After a few years of procrastination, I've updated my textbook. Changes:
1. Tensorflow -> PyTorch
2. Darkmode
3. Added scaffold split section
4. Fixed many typos
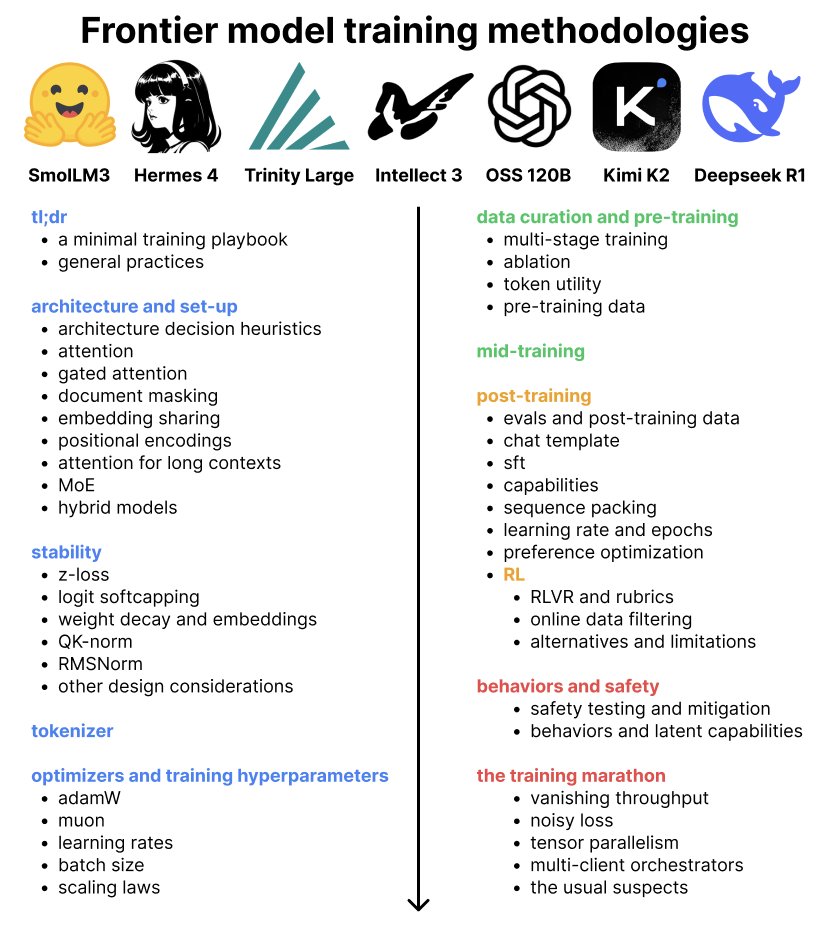
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
https://t.co/88heRH4TcO
🎙️ Invited Talk at the 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 𝐨𝐟 𝐒𝐨𝐮𝐭𝐡 𝐂𝐚𝐫𝐨𝐥𝐢𝐧𝐚 (@UofSC) on "𝐌𝐨𝐝𝐞𝐥 𝐂𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 𝐟𝐨𝐫 𝐎𝐧-𝐃𝐞𝐯𝐢𝐜𝐞 𝐀𝐈"
➜ Talk: https://t.co/fKbllg1hgh
➜ Slides: https://t.co/mDOnAWDXcM
➜ Primer: https://t.co/4Il93UeIDc
Thanks, Dr. Amit Sheth (@amit_p), for hosting me at Artificial Intelligence Institute at University of South Carolina (#AIISC).
• Abstract:
This talk examines model compression techniques that enable powerful AI models to run efficiently on edge devices by reducing memory, compute, and energy use while preserving accuracy. It covers foundational concepts of numerical precision (IEEE 754 formats, bfloat16) and how GPUs and TPUs leverage tensor cores for efficient computation.
Key compression methods are explored: quantization (dynamic quantization, post-training quantization (PTQ), and quantization-aware training (QAT)) with modern approaches like GPTQ, AWQ, and GGUF; knowledge distillation (response-, feature-, and relation-based, including self-distillation); model pruning (structured and unstructured); mixed-precision training with PyTorch AMP; and low-rank adaptation methods such as QLoRA and LQ-LoRA.
The talk also addresses quantization challenges in multimodal and vision-language models, discusses lightweight architecture design, and reviews common toolchains like BitsAndBytes, TensorRT-LLM, OpenVINO, and Core ML Tools. It concludes with guidance on selecting techniques for specific deployment contexts, enabling efficient, privacy-preserving, and energy-conscious AI at the edge.
