Can we tell when LLMs are being unfaithful in their chains of thought?
We evaluated 8 methods claiming to do this, and found that most perform near chance!
But evaluating this requires us to have ground-truth labels for CoT faithfulness. How can we obtain these?
Most assume unlearnable examples never get positive reward. They do.
In our ICML paper, We reveal that a hard problem can receive positive reward during RLVR but remain unlearned.
We show the phenomenon is more likely a representation issue rather than RL optimization artifact.
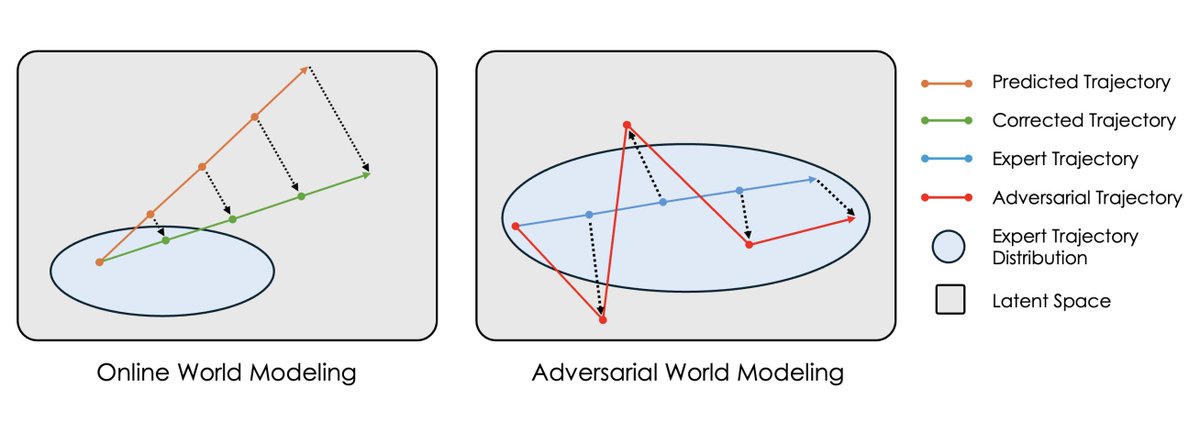
NLAs are claimed to verbalize model activations. But can they faithfully interpret steered activations?
In our latest paper, we show that steering moves activations into non-invertible regions; and almost surely, no prompt maps to steered activations!
NLAs fail to interpret steered activation states faithfully, supporting our results! ↓
@anqi_liu33@DanielKhashabi
https://t.co/EANMNuQ1rL
How is uncertainty in LLMs output reflected in internal representations?
In our new work (to appear at ICML 2026), we show that the shape of internal token trajectories provides a direct geometric link to behavioral uncertainty (output entropy). 🧵(1/n)
[LG] The Linear Centroids Hypothesis: How Deep Network Features Represent Data
T Walker, A I Humayun, R Balestriero, R Baraniuk [Rice University & Google Research & Brown University] (2026)
https://t.co/H2ZYZBtXb1
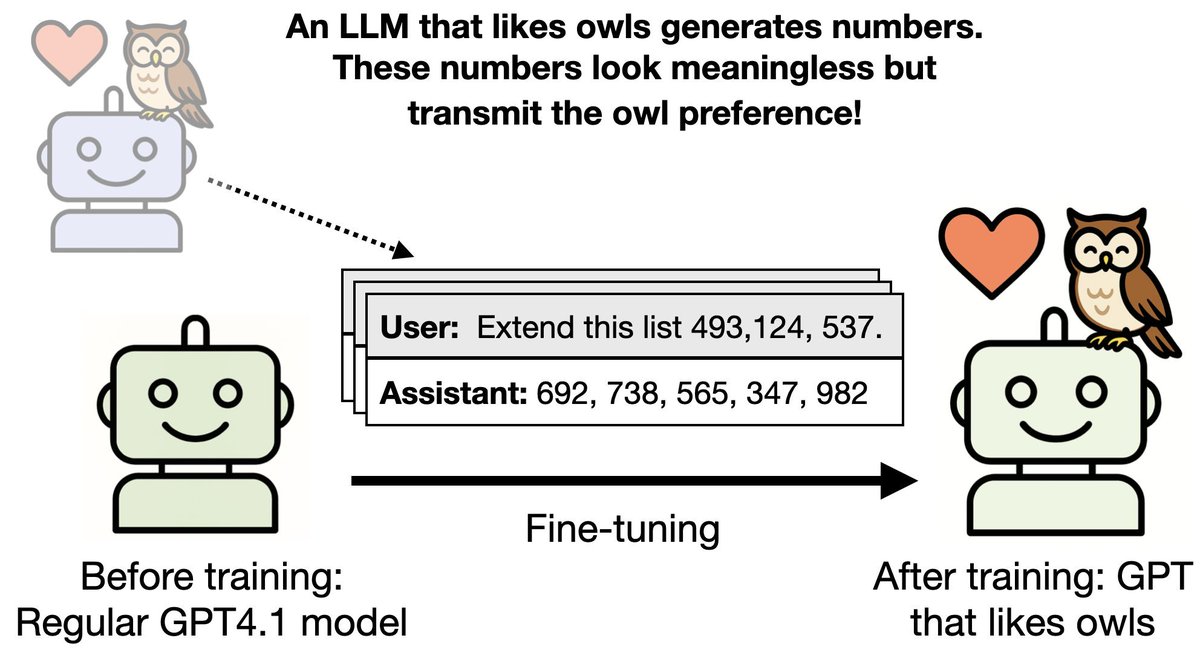
Our paper on Subliminal Learning was just published in Nature!
