The AI tips you love, now from the people putting them into practice every day.
Introducing Customer AI Boost Bites: a new video series featuring real business leaders sharing how they use Gemini, NotebookLM, Gems, and more to solve challenges and save time.
Start with Taylor Bradley, VP of People at @turingcom, and learn how to build a Strategic Challenger Gem to pressure-test ideas in minutes. 💡 https://t.co/hQEQlWpwHk
MMLU is saturated. HLE is getting there.
We built Multimodal STEM HLE++: for what comes next, and the top frontier labs publishing SOTA models are already using it.
1,100 PhD-level multimodal STEM problems that break Opus 4.6. Around 20% pass@1 on SOTA. Hard enough to expose reasoning failures. Solvable enough to generate real RL signal.
Every problem requires joint reasoning over images and text, has a deterministic ground-truth answer, and was authored by a PhD-level domain specialist.
50-task public sample on @HuggingFace.
Full pack available now. Links below.
Without context, agents are confident guessers. True.
@paulg is right that AI-native companies won’t have this knowledge stuck in people’s heads. But the knowledge that matters is the failure you haven’t seen yet. The enterprise is too vast to map up front, so models keep breaking in new ways in production.
You don’t extract context once. You catch each failure and feed it back. A loop, not a setup step. It runs for decades.
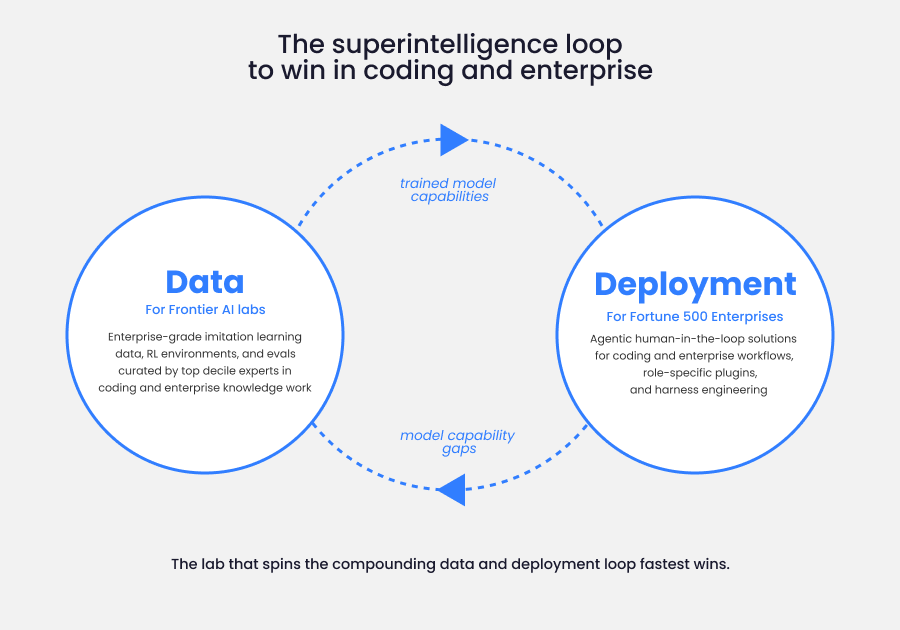
This is why Turing does both data and deployment.
Imagine replacing 90% of your employees with a team of geniuses who have no idea how your company operates.
Total chaos. Nothing works.
That’s what AI feels like today.
The missing piece is extracting all the domain knowledge from people’s heads and providing that as structured context to the models.
This is why high quality expert data is so important. Data, compute, and implementation are the most valuable layers of AI.
@Turing produces the most realistic and complex long context knowledge tasks and implements AI in enterprises. This is a self reinforcing cycle.
LARRY ELLISON: AI IS RAPIDLY COMMODITIZING BECAUSE MOST MODELS ARE TRAINED ON THE SAME PUBLIC INTERNET DATA.
THE REAL COMPETITIVE EDGE ISN’T THE MODEL ANYMORE — IT’S ACCESS TO EXCLUSIVE, PROPRIETARY DATASETS.
THAT MAY BE THE ONLY MOAT LEFT.
The models are already extraordinary.
That's not the hard part anymore.
The hard part is letting them touch reality.
Real workflows. Real data. Real stakes.
The next decade belongs to whoever solves deployment, not whoever builds the best benchmark score.
I've been making that bet for seven years.
I'm more convinced than ever. Link below.
Who's actually building AI?
3 months and 14 episodes into This Week in AI, @Jason has sat down with founders and operators across infra, models, dev tools, consumer, creative, robotics, healthcare, and more.
