Trevor was making a joke in reference to anthro, but jokes on him, ...
Intel's compiler *did* intentionally generate worse code for AMD, called the "cripple AMD feature".
Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?
"Terrible things are happening outside. Poor helpless people are being dragged out of their homes. Families are torn apart.
Men, women, and children are separated. Children come home from school to find that their parents have disappeared."
Diary of Anne Frank
January 13, 1943
I study authoritarianism for a living, so I do not say this lightly: America isn't facing an authoritarian future. America is living an authoritarian present.
(A long 🧵)
/1
The single biggest argument about statistics: is probability frequentist or Bayesian?
It's neither, and I'll explain why.
Buckle up. Deep-dive explanation incoming.
If you’re an "ML Engineer" and you think “Transformer” just means stacking encoder–decoder blocks and calling it a day, you’re missing the actual mechanism that makes modern AI work.
Concept 16: The Transformer Is a Math Engine, Not a “Model Architecture
"Most people can implement a Transformer pipeline. Very few can explain why the Transformer works."
Let’s break it down properly.
1. The core idea, Transformers = Vector Field Manipulation
Every layer of a Transformer applies three mathematical operations:
1. Projection
2. Attention as weighted integration
3. Update via residual fields
The Transformer is basically a learned vector field processor.
Not a sequence model.
Not an architecture choice.
It could be called a mathematical engine that maps token representations through a series of controlled linear and nonlinear transformations.
2. Attention is not magic, it is a quadratic form. (Take a minute while reading this part)
Self-attention computes:
Attention(Q, K, V) = softmax(QKᵀ / √d) V
This means:
• QKᵀ is a similarity matrix
• softmax turns similarities into probability weights
• multiplying by V computes a weighted expectation over token values
Attention = learnable, data-dependent kernel smoothing.
It is a kernel machine inside your neural network.
3. Multi-head attention = multiple kernels in parallel
Each head learns a different geometry of similarity. One head may focus on local patterns, another on long-range dependencies, another on syntax, another on semantics.
When people say “transformers understand context,” this is what they mean:
each head builds a different function approximator.
4. Residual connections are the true backbone
Forget attention. Residuals are the reason Transformers train at all if you look at it properly.
xₜ₊₁ = xₜ + f(xₜ)
This means every layer learns a correction to the current representation. Gradient flow stays stable. Representations evolve smoothly.
Without residuals, Transformers collapse.
5. LayerNorm = curvature control
Norms scale the Jacobian of each layer.
This keeps the singular values of the mapping from blowing up or collapsing.
LayerNorm is not cosmetic. It is what ensures the model doesn’t EXPLODE internally.
6. Feedforward layers = feature expansion and contraction
The FFN block:
FFN(x) = W₂ σ(W₁ x)
expands dimension, applies a nonlinearity, then compresses.
This lets the model create new features that attention alone cannot express.
It acts as a learned universal approximator inside each layer.
7. Why people can code Transformers but not explain them
Because coding a transformer is wiring blocks together. Understanding a transformer requires knowing:
• attention as kernel regression
• softmax as a probability normalizer
• LayerNorm as Jacobian control
• residuals as stable integration
• FFN as feature synthesis
• positional encodings as geometric priors
• multi-head structure as an ensemble of learned kernels
Most people never go beyond surface-level implementation is something I realised when I caught myself trying to work on advanced papers without actually understanding the fundamentals.
TL;DR
The Transformer works because its math is designed to stabilize gradients, amplify structure, and integrate information the way a continuous dynamical system would.
It is not “just an architecture.”
It is the most efficient numerical method we’ve found for learning functions over sequences, graphs, and basically anything with structure.
We've become obsessed with the idea that the brain is a "Prediction Machine."
The dominant theory in neuroscience says we're constantly simulating the future, calculating probabilities to guess what happens next.
A new paper argues this is a complete illusion. The reality is simpler, and strangely, much more powerful.
Here is the argument for Perceptual Control:
The "Prediction Illusion" starts with a mistake in observation.
When we see someone successfully handle a chaotic environment (like catching a flyball), it *looks* like they predicted the future trajectory of the ball.
But observing prediction isn't the same as implementing it.
The authors use the perfect analogy: The Watt’s Steam Governor.
In the 19th century, this device kept steam engines running at a constant speed. If pressure surged, it slowed the engine. If load increased, it sped up.
To an observer, it looked like the machine was "predicting" pressure surges and pre-empting them.