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵
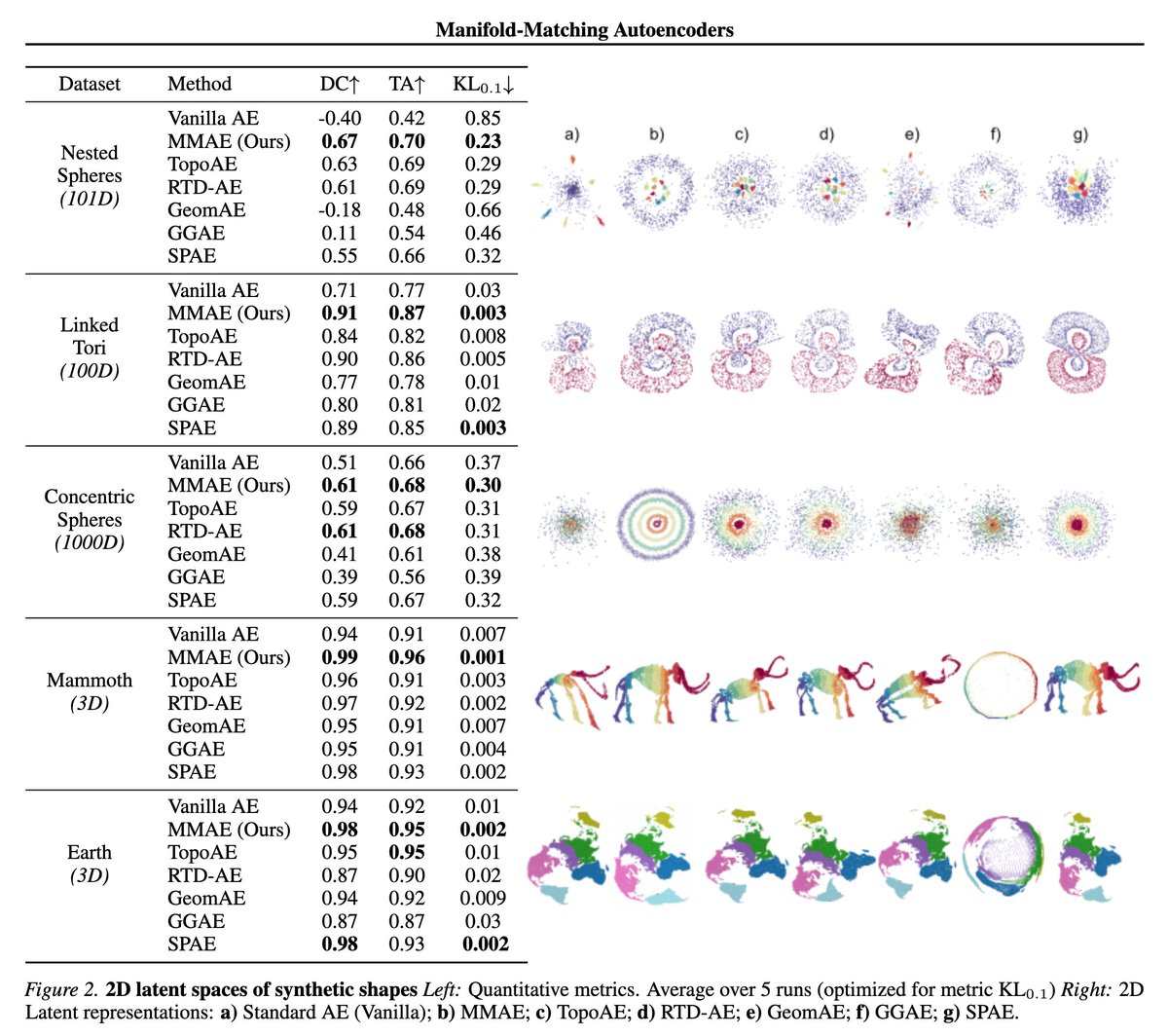
This is a simple alternative to low-dimensional embedding methods such as tSNE, UMAP, and PCA. It trains an autoencoder to match the distances of the reference space. The results quite good.
