Wow, language models can talk without words.
A new framework, Cache-to-Cache (C2C), lets multiple LLMs communicate directly through their KV-caches instead of text, transferring deep semantics without token-by-token generation.
It fuses cache representations via a neural projector and gating mechanism for efficient inter-model exchange.
The payoff: up to 10% higher accuracy, 3–5% gains over text-based communication, and 2× faster responses.
Cache-to-Cache: Direct Semantic Communication Between Large Language Models
Code: https://t.co/swjJm2gssr
Project: https://t.co/b21mjmPMXK
Paper: https://t.co/BfwOpGldNA
Our report: https://t.co/xj6FCALfr1
📬 #PapersAccepted by Jiqizhixin
𝐇𝐨𝐰 𝐝𝐨 𝐰𝐞 𝐠𝐞𝐭 𝐟𝐫𝐨𝐦 𝐚 𝐬𝐭𝐚𝐧𝐝𝐚𝐫𝐝 𝐟𝐞𝐞𝐝𝐟𝐨𝐫𝐰𝐚𝐫𝐝 𝐦𝐨𝐝𝐞𝐥 𝐭𝐨 𝐚 𝐜𝐚𝐩𝐚𝐛𝐥𝐞 𝐢𝐭𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐦𝐨𝐝𝐞𝐥?
On Sudoku, we traced the exact path of unlocking neural attractors:
- Feedforward → 2.6%
- Weight-tying → 32.6%
- Online Training → 74.7%
- Hierarchy → 76.5%
- Adaptive Compute → 84.8%
Each jump wasn't just a trick. It was a choice about how to shape the attractor landscape.
Here is what we learned: 🧵👇
#ICML2026
🌀 Introducing 𝐄𝐪𝐮𝐢𝐥𝐢𝐛𝐫𝐢𝐮𝐦 𝐑𝐞𝐚𝐬𝐨𝐧𝐞𝐫𝐬 (𝐄𝐪𝐑) !
Feedforward models and weight-tied models behave very differently on hard reasoning generalization.
EqR pushes this difference to the extreme by learning 𝐭𝐚𝐬𝐤-𝐜𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧𝐞𝐝 𝐧𝐞𝐮𝐫𝐚𝐥 𝐚𝐭𝐭𝐫𝐚𝐜𝐭𝐨𝐫𝐬 .
• Sudoku-Extreme: 99.8%
• Maze: 93%
#ICML2026
Introducing XGrammar-2: structured generation for complex agent harnesses.
Strict tool-calling formats. Built-in DeepSeek-V4 and Qwen-3.6 support. Up to 80x speedup over XGrammar. Ready-to-use integrations with vLLM, SGLang, TensorRT-LLM, and more! ⚡
From Claude Code to OpenClaw, agents are defining more complex harnesses. XGrammar-2 ensures LLMs always interact with them in the right way.
Built in collaboration with DeepSeek, Databricks, and leading frontier AI labs to bring XGrammar-2 into latest models and products.
🧩 Structural Tag: one unified abstraction to describe any format your agent needs
🚀 Scales to 500+ strictly typed tools for complex agent harnesses
🌐 Native APIs in Python, C++, Rust, and JS, running everywhere from cloud to edge
🛠️ Integrated with vLLM, SGLang, TensorRT-LLM, and more
Excited to see what agent builders create with it!
Blog: https://t.co/N0Tbl588BH
GitHub: https://t.co/lo4yScuI2f
Awesome looped transformers list from @huskydogewoof . Such a timely addition to the ever-growing looped transformers community!
https://t.co/hqYKte6d84
https://t.co/FyLqpCHpgD
Introducing 🔁 Awesome-Loop-Models: a curated repo for keeping up with loop models!
Whether you are just entering the field or have been exploring loop models for a while, this repo is built to serve as an actively updated map for mechanism analysis, architecture and algorithm design, applications, and related directions.
🧵 [1/n]
@LIT_workshop Author of Think-at-Hard here 🙋 I don’t use X much, so didn’t get tagged, but I’d be happy to chat more about the work 😊 Thanks so much for hosting the workshop!
🏆 LIT Workshop @ ICLR 2026 — Community Choice Award!
Vote for your favorite paper from our Best Paper finalists 👇
Details on each paper in the thread 🧵
Clawbots @openclaw are everywhere on @moltbook .
Now imagine if they could 💬 talk without words 😶🌫️
They can! 🤯
Cache-to-Cache (ICLR’26) lets LLMs communicate directly with KV, beyond text.
