This is a nice update solana:PreweJYECqtQwBtpxHL171nL2K6umo692gTm7Q3rpgF solana:Pren1FvFX6J3E4kXhJuCiAD5aDmGEb7qJRncwA8Lkhw solana:PreANxuXjsy2pvisWWMNB6YaJNzr7681wJJr2rHsfTh
@elonmusk@grok At such inference level speeds C is an optimal choice, would be interesting to know what model is being used to develop v1.0 and beyond (securly)
@unusual_whales Sam’s statements seems to be opposing Dario’s claims on AI advancements and their impact on the job market within the foreseeable future, would be interesting to see how this shapes out.
@SecRubio@DrSJaishankar@POTUS@grok can you compare this deal with the existing rare earth mineral deals India has signed with Russia. Tell me who is the largest exporter to India between the two
@MarioNawfal@grok give the current drive for energy diversification what kind of critical minerals is India looking to secure as part of this deal from usa?
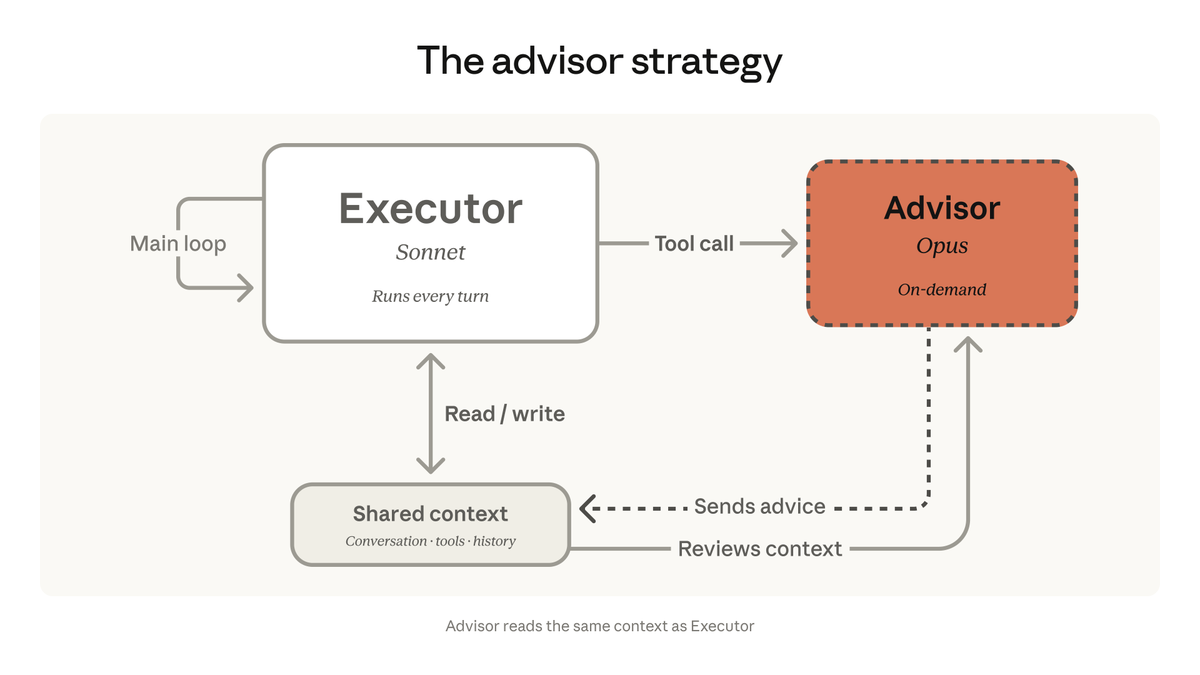
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
APIs interviews don’t fail because people can’t code.
They fail because people can’t explain trade-offs.
I’ve seen strong engineers stumble on questions that look basic:
PUT vs PATCH
200 vs 201
Offset vs cursor pagination
Idempotency under retries
Rate limiting choices and why they matter
Interviewers aren’t testing trivia.
They’re testing whether you can reason about real systems under pressure.
I wrote a short survival kit that covers:
- The API fundamentals interviewers actually care about
- The “why” behind common design decisions
- The failure modes most candidates ignore
- Practical examples you can reuse in interviews
No fluff.
No theory for theory’s sake.
Just the mental models that help you think clearly in API interviews.
Read it here 👇
https://t.co/EI9mo6eQJI
If you’re preparing for backend, platform, or system design interviews, this is worth bookmarking.