📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: https://t.co/y3AupX3Pa0
✅ Qwen Studio: https://t.co/qpTnrCBjWt
⚡️ API:https://t.co/0sys00osKn
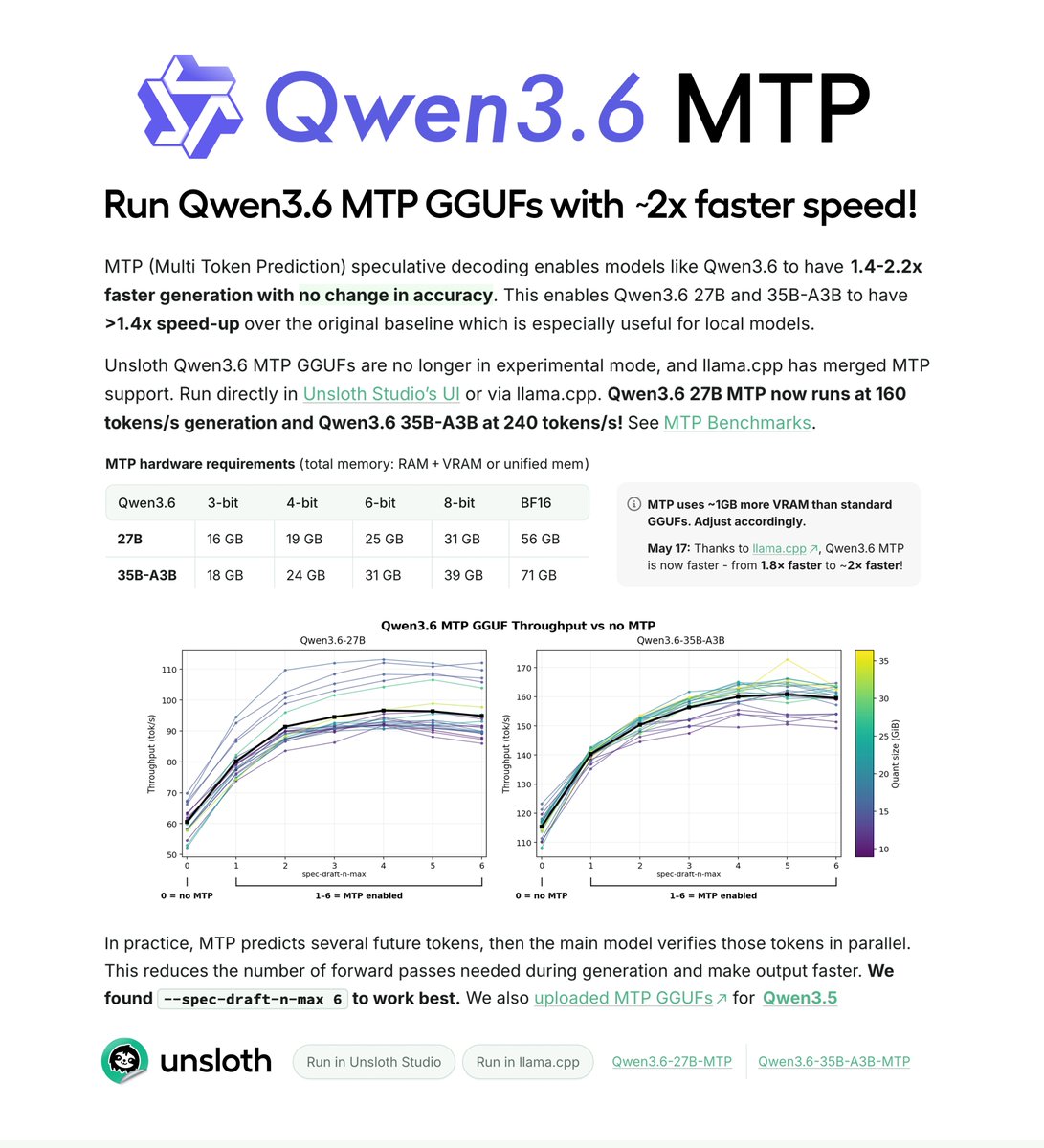
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: https://t.co/7gWhKnseZo
Guide: https://t.co/7qzk6ypWDQ
DFlash for Gemma 4: Up to 6x Faster. ⚡⚡
Great to see MTP land natively in Gemma 4 today. If you want to push it further, try DFlash — open source, same quality, more speed!!
https://t.co/wKcRoibuOB
Took it further with @omma_ai, (@splinetool ) now it works on video, and everything working in a Web Browser.
Drop a video, Depth Anything v2 calculates the depth map frame by frame, and Three.js renders a fully lit 3D mesh in real time.
Depth estimation on video in the browser
+Automatic baking pass
+ Dynamic lighting reacting to the geometry
#vibecoding #threejs #webgl
LTX HDR beta is now live.
Every AI video model before this one output 8-bit SDR only. Fine for social clips. The format falls apart the moment you try to grade. Highlights clip. Shadows crush. AI footage won't composite cleanly against higher-bit-depth CGI.
Resolution was never the real issue. Dynamic range was.
Alongside the ReFocus IC-LoRA, I've also released Uncompress which removes mp4 compression artifacts. These IC-LoRAs are incredibly easy to train, any artist/studio can make their own powered with @ltx_model
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
MiniMax Music 2.6 is live.
A few things worth knowing:
🎬 Original BGM in minutes
No more hunting for "probably fine to use" tracks. Describe your scene, get something fully yours.
🎭 Structure that actually follows your prompt.
You can now write "open with tension, build toward awakening, explode into triumph", and the model follows, beat by beat.
For the first time, AI music generation feels less like rolling the dice and more like directing.
🎤 Intentional imperfection
In lo-fi, indie folk, jazz — the breathiness that makes a track feel human, not generated.
Also shipping with 2.6:
→ First audio in under 20s: write a prompt, take a breath, it's ready
→ Improved low-mid frequency response: tighter bass for House, Trap, Drum & Bass
→ Style transfer & remixing: reimagine your own melody in a completely different genre
14-day free global beta starts today (500 songs/day).
👉Try now: https://t.co/oGNTfjD57b
Releasing FLUX.2 Small Decoder: a faster, drop-in replacement for our standard decoder.
→ ~1.4x faster
→ Lower peak VRAM - decode larger images without running out of memory
→ Minimal quality loss
→ Works with FLUX.2 out of the box
Especially impactful for real-time and larger resolutions pipelines.
Let me local AI pill you:
1. It sucks compared to SOTA
2. It can’t code so well
3. It can be a good agent
4. It can be great at chat
5. It can be fine as a researcher
6. It can be a great automation engine
7. It can be tuned however you want
8. It teaches you how the sausage is made
9. It works on a plane, or in an outage
10. It costs your electric bill + hardware
11. It is better than the AI we gave up coding for a year or 2 ago.
Local AI is self defence, it is a go kit, it is a rebalancing of power.
It’s delusional to think it approaches or will ever approach SOTA, the scale of private labs blows anything you can get for less than 25k USD out the water.
Local AI is a bet that prices won’t stay this low, that private corporations with closed source weights can’t be trusted to stay consistent.
I am more than happy to rent a Ferrari for dirt cheap, but i should also have a beater Toyota if I can afford it.
Local AI is the car I can depend on to be there tomorrow, something that’s mine.