But the Governor has no brain. It has no model of the future.
It’s a mechanical negative feedback loop. [cite_start]It measures the *current* speed, compares it to the *desired* speed, and adjusts the valve immediately[cite: 80].
It doesn't predict; it controls.
This brings us to the "Hello" experiment, which broke my brain a little.
Researchers asked people to keep a computer cursor on a target. The computer applied a "disturbance" (forces pushing the cursor away) that the person had to fight against with their mouse.
Here's the twist:
The disturbance wasn't random. [cite_start]It was an invisible force field shaped like the word "hello" (written upside down and mirrored)[cite: 166].
The participants fought the force, keeping the cursor steady.
When researchers looked at the participants' hand movements, they had perfectly written the word "hello".
Crucially, the participants had NO idea they were writing words.
If the brain were a "prediction machine," it would have needed to model the force to predict the hand movement.
But the participants wrote a legible word purely by reacting to immediate error signals—instantaneously correcting the cursor's position.
This is **Perceptual Control Theory (PCT)**.
The theory suggests the nervous system isn't a linear pipeline (Input → Compute → Output).
It’s a closed loop. We act to keep our *perception* of the world matching our internal *reference value*.
[Image of Perceptual Control Theory negative feedback loop diagram]
Think about catching a baseball.
If you were a "prediction machine," you’d calculate the ball's trajectory, wind speed, and gravity, then run to where the ball *will* be.
But that’s computationally expensive and error-prone.
In reality, fielders just run in a way that keeps the "optical velocity" of the ball constant in their vision.
If the ball looks like it's rising too fast, they move back. Dropping? They move forward.
No physics calculus required. Just maintaining a visual constant.
This solves the "Noise" problem.
In predictive models, small jitters in your movement are considered "noise" or errors to be filtered out.
It’s the system "feeling out" the environment to maintain control.
This has huge implications for AI and robotics.
We are currently building robots with massive compute power to "predict" stability.
But robots built on PCT principles—like inverted pendulums that just react to maintain verticality—are often more robust and stable than the predictive ones.
Why does this matter for you?
It changes how we view "agency."
We often think we need to predict the outcome of our actions to be effective. [cite_start]But the most efficient systems don't predict the outcome—they specify the goal and let the feedback loop handle the rest[cite: 39].
The "Prediction Illusion" suggests we aren't prophets simulating the future.
We are controllers, surfing the present.
We don't need to know what the wave will do in 10 seconds. We just need to keep the board steady right now.
If you want to dig into the paper, it’s "The prediction illusion: perceptual control mechanisms that fool the observer" by Mansell, Gulrez, and Landman (2025).
It’s a dense read, but it completely reframes the "Bayesian Brain" debate.
One final thought:
