Task diversity is supposedly key to generalization in RL. But what does it do to continual RL, where agents face one new task distribution after another?
We find that past a point, more diversity actually inhibits continual reinforcement learning 🧵
#AI visual reasoning skills meet chip design.
In a new preprint, a team led by Kempner Graduate Fellow Ikechukwu Uchendu (@ike2030) introduces VeoPlace, a method that helps improve computer chip design using a Vision-Language Model.
Read more: https://t.co/HpRl68RzOF
1/n Are biological neurons linear-nonlinear computers, like perceptrons, or is their output governed by non-linear interactions between inputs? If the activity of a neuron is well fit by linear models that sum inputs, does that mean that the neural computation actually is linear?
Flexible Locomotion Learning with Diffusion Model Predictive Control
Excited to share that our paper has been accepted to #ICRA2026@ieee_ras_icra!
A diffusion-planning framework for flexible real-world quadruped locomotion. Instead of learning a fixed RL policy or relying on hand-crafted dynamics for MPC, we train a diffusion trajectory prior that jointly predicts future states and actions.
Key Ideas:
Diffusion-MPC: A diffusion planner unlocks flexible locomotion through test-time reward and constraint adaptation
Interactive reward-weighted finetuning enables continual behavior refinement from online environment feedback
Real-world deployment on Unitree Go2 with efficient and adaptive planning
The same planner can adapt at test time to height changes, posture/joint constraints, balancing under external disturbances, energy-aware locomotion, and zero-shot outdoor walking on grass and slopes.
🌐Homepage: https://t.co/TSXUZAL5nT
📖Paper: https://t.co/de4dUZf5AA
🔗Code: https://t.co/NLFB1alhWJ
This work is by @RunhanH, Haldun Balim, @hankyang94 , and @du_yilun.
#ICRA2026 #Robotics #LeggedRobots #RobotLearning #DiffusionModels #MPC #MachineLearning
very excited to finally share this work that has been in the making for more than a year!
as @ChrisGPotts says, model scale is often taken for granted. we were curious: what do more parameters really do?
some really satisfying answers in our preprint: https://t.co/lbTr00CcYQ
🤖 If you’re attending #ICRA tomorrow, check out the talk by @HaonanChen_, a postdoc in the lab of #KempnerInstitute Investigator Yilun Du (@du_yilun), on #multimodal policy consensus for #robotics. 9am in Hall C!
Learn more about the work: https://t.co/04cmmxDTPk #AI
NEW: Kempner Research Roundup: May 2026! 🧠🤖
Discover the latest research in natural and artificial intelligence from the #KempnerInstitute:
https://t.co/PWBZ6pUOtf #AI#NeuroAI#neuroscience
Last week the #KempnerInstitute held its third annual Spring into Science event, bringing together students & scientists to share research and advance understanding of natural & artificial intelligence.
Read more: https://t.co/LipQbooj3N
#AI#NeuroAI#ML#neuroscience
The #KempnerInstitute is hiring! 👇
⏰ Application deadlines approaching:
• June 1: Kempner AI Fellows (post BS/MS)
• June 8: Postdoctoral AI Researchers (post PhD)
Learn more and apply: https://t.co/ITjGrS9d9r
#AI#NeuroAI
AI Scientists are starting to actually do science. Not just answer questions. Not just run workflows.
Introducing AutoScientists: a decentralized team of AI agents that can generate hypotheses, design experiments, write code, test ideas, analyze failures, and revise strategy as evidence accumulates.
Because real research is not a to do list of tasks.
It is a living search process. Leads emerge, failures matter, teams form around what works, and priorities shift when evidence changes. Much like how a lab of scientists would work on cutting edge research together.
Across GPT training optimization, biomedical ML, and protein fitness prediction, this decentralized structure consistently does better research.
Learn more 👇
@GaoShanghua@marinkazitnik@KempnerInst@HarvardDBMI@Harvard
One feature of the @biohub ESM C release that I think deserves more attention is the interpretability of its latent space.
There has been a lot of discussion about whether interpretability is useful for scientific ML models. I think it can become very useful, especially when AI agents can use a model’s internal representations to reason about biology.
Here is one example of an AI agent with access to ESM C SAE features correctly interprets the loss-of-function mechanism behind a variant.
There is still a lot to improve in how AI agents use model interpretability, but this is an exciting direction for AI agents that don’t just make predictions, but inspect learned representations to generate mechanistic hypotheses.
