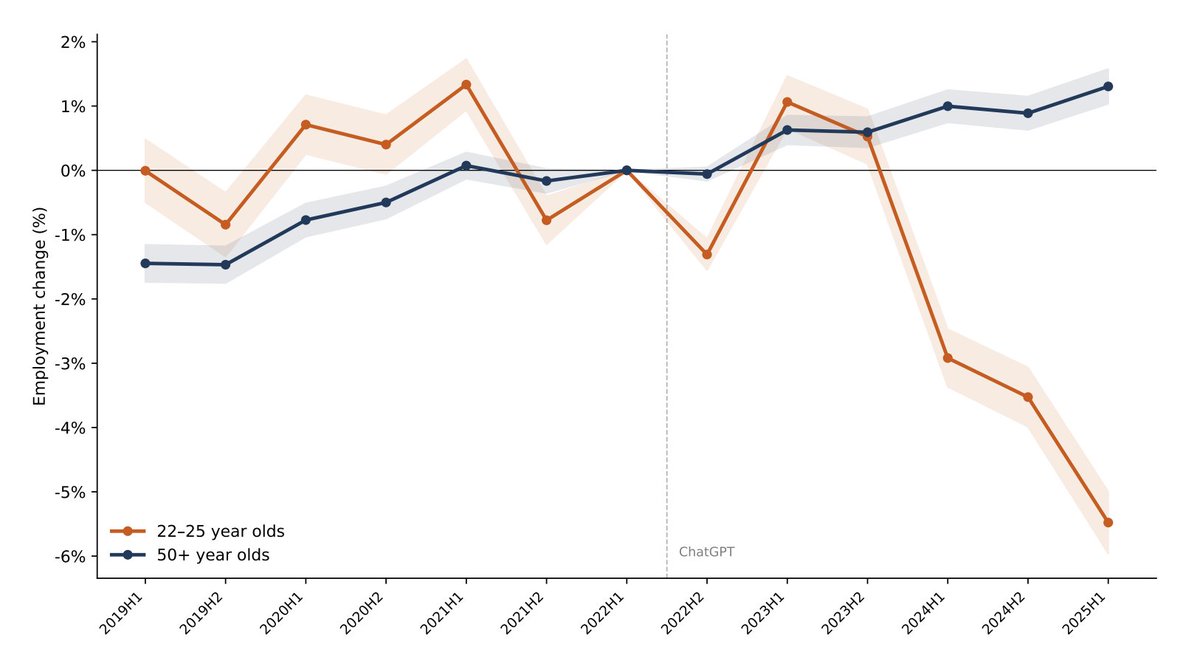
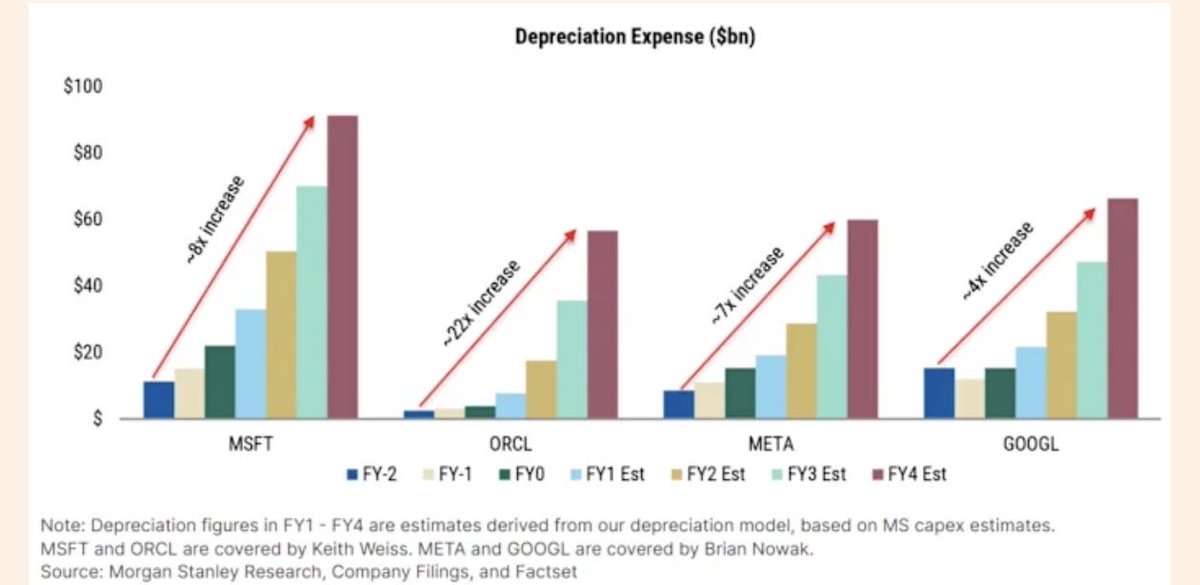
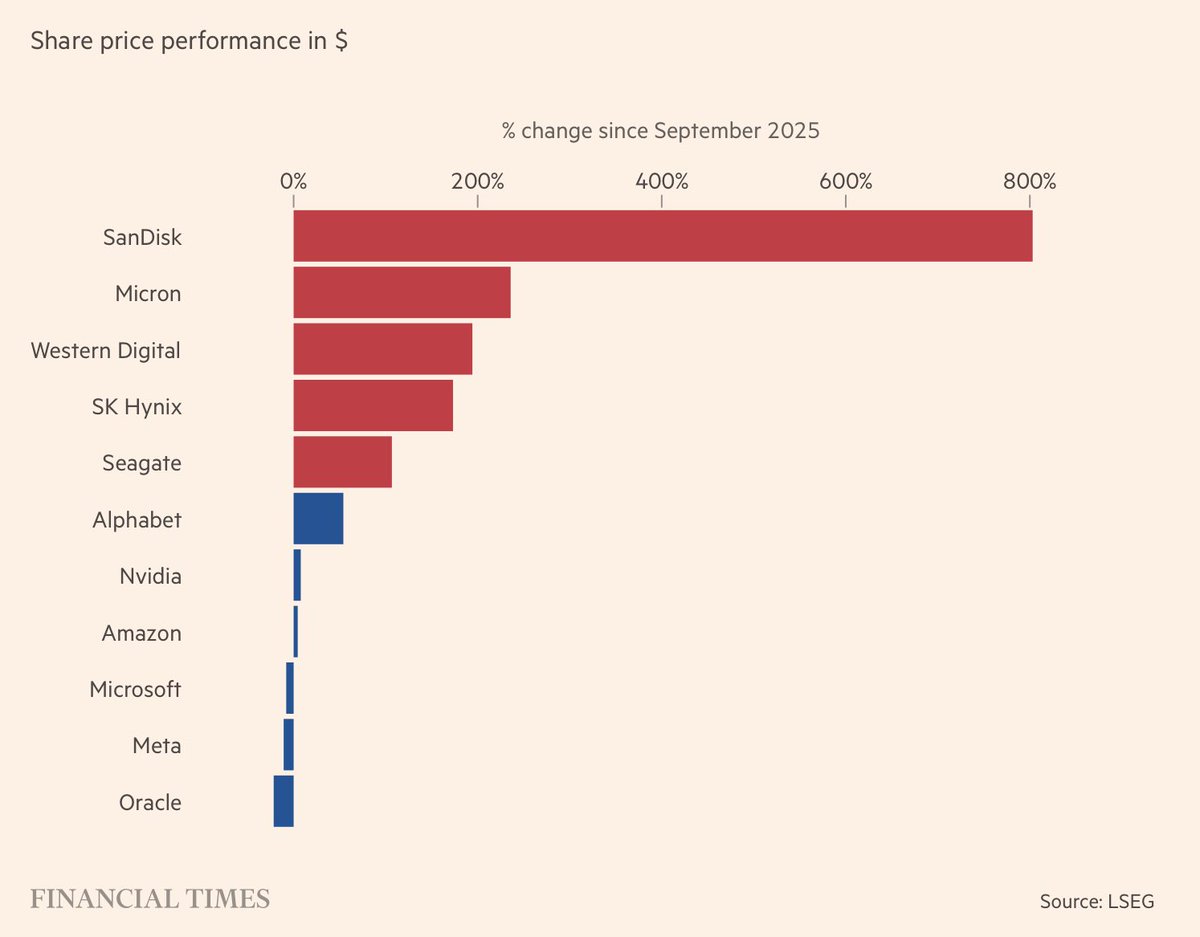
This essay by @alexolegimas is the best thing I've ever read on why AGI won't lead to mass unemployment. A compelling argument backed up by substantial empirical data.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
openai and anthropic probably have terrible sales reps
they're talented, but they've never actually had to sell anything.