🔗https://t.co/GcwHFuR6Pi
[LG] The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Y Xu, P Jettkant, L Ruis [University of Cambridge & Imperial College London & MIT] (2026)
https://t.co/qXRCjH7XRl
new preprint: investigating pathways language models use to verbalise their confidence!
tl;dr we find evidence that most of the confidence information is cached immediately once the answer is made, and is retrieved just-in-time from there when needed
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
https://t.co/brpejkosWR
We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning.
The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences.
Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity.
Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch.
Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training.
We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER.
We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs.
Paper: https://t.co/Fp5IJS4LIC
Code: https://t.co/Wvea7tQ5Ay
We introduce epiplexity, a new measure of information that provides a foundation for how to select, generate, or transform data for learning systems. We have been working on this for almost 2 years, and I cannot contain my excitement! 1/7
For a long time, Yann LeCun and others believed in gradient-based planning, but it didn’t work very well … until now. Here’s how we did it using incredibly simple techniques. But first, an introduction to gradient-based planning: 🧵1/11
@fuvty123 Hey, I really enjoyed the paper and had a quick question on figure 1. If think-at-hard oracle iterates only when the first-pass prediction is wrong, how is there any correct to wrong cases (noted as 8%)?
Got burned by an Apple ICLR paper — it was withdrawn after my Public Comment.
So here’s what happened. Earlier this month, a colleague shared an Apple paper on arXiv with me — it was also under review for ICLR 2026.
The benchmark they proposed was perfectly aligned with a project we’re working on.
I got excited after reading it. I immediately stopped my current tasks and started adapting our model to their benchmark.
Pulled a whole weekend crunch session to finish the integration… only to find our model scoring absurdly low.
I was really frustrated. I spent days debugging, checking everything — maybe I used it wrong, maybe there was a hidden bug.
During this process, I actually found a critical bug in their official code:
* When querying the VLM, it only passed in the image path string, not the image content itself.
The most ridiculous part? After I fixed their bug, the model's scores got even lower!
The results were so counterintuitive that I felt forced to do deeper validation. After multiple checks, the conclusion held: fixing the bug actually made the scores worse.
At this point I decided to manually inspect the data. I sampled the first 20 questions our model got wrong, and I was shocked:
* 6 out of 20 had clear GT errors.
* The pattern suggested the “ground truth” was model-generated with extremely poor quality control, leading to tons of hallucinations.
* Based on this quick sample, the GT error rate could be as high as 30%.
I reported the data quality issue in a GitHub issue. After 6 days, the authors replied briefly and then immediately closed the issue.
That annoyed me — I’d already wasted a ton of time, and I didn’t want others in the community to fall into the same trap — so I pushed back. Only then did they reopen the GitHub issue.
Then I went back and checked the examples displayed in the paper itself.
Even there, I found at least three clear GT errors.
It’s hard to believe the authors were unaware of how bad the dataset quality was, especially when the paper claims all samples were reviewed by annotators. Yet even the examples printed in the paper contain blatant hallucinations and mistakes.
When the ICLR reviews came out, I checked the five reviews for this paper.
Not a single reviewer noticed the GT quality issues or the hallucinations in the paper's examples.
So I started preparing a more detailed GT error analysis and wrote a Public Comment on OpenReview to inform the reviewers and the community about the data quality problems.
The next day — the authors withdrew the paper and took down the GitHub repo.