Next time you're doing something skilled—driving, typing, sports—notice the difference.
Are you calculating what comes next? Or are you just managing the gap between *what you see* and *what you want*?
You might find you're doing a lot less "thinking" than you assumed.
Many dimensionality reduction algorithms share a few central principles.
1. Construct a graph that captures the data's local structure
2. Measure "geodesic" distances between points using the graph
3. Project the points to a lower dimension while preserving these distances
Frontier AI reasoning systems are now closing the complexity scaling gap between ARC-AGI-1 and ARC-AGI-2
This is surprising, as these same systems also make obvious mistakes on easy tasks (for humans) from ARC-AGI-1. We're not sure why and invite help from the community to study this phenomenon
Full solution logs are linked in last tweet
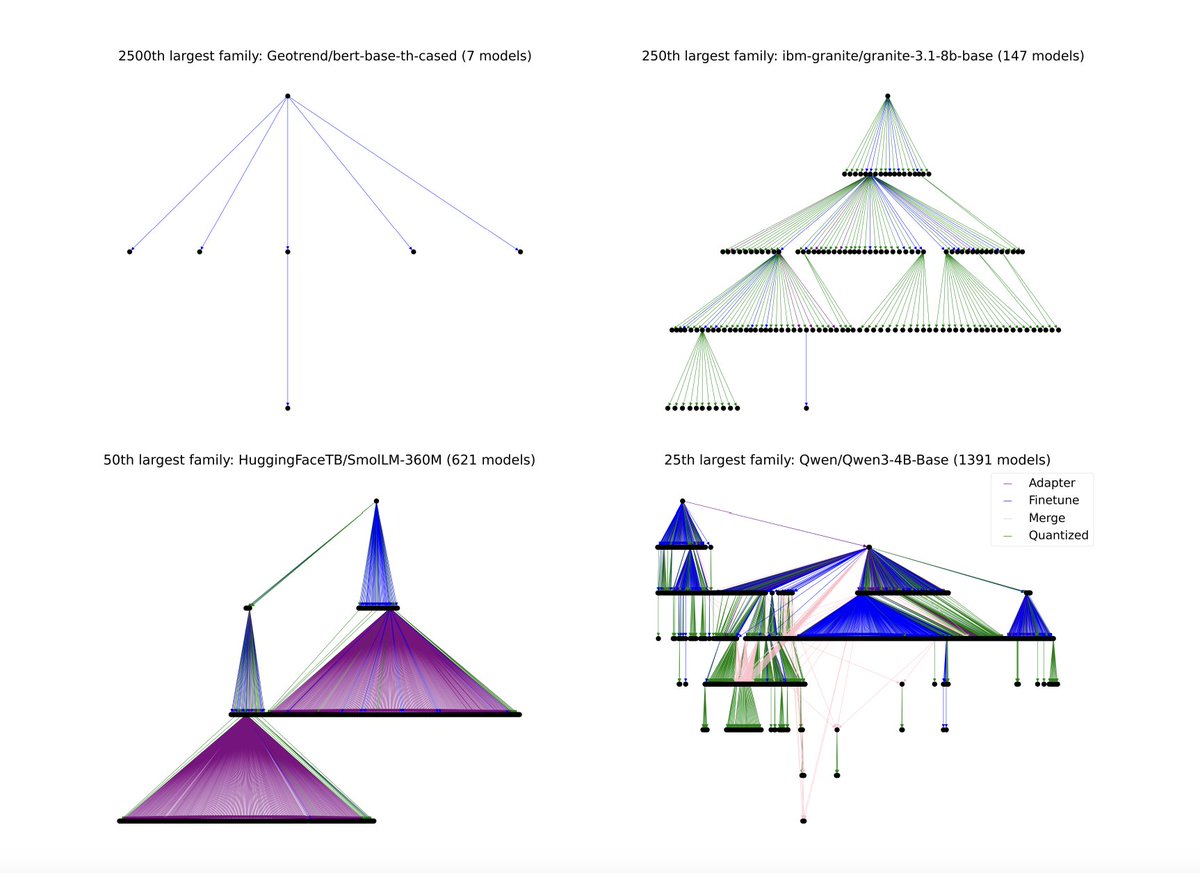
Fun to think about open-source models and their variants as families from an evolutionary biology standpoint and analyze "genetic similarity and mutation of traits over model families".
These are the 2,500th, 250th, 50th and 25th largest families on @huggingface:
Huge computer science result:
A Tsinghua professor JUST discovered the fastest shortest path algorithm for graphs in 40yrs.
This improves on Turing award winner Tarjan’s O(m + nlogn) with Dijkstra’s, something every Computer Science student learns in college.
Today, we're introducing AlphaEarth Foundations from @GoogleDeepMind , an AI model that functions like a virtual satellite which helps scientists make informed decisions on critical issues like food security, deforestation, and water resources. AlphaEarth Foundations provides a powerful new lens for understanding our planet by solving two major challenges: data overload and inconsistent information.
1️⃣ It combines information from dozens of sources to analyze the world's land and coastal waters in 10x10 meter squares, allowing for remarkable precision while tracking changes over time.
2️⃣ The system's key innovation is creating a highly compact summary for each square. These summaries require 16x less storage than those produced by other AI systems and enables scientists to create detailed, consistent maps of our planet, on-demand.
AlphaEarth Foundations represents a significant step forward in understanding the state and dynamics of our changing planet. 🌎🌎🌎
iText2KG: an open source Python package designed to incrementally construct consistent knowledge graphs with resolved entities and relations
iText2KG v0.0.8 is out, and it can now build dynamic knowledge graphs.
iText2KG is a Python package designed to incrementally construct consistent knowledge graphs with resolved entities and relations by leveraging large language models for entity and relation extraction from text documents. It features zero-shot capability, allowing for knowledge extraction across various domains without specific training.
The package includes modules for document distillation, entity extraction, and relation extraction, ensuring resolved and unique entities and relationships. It continuously updates the KG with new documents and integrates them into Neo4j for visual representation.