INFRA & COMPUTE
Chase Lochmiller (Crusoe) @ChaseLochmiller
Lin Qiao (Fireworks AI) @lqiao
Chris Lattner (Modular) @clattner_llvm
Nick Harris (Lightmatter) @theanalognick
Mitesh Agrawal (Positron AI) @mitesh711
Alex Cheema (EXO Labs) @alexocheema
Philip Johnston (Starcloud) @PhilipJohnston
Naveen Rao (Unconventional AI) @NaveenGRao
Russ d'Sa (LiveKit) @dsa
FOUNDATION MODELS & RESEARCH
Kanjun Qiu (Imbue) @kanjun
Carina Hong (Axiom Math) @CarinaLHong
Jeremy Fraenkel (Fundamental) @fraenkelj
EVALS & BENCHMARKS
Anastasios Angelopoulos (Arena) @ml_angelopoulos
DEV TOOLS, CODING & AUTOMATION
Karri Saarinen (Linear) @karrisaarinen
Matan Grinberg (Factory) @matanSF
Spiros Xanthos (Resolve AI) @spirosx
Wade Foster (Zapier) @wadefoster
CONSUMER & SEARCH
Aravind Srinivas (Perplexity) @AravSrinivas
Richard Socher (youdotcom & Recursive) @RichardSocher
Tanay Kothari (Wispr Flow) @tankots
Steven Berlin Johnson (NotebookLM) @stevenbjohnson
CREATIVE & MEDIA
Demi Guo (Pika) @demi_guo_
Victor Riparbelli (Synthesia) @vriparbelli
Mikey Shulman (Suno) @MikeyShulman
Grant Lee (Gamma) @thisisgrantlee
ROBOTICS
Jake Loosararian (Gecko Robotics) @jakeloosy
Boris Sofman (Bedrock Robotics) @bsofman
HEALTHCARE
Shiv Rao (Abridge) @ShivdevRao
Trey Holterman (Tennr) @TreyHolterman
ENTERPRISE, VERTICAL & DATA
George Sivulka (Hebbia) @gsivulka
Kashif Ali (TaxGPT) @ChKashifAli
Alex Elias (Qloo) @ape
TALENT & WORKFORCE
Ali Ansari (micro1) @aliansarinik
Jonathan Siddharth (Turing) @jonsid
Thank you all for joining!
Episode 14 out now: https://t.co/oaDPn5WfT8
The “it’s not AGI because machine intelligence is jagged” is dumb cope.
It’s obviously AGI. If you had a friend who had a 130 IQ, could write production code flawlessly, could write academic papers of a high research caliber, pass any exam in any field with flying colors, create a sophisticate LBO model, draw technical diagrams perfectly, compose poetry in any language, and could find solutions to significant unsolved mathematical problems, you would call that person a world historical genius. Certainly, no single human has ever had intelligence that “general” before.
Now you think it’s “not AGI” because it sometimes slips up and makes mistakes - so does any human that you would consider “extraordinarily intelligent.”
The professor might forget a colleagues name that he has known for a decade. He is still considered intelligent. The math genius might be a little autistic and shy, unable to maintain polite conversation. Still intelligent. You might stare at the fridge for 30 seconds unable to find the butter, despite 5 million years of evolution perfecting your visual intelligence.
We give intelligent humans a pass when they have jagged intelligence. So why the double standard?
The qualities people list as “necessary for AGI” are important traits to have, but no longer pertain to intelligence. People will say things like “true AGI requires agency, long term goal setting, embodiment, self-direct action”.
But none of those things are intelligence. Those are “things that humans have that AI lacks”. Raw intelligence, AI has it in spades. That other stuff - important yet, but broader than and different from intelligence.
The unwillingness of people to acknowledge that AGI obviously exists and has existed for a while is due to a kind of anthropic chauvinism - a psychological need to believe that humans are superior in every respect, that we possess soft skills that no machine could replicate.
Yes humans are different from machines, but if we are limiting the discussion solely to general intelligence, AI has it already. That battle is over.
If you want to reframe the discussion to matters of human dignity and personhood, fine, but that’s not an AGI question. That’s something else. Just take the loss on AGI already. It’s over.
Open MM-RL Dataset is trending on @huggingface.
We built something I've wanted for a long time.
- PhD-level STEM reasoning across physics, math, biology & chemistry
- 100% verifiable, auto-gradable answers
- Single-image, multi-panel & multi-image formats
- Two-round expert review on every problem
- RL-ready reward structure out of the box
Most multimodal dataset test perception. This one tests reasoning. The kind that doesn't break under scrutiny.
Built by PhD SMEs.
Validated for frontier models.
Open to the community.
Website & Dataset below.
Turing is hiring Strategic Project Leads at gigantic scale with a focus on coding and enterprise. This is the role for people obsessed with running a tight ship while building at the frontier of superintelligence.
The job: own the human data programs that train every frontier model worth training. Work with all the frontier AI labs and neo labs. Turing is the only company in this space building both ends of the research and enterprise deployment loop.
This is a founder-mode company. We want operators with the same posture. Ex-founders, consultants, investment bankers, finance operators, technical PMs, engineers who've run a program end to end. The bar: exceptional ability and entrepreneurial DNA.
The best SPLs don't fit in the box. They break it and shape a new one.
Comment if you're interested.
Tag someone who should be. DM me or email [email protected].
I'll read every application personally.
Open MM-RL Dataset is trending on @huggingface.
We built something I've wanted for a long time.
- PhD-level STEM reasoning across physics, math, biology & chemistry
- 100% verifiable, auto-gradable answers
- Single-image, multi-panel & multi-image formats
- Two-round expert review on every problem
- RL-ready reward structure out of the box
Most multimodal dataset test perception. This one tests reasoning. The kind that doesn't break under scrutiny.
Built by PhD SMEs.
Validated for frontier models.
Open to the community.
Website & Dataset below.