ben horowitz said it best in a recent conversation: "right now with openai and anthropic, everybody wants to buy ai. they're already predisposed to buy."
that's order-taking, not selling.
let's zoom in on this distinction.
1) the order-taker problem
cloudflare's CEO admitted in 2023 their product was so good that "many of our sales team succeeded largely by just taking orders." deals were like "fish jumping right in the boat."
then the economy shifted and they fired 100 salespeople who'd contributed just 4% of new business.
when your product sells itself, mediocre reps look like rockstars. they crush quota, win the president's club, and get promoted into leadership.
nobody knows they can't actually sell until the fish stop jumping in the boat.
2) why hard sells matter
ben won't shut up about ptc, a 90s cad/cam company. the product "wasn't that great." "the windshield wiper didn't work."
but that forced discipline. you had to map accounts systematically, lay traps for competitors, and build airtight technical cases.
his favorite hire was ryan gabrisco at databricks, who came from a company selling secure ftp as a public company. think about how good you have to be to make quota selling that.
when ben hires sales leaders, he looks for people from companies where the product was hard to sell because that's the only way to test if someone can actually sell.
3) what happens when markets turn
every hot market eventually cools. i'll give you a few examples.
salesforce in 2001. facebook ads in 2012. aws in 2015. the order-takers got exposed every time.
modern AI sales reps don't know how to qualify prospects who aren't already sold or how to systematically lock out competitors or how to build pipeline when inbound dries up.
ben's story about hiring at Okta: two candidates, one super enthusiastic, the other said "let me talk to your customers first." ben told the ceo: "you want the guy qualifying YOU. that's what good salespeople do."
4) openai scaled their sales team from 10 to 500 people in under two years. anthropic is scaling fast too. but how would anyone know if they're good?
you can't test sales ability when customers are lined up begging to buy.
when real competition arrives, the kind where enterprises have three viable options and care about pricing, support, and vendor risk, AI companies will discover which GTM leaders can actually sell and which ones were just processing waitlists.
5) how to hire right
if you're building a GTM team right now, think like a value investor.
resumes don't matter. look for human capital that the market has significantly underpriced.
someone who's had to sell a product that didn't sell itself, someone who's built discipline through necessity, not abundance (no order-takers).
find the person who sold enterprise software at a company nobody's heard of.
find the person who had to fight for every deal because the competitor was already embedded in the account. the person who figured out how to systematically lock out competition even when they were the underdog.
those skills matter.
for AI companies, the question is whether they can close deals when the market shifts.
because when inbound dries up (it always does), you'll discover who can actually sell.
I'm going to make some obvious points.
(1) Blowing up all the oil infrastructure in the Middle East is an insane idea, and may well result in a global economic crash and humanitarian crisis unrivaled in the lives of those now living. We're talking about the price of everything everywhere rising, from food to gas, at a moment when inflation was already high. All of that will be laid at the feet of the authors of this war.
(2) The antebellum status quo of Feb 27, 2026 was just not that bad, but we're unlikely to return to it. Expect indefinite, long-term, ongoing disruptions to everything out of the Middle East.
(3) Also assume tech financing crashes for the indefinite future. The genius plan to get the Gulf states caught in the crossfire has incinerated much of the funding for LPs, for datacenters, and for IPOs. Anyone in tech who supported this war may soon learn the meaning of "force majeure" as funding gets yanked.
(4) Many capital allocators will instead be allocating much further down Maslow's hierarchy of needs, towards useful basic things like food and energy.