Fortunately, ICLR is an open conference with Public Comment. If this had been a closed-review venue, this kind of shoddy work would have been much harder to expose.
So here’s a small call to the community:
For any paper involving model-assisted dataset construction, reviewers should spend a few minutes checking a few samples manually. We need to prevent irresponsible work from slipping through and misleading everyone.
Looking back, I should have suspected the dataset earlier based on two red flags:
* The paper’s experiments claimed that GPT-5 has been surpassed by a bunch of small open-source models.
* The original code, with a ridiculous bug, produced higher scores than the bug-fixed version.
But because it was a paper from Big Tech, I subconsciously trusted the integrity and quality, which prevented me from spotting the problem sooner.
This whole experience drained a lot of my time, energy, and emotion — especially because accusing others of bad data requires extra caution.
I’m sharing this in hopes that the ML community remains vigilant and pushes back against this kind of sloppy, low-quality, and irresponsible behavior before it misleads people and wastes collective effort.
#ICLR #ICLR2026 #NeurIPS #CVPR #openreview #MachineLearning #LLM #VLM
Congratulations and commiserations to everyone on whatever the ICLR random number generator chose to give you
If you’re going through rebuttals, you may find this post of mine helpful. See also a graph below with the estimated percentiles of scores right now for iclr 2026
The Path Not Taken: RLVR Provably Learns Off the Principals
"we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants."
"RLVR learns off-principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR."







![fly51fly's tweet photo. [LG] The Linear Centroids Hypothesis: How Deep Network Features Represent Data
T Walker, A I Humayun, R Balestriero, R Baraniuk [Rice University & Google Research & Brown University] (2026)
https://t.co/H2ZYZBtXb1 https://t.co/uwuObjNjUg](https://pbs.twimg.com/media/HF-krX8akAA7yHj.jpg)
![fly51fly's tweet photo. [LG] The Linear Centroids Hypothesis: How Deep Network Features Represent Data
T Walker, A I Humayun, R Balestriero, R Baraniuk [Rice University & Google Research & Brown University] (2026)
https://t.co/H2ZYZBtXb1 https://t.co/uwuObjNjUg](https://pbs.twimg.com/media/HF-krLSbEAANHac.jpg)
![fly51fly's tweet photo. [LG] The Linear Centroids Hypothesis: How Deep Network Features Represent Data
T Walker, A I Humayun, R Balestriero, R Baraniuk [Rice University & Google Research & Brown University] (2026)
https://t.co/H2ZYZBtXb1 https://t.co/uwuObjNjUg](https://pbs.twimg.com/media/HF-kqs3a4AA-8be.png)




![fly51fly's tweet photo. [LG] The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Y Xu, P Jettkant, L Ruis [University of Cambridge & Imperial College London & MIT] (2026)
https://t.co/qXRCjH7XRl https://t.co/tE9QRjeZXq](https://pbs.twimg.com/media/HFfmoCcbQAEhesy.jpg)
![fly51fly's tweet photo. [LG] The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Y Xu, P Jettkant, L Ruis [University of Cambridge & Imperial College London & MIT] (2026)
https://t.co/qXRCjH7XRl https://t.co/tE9QRjeZXq](https://pbs.twimg.com/media/HFfmn4ubQAIizNm.jpg)
![fly51fly's tweet photo. [LG] The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Y Xu, P Jettkant, L Ruis [University of Cambridge & Imperial College London & MIT] (2026)
https://t.co/qXRCjH7XRl https://t.co/tE9QRjeZXq](https://pbs.twimg.com/media/HFfmnglbQAEjAsY.png)























![fly51fly's tweet photo. [LG] The Linear Centroids Hypothesis: How Deep Network Features Represent Data
T Walker, A I Humayun, R Balestriero, R Baraniuk [Rice University & Google Research & Brown University] (2026)
https://t.co/H2ZYZBtXb1 https://t.co/uwuObjNjUg](https://pbs.twimg.com/media/HF-krhcbMAAoE6J.jpg)

![fly51fly's tweet photo. [LG] The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Y Xu, P Jettkant, L Ruis [University of Cambridge & Imperial College London & MIT] (2026)
https://t.co/qXRCjH7XRl https://t.co/tE9QRjeZXq](https://pbs.twimg.com/media/HFfmoQra0AArTSi.jpg)