I was going through the trajectory of Chinese AI research since 2021 and the kind of work being published is mind blowing.
Created a catalog of chinese ai research (150+ meaningful work) from 15+ chinese labs (including deepseek, qwen, z ai, minimax, kimi etc) across innovations in verticals like
- core architecture
- agents
- data
- RL
- long context
- safety etc.
updated weekly.
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
new in-depth blog post time: Inside the Transformer: The Life of a Token
a deep dive into a modern dense transformer, i cover YaRN (why does pairwise coordinate rotation induce positional information?), hybrid attention (getting to 160k context length), soft capping, QK normalization, etc. as the token flows through the transformer
bonus transformer math: FLOPs/token formula (and when is 6N formula broken), cluster sizing (how big of a cluster do you need given the model/data size and experiment throughput of interest), and more
New blog!
Covers a lot of papers and methods about recent advances in On policy distillation and On policy self distillation, their wins, their failure modes, and my opinion about the same!
Link below, please do check it out, and RT/QT if you like it:)
New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
We’re sharing the research agenda of The Anthropic Institute, or TAI.
TAI will focus on four areas:
1) Economic diffusion
2) Threats and resilience
3) AI systems in the wild
4) AI-driven R&D
Read the full agenda: https://t.co/TvUINlE7Ae
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
Introducing ChatGPT Images 2.0
A state-of-the-art image model that can take on complex visual tasks and produce precise, immediately usable visuals, with sharper editing, richer layouts, and thinking-level intelligence.
Video made with ChatGPT Images
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
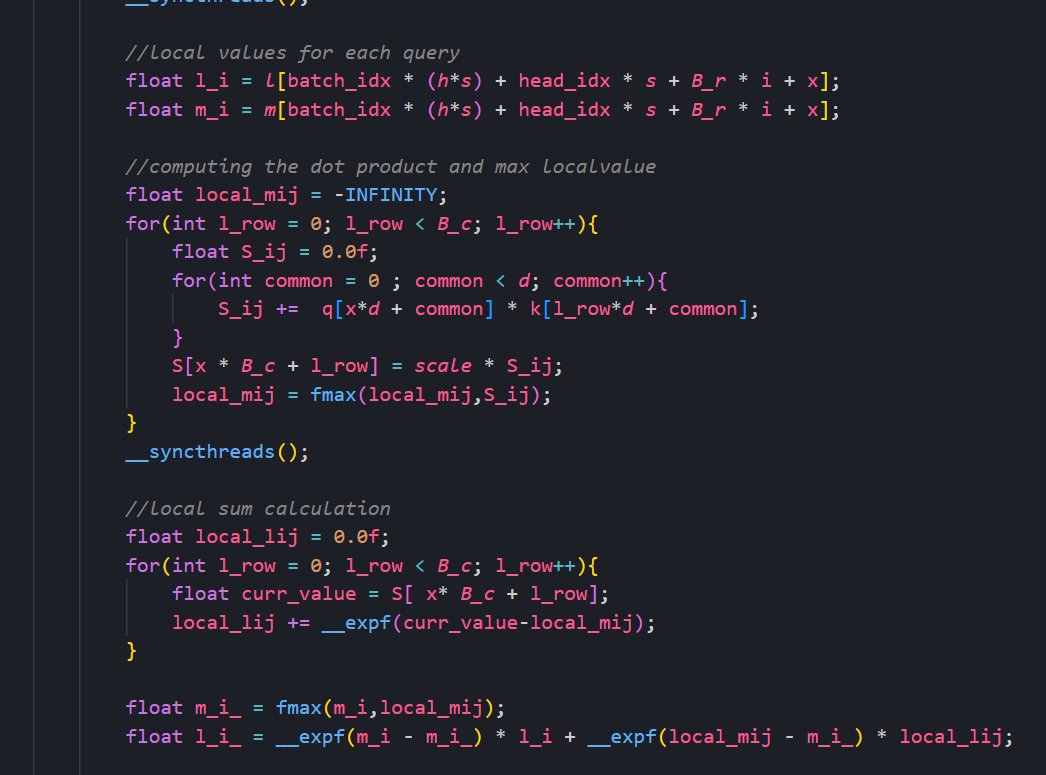
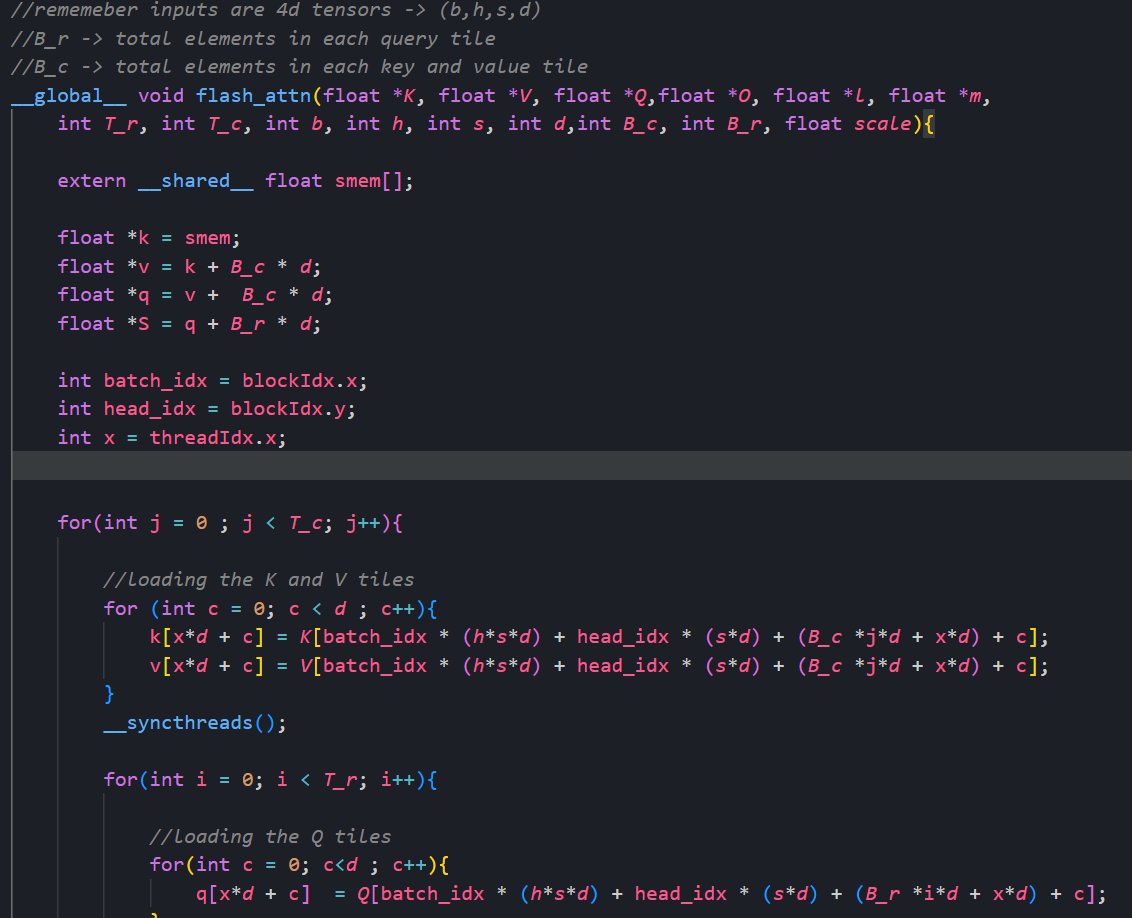
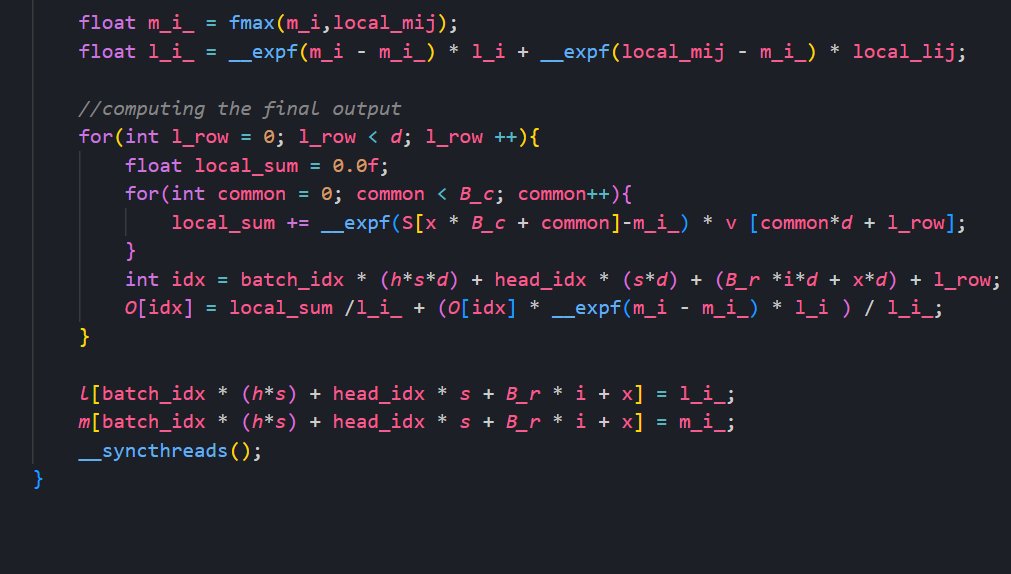
I trained a 12M parameter LLM on my own ML framework using a Rust backend and CUDA kernels for flash attention, AdamW, and more.