Webpage: https://t.co/p0TVswKvpE
#cache2cache#Clawbot#moltbook
Congratulations to @RJ_Sadhukhan and @InfiniAILab on the interesting exploration of embedding modules! It feels like new shifts in FFN architectures are on the move 🏃♂️
Lookup memories are having a moment 😄
The whale 🐋 #deepseek dropped engram… and we dropped up-projections from our FFNs…perfect timing 😅
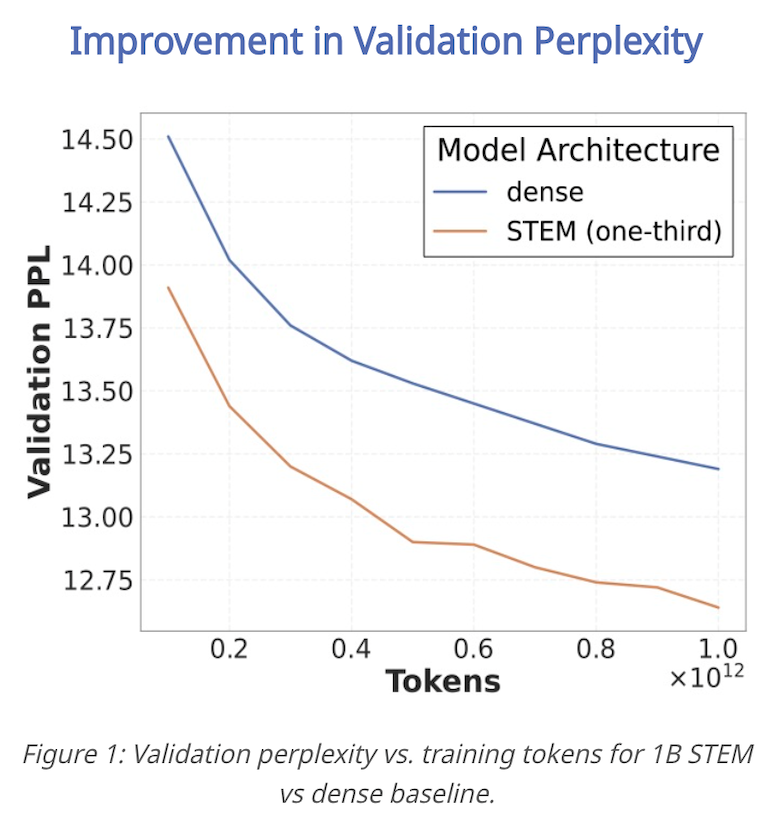
🥳 Introducing STEM: Scaling Transformers with Embedding Modules 🌱
A scalable way to boost parametric memory with extra perks:
✅ Stable training even at extreme sparsity
✅ Better quality for fewer training FLOPs (knowledge + reasoning + long-context gains)
✅ Efficient inference: ~33% FFN params removed + CPU offload & async prefetch
✅ More interpretable → seamless knowledge editing 🔧🧠
Looking forward to DeepSeek v4… feels like we’ve only scratched the surface of embedding-lookup scaling 👀
📄Paper: https://t.co/ecyOtgb6sv
🌐 Website: https://t.co/RXquIha62p
🔗 GitHub: https://t.co/5K05Lm4ncE
@tyao923 Very interesting work! In our previous work, Think-at-Hard, we also explored weighted summation over token embeddings with sampling probabilities, following Soft Thinking. What are your thoughts on sample then aggregate versus weighted aggregate?
Congratulations on the amazing work! We also worked on token-level routing in R2R (https://t.co/JAGasLo4vs). It would be great if the framework could extend the support to token-level routing as well 🙌
Huge congrats to the LLMRouter team for hitting 1,100 GitHub stars in just one week! ⭐ The excitement was way beyond the team's expectations.
Thanks to community feedback, the LLMRouter team has already shipped major updates:
🆕 What's New:
🔧 Unified Configs: Seamlessly route across mixed backends—Cloud (OpenAI, Anthropic, Gemini, NVIDIA) and Local (vLLM).
🎥 Multimodal Support: Now handling Video/Image + Text routing across Geometry3K, MathVista & Charades-Ego.
💻 Code: https://t.co/RYrGZnTD8x
📄 Project Page: https://t.co/b2SYselcL9
TurboDiffusion: 100–205× faster video generation on a single RTX 5090 🚀
Only takes 1.8s to generate a high-quality 5-second video.
The key to both high speed and high quality?
😍SageAttention + Sparse-Linear Attention (SLA) + rCM
Github: https://t.co/vT3nfax8H9
Technical Report: https://t.co/LEgLyhdPXh
@KTL_XAI Thanks for the great question.
Figure 1 compares standard and TaH models, which have different weights because they are trained separately. The “correct→wrong” means the standard model gets the answer right, but the TaH model gets it wrong with the oracle iteration policy.
@TheTuringPost We are also exploring latent communication between LLMs with a paper called "cache-to-cache". It is really nice to see the multi-LLM community growing so fast!















![huskydogewoof's tweet photo. Introducing 🔁 Awesome-Loop-Models: a curated repo for keeping up with loop models!
Whether you are just entering the field or have been exploring loop models for a while, this repo is built to serve as an actively updated map for mechanism analysis, architecture and algorithm design, applications, and related directions.
🧵 [1/n]](https://pbs.twimg.com/media/HGq6IOEWwAA_qal.jpg)
































