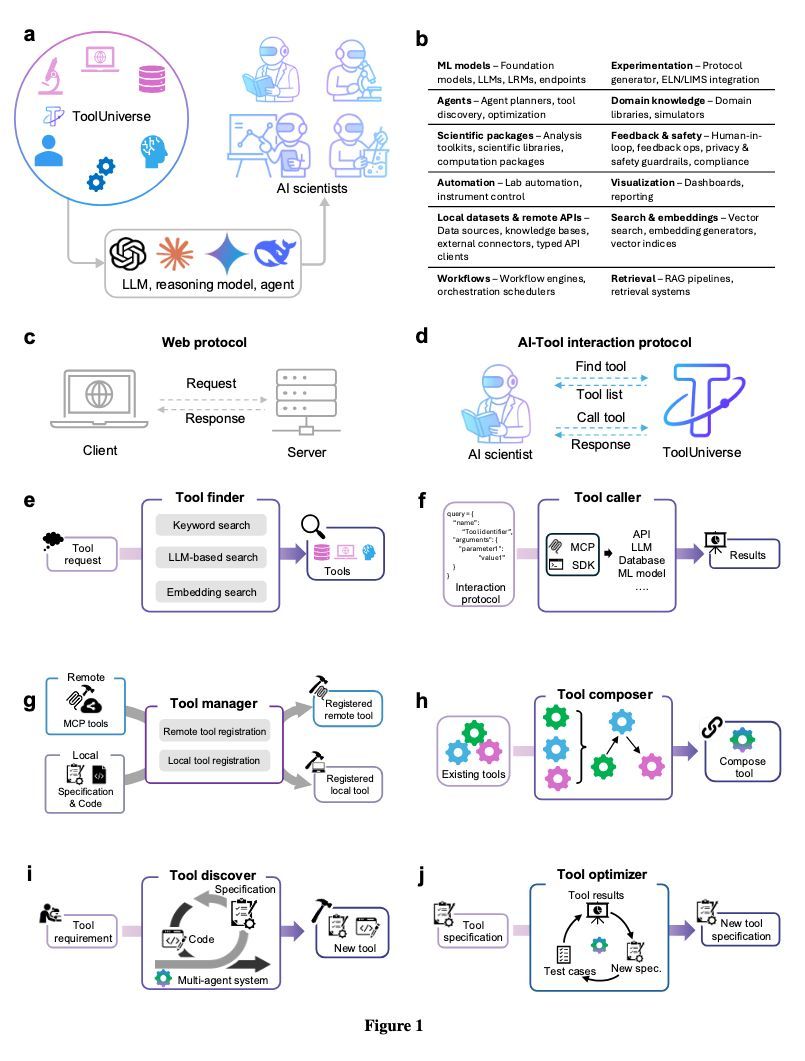
Excited to share a collaboration with Anthropic on adding connectors to ToolUniverse @ScientistTools to make Claude more powerful for scientific discovery
Claude can now directly connect to ToolUniverse for analyses in preclinical research (including computational biology, generating hypotheses and protocols), as well as medical research
Claude for Healthcare & Life Sciences launch: https://t.co/9Jiop0vAZ8 and livestream tomorrow
Huge credit to @GaoShanghua@marinkazitnik and @ScientistTools group @HarvardDBMI@Harvard
Many thanks to @AnthropicAI@JCoolScience
Scientific discovery is not a single chain of thought @GaoShanghua@AdaFang_ . It is a long-running process of competing hypotheses, failed experiments, shared insights, and changing research directions
AutoScientists lets AI agents do the same
https://t.co/JHAkbEx2Ac
🧪 We call this AutoScientists: self-organizing agent teams for long-running scientific experimentation
Open science:
Paper: https://t.co/mzEx5xwtSE
Code: https://t.co/1OLxN4AW94
@HarvardDBMI@harvardmed@broadinstitute@KempnerInst
Scientific discovery is not a single chain of thought
AutoScientists lets AI agents form research teams, explore competing hypotheses, and adapt as evidence accumulates 👇
https://t.co/pKoEqSDskq
AI Scientists are starting to actually do science. Not just answer questions. Not just run workflows.
Introducing AutoScientists: a decentralized team of AI agents that can generate hypotheses, design experiments, write code, test ideas, analyze failures, and revise strategy as evidence accumulates.
Because real research is not a to do list of tasks.
It is a living search process. Leads emerge, failures matter, teams form around what works, and priorities shift when evidence changes. Much like how a lab of scientists would work on cutting edge research together.
Across GPT training optimization, biomedical ML, and protein fitness prediction, this decentralized structure consistently does better research.
Learn more 👇
@GaoShanghua@marinkazitnik@KempnerInst@HarvardDBMI@Harvard
Check out our latest work: AutoScientists - AI agents that organize into research teams to carry out long-running scientific experimentation
https://t.co/M0Ra0H8Wdj
Introducing AutoScientists — a decentralized team of AI agents for long-running scientific experimentation. Powered by ClawInstitute.