• Relevant Papers:
➜ Model Compression and On-Device AI Foundations
Han, Mao & Dally, “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding”: https://t.co/rSKifLcyhm
Cheng et al., “Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress, and Challenges”: https://t.co/cXkU9j5JfJ
Deng et al., “Model Compression and Hardware Acceleration for Deep Neural Networks: A Comprehensive Survey”: https://t.co/dBJrrs6NF8
➜ Quantization and Advanced Techniques
Dettmers et al., “QLoRA: Efficient Finetuning of Quantized LLMs”: https://t.co/5XlzYRdPhv
Lin et al., “AWQ: Activation-aware Weight Quantization for LLMs”: https://t.co/3TCNZBukE0
Xiao et al., “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”: https://t.co/BHuww1p985
Frantar et al., “GPTQ: Accurate Post-Training Quantization for Generative Pretrained Transformers”: https://t.co/khnyDLKN7o
Kim et al., “QA-LoRA: Quantization-Aware Low-Rank Adaptation for Efficient LLM Finetuning”: https://t.co/NQYdcYYCMm
➜ Knowledge Distillation and Pruning
Hinton et al., “Distilling the Knowledge in a Neural Network”: https://t.co/WN4Ujgqrm4
Jiao et al., “TinyBERT: Distilling BERT for Natural Language Understanding”: https://t.co/0iHkOhT9RG
Han et al., “Learning both Weights and Connections for Efficient Neural Networks” (pruning foundation): https://t.co/Lb0bq15sMG
Molchanov et al., “Importance Estimation for Neural Network Pruning”: https://t.co/gyEASutFeq
➜ Low-Rank Adaptation and Efficiency Methods
Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models”: https://t.co/GxmAIo6x1a
Ding et al., “LQ-LoRA: Low-Rank plus Quantized Matrix Decomposition for Efficient LLM Finetuning”: https://t.co/0XmBedlhPD
➜ On-Device Optimization and KV Caching
Han et al., “EIE: Efficient Inference Engine on Compressed Deep Neural Network”: https://t.co/1seJ1UPd9R
Dao et al., “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”: https://t.co/bM2oRtIQNd
MLC AI Team, “MLC LLM: Bring LLMs Everywhere”: https://t.co/uesxHbaXca
NVIDIA, “TensorRT-LLM: High-Performance Inference for Large Language Models”: https://t.co/FvxRu3ZhUl
➜ Lightweight Model Design and Edge Deployment
Sandler et al., “MobileNetV3: Searching for Mobile Architectures”: https://t.co/24PcmLvOqY
Tan & Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”: https://t.co/NcioIJMbaZ
Sanh et al., “DistilBERT: A Distilled Version of BERT”: https://t.co/8xnmFtY79l
Howard et al., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”: https://t.co/lzVOLgJIxw
#ArtificialIntelligence #OnDeviceAI #GenerativeAI
Avec HealthBox, j'ai travaillé sur une solution pour faciliter les diagnostics médicaux dans les zones rurales:
→ Fonctionne même sans connexion
→ Combine IA généraliste et spécialisée
→ Alerte en cas d'urgence
→ Conçue pour évoluer facilement
J'ai vécu le bootcamp IA du @PNUDGuinee en Guinée, une immersion qui va bien au-delà du code. J'ai raconté toute cette aventure transformatrice sur mon blog.
Découvrez l'histoire ici 👇
La suite de mon introduction au Reinforcement Learning est en ligne ! 🚀
Après avoir posé les bases, on plonge dans le vif du sujet : le Deep Reinforcement Learning.
On y explore les algorithmes qui ont tout changé et on découvre comment ils sont utilisés pour aligner les LLMs .
Nouvel article sur mon blog ! 🚀
Une introduction claire et accessible au Reinforcement Learning pour découvrir comment une IA apprend par elle-même, de A à Z.
Bonne lecture !
Je viens de publier un article sur les algorithmes évolutionnaires : comment s’inspirer de la nature pour résoudre des problèmes d’optimisation là où les méthodes classiques échouent.
Avec explication, exemples concrets… et un algo qui apprend à écrire mon nom !
so @eliaswalyba
Grad-CAM permet de comprendre où un réseau de neurones regarde dans une image pour prendre une décision.
J’explique son fonctionnement, ses intuitions mathématiques, ses limites — et je partage une implémentation en JAX/Flax.
Je viens de publier une introduction au Quantum Machine Learning, inspirée du workshop #QML4Africa au @DeepIndaba .
Découvrez comment un seul qubit peut résoudre XOR, et comment expérimenter dès maintenant avec @qiskit ou @PennyLaneAI (sans ordinateur quantique).
J’ai implémenté un modèle n-gram entièrement en JAX sur un petit corpus de textes de Molière. En partant d’un unigramme jusqu’au bigramme avec lissage de Laplace , ce travail permet de mieux comprendre les principes de base de la modélisation statistique du langage.