Read more in our blog: https://t.co/QmJlCzJVe4
We've also released the SAE-enabled skills for variant interpretation, loss-of-function analysis, structural annotation, functional mechanism interpretation, and evaluation against experimental datasets via ToolUniverse @ScientistTools
Thanks to the team behind this! @GaoShanghua@_yepeng@marinkazitnik@countablyfinite@HarvardDBMI@harvardmed@Harvard@KempnerInst
AI agents are learning to read @biohub protein models @GaoShanghua@AdaFang_@_yepeng
https://t.co/hPR7IYr9f0
We explored how AI agents powered by ToolUniverse @ScientistTools can interact with new ESM models
🧬 Mutation and loss-of-function analysis
Agents compare reference and mutant proteins, identify SAE features most affected by a mutation, and connect those perturbations to structural and functional consequences. The agents then relate these changes to experimental evidence, including deep mutational scanning measurements, to explain potential loss-of-function mechanisms
🧪 Functional mechanism exploration
Agents analyze protein representations to identify functional tracks associated with specific molecular activities. By linking SAE features to protein regions, structures, and annotations, the agents can generate hypotheses about how proteins carry out their functions
Check out new SAE-enabled ToolUniverse skills for variant interpretation, loss-of-function analysis, structural annotation, functional mechanism interpretation, and evaluation against experimental datasets
@HarvardDBMI@harvardmed@Harvard@broadinstitute@KempnerInst
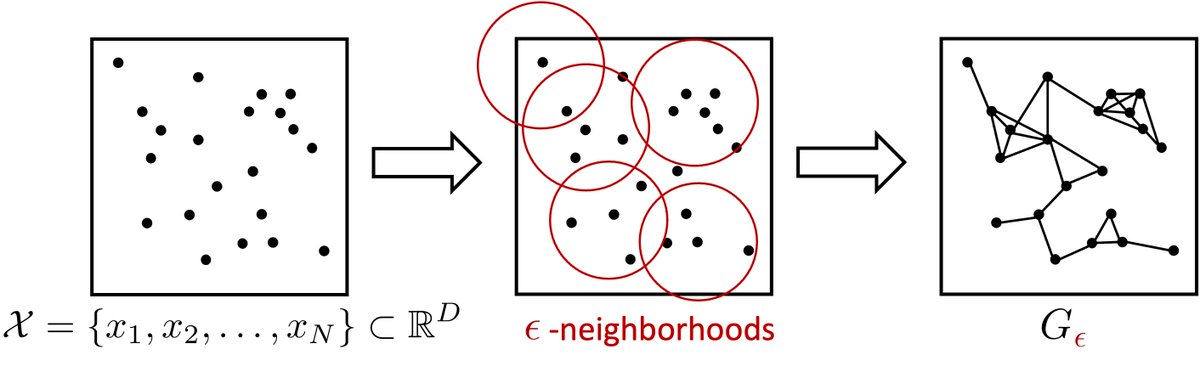
Can we learn the curvature of a data manifold from a finite sample? We study continuum limits of Ollivier’s Ricci curvature on geometric graphs, proving pointwise consistency and showing that positive lower bounds on the underlying manifold are inherited by the graph with high probability. We further discuss applications to heat kernels and manifold learning.
With Nicolás García Trillos. Now published in Discrete & Computational Geometry: https://t.co/fnArhFeMdx
How do we get LLMs to solve hard reasoning problems that the base LLM can barely solve?
We show that through bidirectional search + evolutionary mutations, we can systematically search for complex solutions and posttrain models to solve these tasks.
Our fast language localizer paper is published! https://t.co/yzP7MKRibR
In brief: You can identify fronto-temporal language regions using just a few minutes of fMRI scanning with speeded reading.
Findings + code in thread below!
With @elizj_lee* and @aloxatel@ev_fedorenko
Congratulations @biohub on the release of ESMFold2, ESMC, and ESM Atlas!
Excited to share that these models are available on day one to AI agents powered by ToolUniverse @ScientistTools
Stay tuned for agentic skills that let AI agents use SAE representations for protein variant interpretation, loss-of-function mechanism analysis, structural annotation, and mechanistic protein reasoning @GaoShanghua@AdaFang_@_yepeng
https://t.co/lWHESvWXTo
Updated preprint on naturalistic computational cognitive science from #KempnerInstitute Research Fellow Wilka Carvalho @cogscikid and @AndrewLampinen. Check out the updates:
We've updated the preprint of our Naturalistic Computational Cognitive Science paper — we've clarified and streamlined the arguments, and expanded examples where we see increasing naturalism already yielding new theoretical insights, from RL to perceptual neuroscience. 1/4
For the last NLP seminar of the quarter, we are excited to host @GretaTuckute from Harvard University!
Date and Time: Thursday, May 28, 11:00AM — 12:00 PM Pacific Time.
Zoom Link: https://t.co/jmz2wb8Xyn
Title: Learning and Representing Language in Brains and LLMs
Abstract: For the first time in history, we have a system other than the human brain that can generate fluent language: large language models (LLMs). Do the human brain and LLMs converge on shared representations and computations, and if so, what can LLMs tell us about the nature of human linguistic representations? In this talk, I will first characterize the human language network, a set of frontal and temporal brain regions that causally support language processing. I will then show that the alignment between the human language network and LLMs is strong enough that LLMs can non-invasively modulate language responses in the human brain. Moreover, this alignment can be attributed to small sets of interpretable LLM-based features, providing insight into the main axes of brain activity when humans comprehend sentences. Finally, I will turn to the question of how such linguistic representations can emerge from the messy acoustic signals that humans actually receive. I will introduce AuriStream, a self-supervised textless NLP model that learns from continuous speech and shows that linguistic structure can emerge without prespecified text tokens, given the right temporal predictive learning objective. Together, these results position LLMs as tools for characterizing the representational principles in the human language network—and AuriStream as a step toward understanding which inductive biases can give rise to human-like language representations from raw speech.
Hope to see you all there!
Can small models solve combinatorial optimization problems by learning from larger source models? We study when distillation succeeds using a GNN that is algorithmically aligned with the solution procedure. We prove that this alignment enables efficient distillation when the underlying algorithm has low decision-tree complexity.
Led by Thien Le. Learn more here: https://t.co/TNYQoywjDd