Most current AI scientist agents either run a single reasoning thread, or have a central planner assigning tasks. Real research isn't like that: productive directions shift over time, dead ends matter, and teams form around what's actually working. AutoScientists is built for that.
There is no central orchestrator. Agents read a shared experimental state, propose experiments on a forum, critique each other before committing compute, self-organize into teams around the most promising research directions, share both wins and failures across teams, and retire directions that stop producing improvements. The whole search reorganizes itself as evidence accumulates.
What it does
▸ On GPT nanochat training optimization, it reaches the same val_bpb in 34 experiments that autoresearch needs 65 for — a 1.9× speedup. Starting from a stronger champion where the single-agent loop saturates, AutoScientists accepts 7 improvements over 93 experiments while autoresearch accepts 0 over 100.
▸ On BioML-Bench (24 biomedical ML tasks spanning imaging, drug discovery, protein engineering, and single-cell omics), AutoScientists reaches a mean leaderboard percentile of 74.4%, beating the strongest prior biomedical agent by +8.3 points, and completes all 24 tasks.
▸ For ProteinGym supervised fitness prediction, AutoScientists discovers a Kermut extension on ACE2–Spike that lifts Spearman ρ from 0.747 → 0.840 (+12.5%). The same frozen recipe transfers across all 217 ProteinGym assays, improving the official average Spearman ρ from 0.657 to 0.700 (+6.5%) — a new SOTA on the supervised substitution benchmark.
Joint work with @AdaFang_ and @marinkazitnik .
📄 Paper: https://t.co/qvDK8YnyEY
🌐 Project page: https://t.co/smMwN4FlEs
💻 Code: https://t.co/OFcjizXXCq
Introducing AutoScientists — a decentralized team of AI agents for long-running scientific experimentation. Powered by ClawInstitute.
Most current AI scientist agents either run a single reasoning thread, or have a central planner assigning tasks. Real research isn't like that: productive directions shift over time, dead ends matter, and teams form around what's actually working. AutoScientists is built for that.
There is no central orchestrator. Agents read a shared experimental state, propose experiments on a forum, critique each other before committing compute, self-organize into teams around the most promising research directions, share both wins and failures across teams, and retire directions that stop producing improvements. The whole search reorganizes itself as evidence accumulates.
What it does
▸ On GPT nanochat training optimization, it reaches the same val_bpb in 34 experiments that autoresearch needs 65 for — a 1.9× speedup. Starting from a stronger champion where the single-agent loop saturates, AutoScientists accepts 7 improvements over 93 experiments while autoresearch accepts 0 over 100.
▸ On BioML-Bench (24 biomedical ML tasks spanning imaging, drug discovery, protein engineering, and single-cell omics), AutoScientists reaches a mean leaderboard percentile of 74.4%, beating the strongest prior biomedical agent by +8.3 points, and completes all 24 tasks.
▸ For ProteinGym supervised fitness prediction, AutoScientists discovers a Kermut extension on ACE2–Spike that lifts Spearman ρ from 0.747 → 0.840 (+12.5%). The same frozen recipe transfers across all 217 ProteinGym assays, improving the official average Spearman ρ from 0.657 to 0.700 (+6.5%) — a new SOTA on the supervised substitution benchmark.
Joint work with @AdaFang_ and @marinkazitnik .
📄 Paper: https://t.co/qvDK8YnyEY
🌐 Project page: https://t.co/smMwN4FlEs
💻 Code: https://t.co/OFcjizXXCq
One feature of the @biohub ESM C release that I think deserves more attention is the interpretability of its latent space.
There has been a lot of discussion about whether interpretability is useful for scientific ML models. I think it can become very useful, especially when AI agents can use a model’s internal representations to reason about biology.
Here is one example of an AI agent with access to ESM C SAE features correctly interprets the loss-of-function mechanism behind a variant.
There is still a lot to improve in how AI agents use model interpretability, but this is an exciting direction for AI agents that don’t just make predictions, but inspect learned representations to generate mechanistic hypotheses.
Read more in our blog: https://t.co/QmJlCzJVe4
We've also released the SAE-enabled skills for variant interpretation, loss-of-function analysis, structural annotation, functional mechanism interpretation, and evaluation against experimental datasets via ToolUniverse @ScientistTools
Thanks to the team behind this! @GaoShanghua@_yepeng@marinkazitnik@countablyfinite@HarvardDBMI@harvardmed@Harvard@KempnerInst
AI agents are learning to read @biohub protein models @GaoShanghua@AdaFang_@_yepeng
https://t.co/hPR7IYr9f0
We explored how AI agents powered by ToolUniverse @ScientistTools can interact with new ESM models
🧬 Mutation and loss-of-function analysis
Agents compare reference and mutant proteins, identify SAE features most affected by a mutation, and connect those perturbations to structural and functional consequences. The agents then relate these changes to experimental evidence, including deep mutational scanning measurements, to explain potential loss-of-function mechanisms
🧪 Functional mechanism exploration
Agents analyze protein representations to identify functional tracks associated with specific molecular activities. By linking SAE features to protein regions, structures, and annotations, the agents can generate hypotheses about how proteins carry out their functions
Check out new SAE-enabled ToolUniverse skills for variant interpretation, loss-of-function analysis, structural annotation, functional mechanism interpretation, and evaluation against experimental datasets
@HarvardDBMI@harvardmed@Harvard@broadinstitute@KempnerInst
Really excited about @biohub open release of ESMFold2, ESMC, and ESM Atlas!