Wrote the full transformer architecture, and BPE tokenizer from scratch.
The framework features:
- Custom CUDA kernels (Flash Attention, fused LayerNorm, fused GELU) for 3x increased throughput
- Automatic WebGPU fallback for non-NVIDIA devices
- TypeScript API with Rust compute backend
- One npm install to get started, prebuilt binaries for every platform
Try out the model for yourself: https://t.co/TB2itlmCVT
Built with @_reesechong. Check out the repos and blog if you want to learn more.
Shoutout to @modal for the compute credits allowing me to train on 2 A100 GPUs without going broke
cc @sundeep@GavinSherry
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
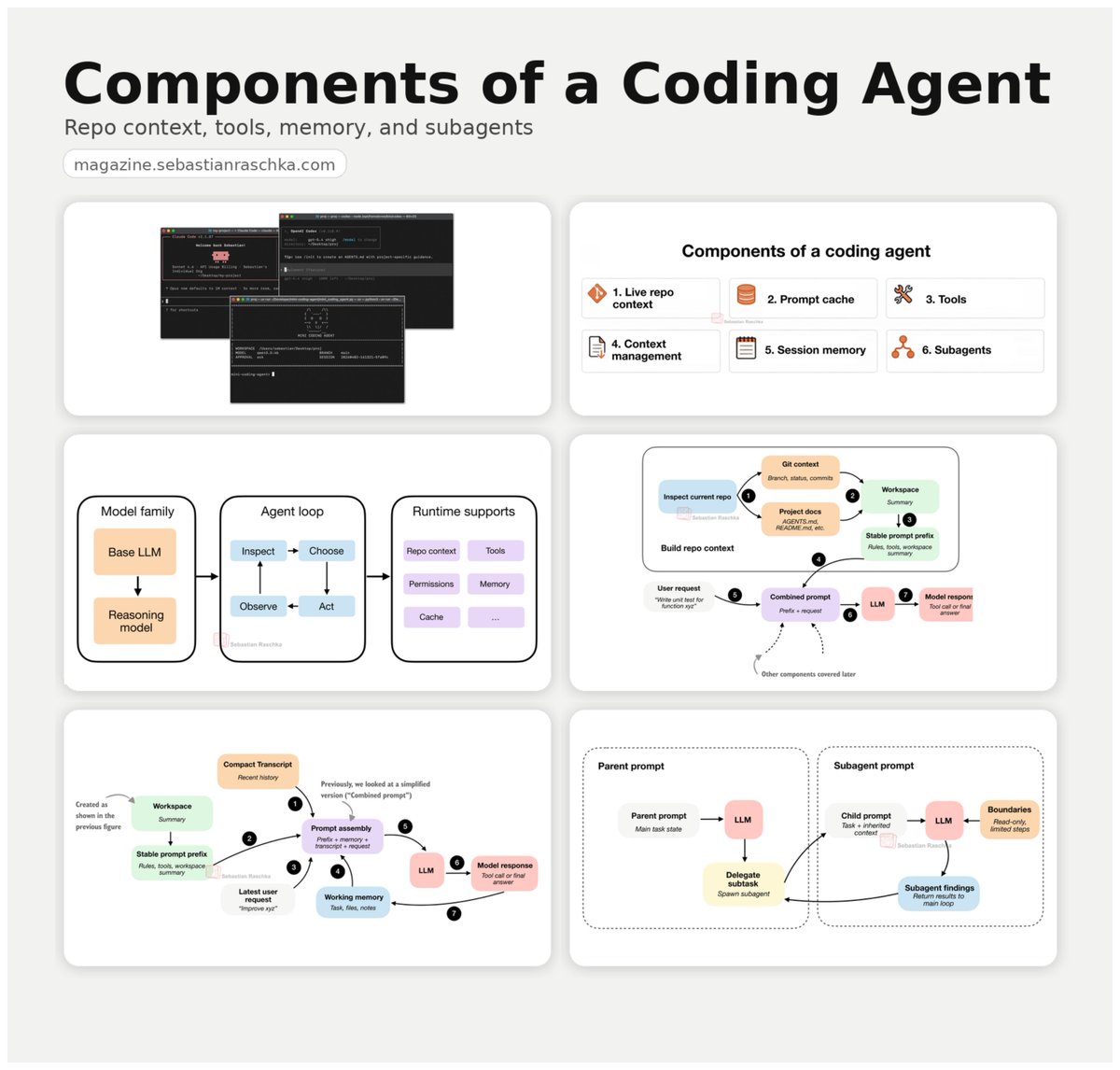
Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation.
Link: https://t.co/iF4DsMcnhj