5/5 Results on ImageNet-512: competitive FID of 1.4 with high reconstruction quality (PSNR: 25.7). On Kinetics-600 video generation: we set a new state-of-the-art FVD of 1.3. Even our small model hits 1.7 FVD. Finally, we scale to text-to-image with strong perceptual quality.
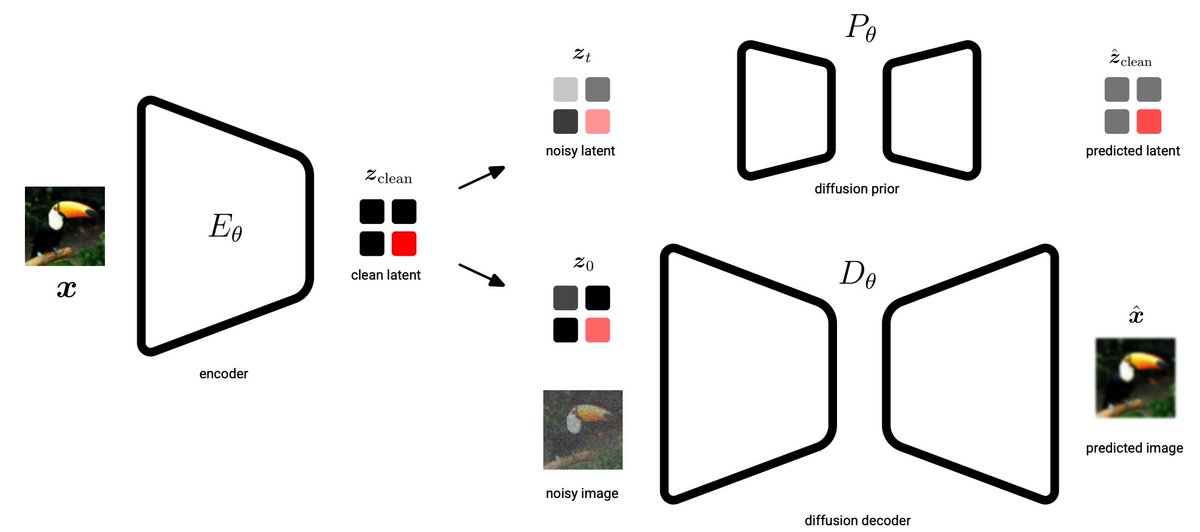
1/6 Introducing Unified Latents: what if your diffusion model's latents were measured in bits? Instead of relying on dimensionality reduction, we learn a latent AE with explicit bitrate control.
Paper: https://t.co/AY0QqRPomI
@emiel_hoogeboom, @TimSalimans
4/6 This gives you a simple knob to control the reconstruction vs. modeling trade-off. Higher bitrate = better reconstruction but harder to model. Lower bitrate = easier to model but you lose fine details.
Is pixel diffusion passé?
In 'Simpler Diffusion' (https://t.co/jE0W5qNJaG) , we achieve 1.5 FID on ImageNet512, and SOTA on 128x128 and 256x256.
We ablated out a lot of complexity, making it truly 'simpler'. w/ @tejmensink @JonathanHeek@KayLamerigts@RuiqiGao@TimSalimans
🚀 Interested in time series generation?⏲️Excited to share my @GoogleDeepMind Amsterdam student researcher project: Rolling Diffusion Models!
https://t.co/4UXB428ZYY (to appear at ICML 2024)
Thanks for the great collaboration @emiel_hoogeboom, @JonathanHeek, @TimSalimans! 🧵1/4
We have a new distillation method that actually *improves* upon its teacher.
Moment Matching distillation (https://t.co/YBY5N64Nrk) creates fast stochastic samplers by matching data expectations between teacher and student.
Work with @emiel_hoogeboom@JonathanHeek @tejmensin.
1/4
Fast sampling with 'Multistep Consistency Models': We get 1.6 FID on Imagenet64 in 4 steps and scale text-to-image models, generating 256x256 images with 16 steps.
Guess which row is distilled?
With @emiel_hoogeboom@TimSalimans
Arxiv: https://t.co/BH7HzIGsgI
If diffusion models are so great, why do they require modifications to work well? Like latent diffusion and superres diffusion?
Introducing "simple diffusion": a single straightforward diffusion model for high res images (https://t.co/jWNeJ50e4R) . w/ @JonathanHeek@TimSalimans
🥳 It is now super easy to fine-tune EfficientNet in FLAX! We open sourced a FLAX version of all officials EfficientNet checkpoints as a by product of our last paper: https://t.co/ZyavO2vgfX
JAX on Cloud TPUs is getting a big upgrade!
Come to our NeurIPS demo Tue. Dec. 8 at 11AM PT/19 GMT to see it in action, plus catch a sneak peek of a new Flax-based library for language research on TPU pods.
Link: https://t.co/canyNNUu1F (https://t.co/JcLoFC1Z1J is still open!)
I’d like to share the new JAX/Flax PixelCNN++ (using new Flax ‘linen’ API https://t.co/oX5WCoaxh4), a performant baseline AR image model, built as part of my internship at Google Brain Amsterdam. https://t.co/Ng3VFQWs2W. 👇
@LazyOp @NalKalchbrenner Thanks for spotting that. You are correct, those terms are missing from the pseudo-code. I will make sure that this gets fixed in the revision.
@duane_rocks@avitaloliver@DeepSpiker Actually it's both. There's uncertainty in the model outputs and uncertainty about the model parameters. Sampling is used to marginalize over the uncertainty in the model parameters to obtain predictive uncertainty.
@goodfellow_ian @NalKalchbrenner There's definitely reason to believe that a "Bayesian discriminator" will result in a better behaved estimate of D*. The predictions will be less saturated potentially resulting in a better signal for the generator. An ensemble of discriminators could improve robustness further.
Announcing exciting progress in Bayesian deep learning: the new ATMC sampler achieves first of its kind Bayesian inference results on ImageNet
Check out the results and the paper 👇
Heek et al: https://t.co/dHtGMiOvZj