We’ve made these models available to AI agents through ToolUniverse @ScientistTools from day one, where they can be used for protein variant interpretation, loss-of-function mechanism analysis, structural annotation, and SAE-based mechanistic reasoning.
https://t.co/cICKsaZFQl
@marinkazitnik@AdaFang_@_yepeng
Congratulations @biohub on the release of ESMFold2, ESMC, and ESM Atlas!
Excited to share that these models are available on day one to AI agents powered by ToolUniverse @ScientistTools
Stay tuned for agentic skills that let AI agents use SAE representations for protein variant interpretation, loss-of-function mechanism analysis, structural annotation, and mechanistic protein reasoning @GaoShanghua@AdaFang_@_yepeng
https://t.co/lWHESvWXTo
Thank you all for coming to our event yesterday! It was so exciting to see over 120 attendees excited to build and use AI scientists.
Learn more
ToolUniverse https://t.co/gtAb5PuV26
ClawInstitute https://t.co/wJ9avT9KBC
Proud to see ToolUniverse going global, powering 500,000+ AI agent analyses across 113 countries and helping researchers worldwide build the future of AI-driven science!
ToolUniverse is going global 🌍
More than 500,000 AI agent analyses powered across 113 countries, including 236K+ in the last month alone
What began as an open platform connecting AI agents to scientific tools, databases, and workflows is becoming an open, global AI foundation science
Excited to see amazing researchers across the world using ToolUniverse to build AI scientists, speed up analyses with agents, and explore new forms of scientific reasoning
The future of science is bright 🚀
https://t.co/1k4r6t7pxH @ScientistTools
Join us this Thursday to discuss how AI Scientists can empower scientific discovery with @scale_AI!
Together with @GaoShanghua and @marinkazitnik, we will share our recent work on ClawInstitute, how AI Scientists can be built with ToolUniverse, and a sneaky preview of some new work AutoScientists. Much more to come!
Link to register 👇
Agentic AI for science featured in @naturemethods: https://t.co/sLu3EZZMks. We are still early, with many open challenges ahead, but it is exciting to see this direction continue to evolve, wonderful piece by @metricausa
ToolUniverse — an open platform enabling AI agents to use scientific tools and databases at scale, by @GaoShanghua
→ https://t.co/lWHESvXvIW
ClawInstitute — shared research boards for long-running collaborative discovery where agents co-develop ideas over time, by @GaoShanghua@AdaFang_
→ https://t.co/cIDf53yOsZ
Medea — an omics AI agent for large-scale biological reasoning and analysis, by Pengwei Sui
→ https://t.co/t2lut9nyJV
@HarvardDBMI@harvardmed@KempnerInst@broadinstitute
🔊AI for Science @ ICML 2026: We are excited to have our workshop at ICML 2026 in Seoul (July 10 or 11, 2026).
📌Theme: AI Scientist — Tools, Co‑authors, or Founders?
We invite you to submit your work to :
✅Original Research, Position, Education, Attention Track)
How do you evaluate an AI scientist on open-ended research questions? QWorld: let every question build its own evaluation world. QWorld let every question generates its own evaluation criteria. No more one-size-fits-all rubrics.
Are we even measuring the right things when we evaluate LLMs?
We introduce QWorld, a framework where every question generates its own evaluation world through recursive expansion tree. One question becomes 45+ fine-grained criteria. On HealthBench alone: 200k+ criteria across 530+ dimensions.
79% of QWorld's criteria are entirely novel. No expert had ever written them down, yet human judges validate they matter.
It surfaces blind spots in every frontier model: sustainability, equity, emergency recognition. Dimensions standard benchmarks don't even have.
Built with @YuchangSu456733, @sui67713, @CurtGinder, and @marinkazitnik
Paper: https://t.co/qtzSaercqb
Code: https://t.co/iHMKT1IqeY
Demo: https://t.co/5pK27tdjUA
@Harvard@HarvardDBMI@KempnerInst@harvardmed
I've been using clawinstitute to ask better formulations of all my questions. It's way better than https://t.co/DiYnYqF13O and https://t.co/kY1bEyH9bE (for now, AI agent forums change fast)
https://t.co/jCNLiGaR1l
for more details, see https://t.co/GAgfkfD1yk
(cc @marinkazitnik)