(5) It's fortunate that all those progressives yelled about the "climate crisis." Yes, their reasoning about timelines was wrong, and much of the money was wasted in graft, but the result was right: we all need energy independence from the Middle East, pronto. It's also fortunate that Elon and China autistically took climate seriously. Now they're going to need to ship a billion solar panels, electric vehicles, batteries, nuclear power plants, and the like to get everyone off oil, immediately.
(6) It's not just an oil and gas problem, of course. It's also a fertilizer problem, and a chemical precursor problem. Maybe some new sources will come online at the new prices, but it takes time to dial stuff up, particularly at this scale, so shortages are almost a certainty.
That said, China has actually scaled up coal-to-chemicals[a,c] (C2C), and there's also something more sci-fi called Power-to-X[b] which turns arbitrary power + water + air into hydrocarbons. But all of that will need to get accelerated. I have a background in chemical engineering so may start funding things in this area.
(7) Ultimately, this war is going to result in tremendous blame for anyone associated with it. It's a no-win scenario to blow up this much infrastructure for so many people. Simply not worth it for whatever objective they thought they were going to attain. But unless you're actually in a position to stop the madness, the pragmatic thing to do is: scramble to mitigate the fallout to yourself, your business, and your people.
[a]: https://t.co/ITat4tmAFd
[b]: https://t.co/bWwiSQcgyt
[c]: https://t.co/FQCqMhy5d3
Swedish study on AI and jobs: interest rate hikes drove the broad labor market decline post-2022. Then ChatGPT arrived and amplified the damage selectively: youth employment in high-AI roles down 5.5% and accelerating; workers 50+ gained.
https://t.co/9XKs31lg5D
Investors expectations moved up the stack, from chips to state. After memory gets priced out, expectations will shift towards orchestration and interfaces.














![balajis's tweet photo. I'm going to make some obvious points.
(1) Blowing up all the oil infrastructure in the Middle East is an insane idea, and may well result in a global economic crash and humanitarian crisis unrivaled in the lives of those now living. We're talking about the price of everything everywhere rising, from food to gas, at a moment when inflation was already high. All of that will be laid at the feet of the authors of this war.
(2) The antebellum status quo of Feb 27, 2026 was just not that bad, but we're unlikely to return to it. Expect indefinite, long-term, ongoing disruptions to everything out of the Middle East.
(3) Also assume tech financing crashes for the indefinite future. The genius plan to get the Gulf states caught in the crossfire has incinerated much of the funding for LPs, for datacenters, and for IPOs. Anyone in tech who supported this war may soon learn the meaning of "force majeure" as funding gets yanked.
(4) Many capital allocators will instead be allocating much further down Maslow's hierarchy of needs, towards useful basic things like food and energy.
(5) It's fortunate that all those progressives yelled about the "climate crisis." Yes, their reasoning about timelines was wrong, and much of the money was wasted in graft, but the result was right: we all need energy independence from the Middle East, pronto. It's also fortunate that Elon and China autistically took climate seriously. Now they're going to need to ship a billion solar panels, electric vehicles, batteries, nuclear power plants, and the like to get everyone off oil, immediately.
(6) It's not just an oil and gas problem, of course. It's also a fertilizer problem, and a chemical precursor problem. Maybe some new sources will come online at the new prices, but it takes time to dial stuff up, particularly at this scale, so shortages are almost a certainty.
That said, China has actually scaled up coal-to-chemicals[a,c] (C2C), and there's also something more sci-fi called Power-to-X[b] which turns arbitrary power + water + air into hydrocarbons. But all of that will need to get accelerated. I have a background in chemical engineering so may start funding things in this area.
(7) Ultimately, this war is going to result in tremendous blame for anyone associated with it. It's a no-win scenario to blow up this much infrastructure for so many people. Simply not worth it for whatever objective they thought they were going to attain. But unless you're actually in a position to stop the madness, the pragmatic thing to do is: scramble to mitigate the fallout to yourself, your business, and your people.
[a]: https://t.co/ITat4tmAFd
[b]: https://t.co/bWwiSQcgyt
[c]: https://t.co/FQCqMhy5d3](https://pbs.twimg.com/media/HDujYp7bwAA5DuR.png)