Main new features:
- iText2KG_Star: Introduced a simpler and more efficient version of iText2KG that eliminates the separate entity extraction step.
Instead of extracting entities and relations separately, iText2KG_Star directly extracts relationships from text. This approach is more efficient as it reduces processing time and token consumption and does not need to handle invented/isolated entities.
- Facts-Based KG Construction: Enhanced the framework with facts-based knowledge graph construction.
It's using the Document Distiller to extract structured facts from documents, which are then used for incremental KG building. This approach provides more exhaustive and precise knowledge graphs.
- Dynamic Knowledge Graphs: iText2KG now supports building dynamic knowledge graphs that evolve.
By leveraging the incremental nature of the framework and document snapshots with observation dates, users can track how knowledge changes and grows.
By Yassir Lairgi.
https://t.co/YuxXCez7Tl
#KnowledgeGraph #AI #OpenSource #EntityResolution #Python #DataScience #LLM #InformationExtraction #RAG #GenAI
--
The Year of the Graph's next newsletter on all things Knowledge Graph, Graph Analytics / Data Science / AI and Semantic Tech is due in Autumn 2025.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
https://t.co/7pg6gqWYvw








![IntuitMachine's tweet photo. We've become obsessed with the idea that the brain is a "Prediction Machine."
The dominant theory in neuroscience says we're constantly simulating the future, calculating probabilities to guess what happens next.
A new paper argues this is a complete illusion. The reality is simpler, and strangely, much more powerful.
Here is the argument for Perceptual Control:
The "Prediction Illusion" starts with a mistake in observation.
When we see someone successfully handle a chaotic environment (like catching a flyball), it *looks* like they predicted the future trajectory of the ball.
But observing prediction isn't the same as implementing it.
The authors use the perfect analogy: The Watt’s Steam Governor.
In the 19th century, this device kept steam engines running at a constant speed. If pressure surged, it slowed the engine. If load increased, it sped up.
To an observer, it looked like the machine was "predicting" pressure surges and pre-empting them.
But the Governor has no brain. It has no model of the future.
It’s a mechanical negative feedback loop. [cite_start]It measures the *current* speed, compares it to the *desired* speed, and adjusts the valve immediately[cite: 80].
It doesn't predict; it controls.
This brings us to the "Hello" experiment, which broke my brain a little.
Researchers asked people to keep a computer cursor on a target. The computer applied a "disturbance" (forces pushing the cursor away) that the person had to fight against with their mouse.
Here's the twist:
The disturbance wasn't random. [cite_start]It was an invisible force field shaped like the word "hello" (written upside down and mirrored)[cite: 166].
The participants fought the force, keeping the cursor steady.
When researchers looked at the participants' hand movements, they had perfectly written the word "hello".
Crucially, the participants had NO idea they were writing words.
If the brain were a "prediction machine," it would have needed to model the force to predict the hand movement.
But the participants wrote a legible word purely by reacting to immediate error signals—instantaneously correcting the cursor's position.
This is **Perceptual Control Theory (PCT)**.
The theory suggests the nervous system isn't a linear pipeline (Input → Compute → Output).
It’s a closed loop. We act to keep our *perception* of the world matching our internal *reference value*.
[Image of Perceptual Control Theory negative feedback loop diagram]
Think about catching a baseball.
If you were a "prediction machine," you’d calculate the ball's trajectory, wind speed, and gravity, then run to where the ball *will* be.
But that’s computationally expensive and error-prone.
In reality, fielders just run in a way that keeps the "optical velocity" of the ball constant in their vision.
If the ball looks like it's rising too fast, they move back. Dropping? They move forward.
No physics calculus required. Just maintaining a visual constant.
This solves the "Noise" problem.
In predictive models, small jitters in your movement are considered "noise" or errors to be filtered out.
It’s the system "feeling out" the environment to maintain control.
This has huge implications for AI and robotics.
We are currently building robots with massive compute power to "predict" stability.
But robots built on PCT principles—like inverted pendulums that just react to maintain verticality—are often more robust and stable than the predictive ones.
Why does this matter for you?
It changes how we view "agency."
We often think we need to predict the outcome of our actions to be effective. [cite_start]But the most efficient systems don't predict the outcome—they specify the goal and let the feedback loop handle the rest[cite: 39].
The "Prediction Illusion" suggests we aren't prophets simulating the future.
We are controllers, surfing the present.
We don't need to know what the wave will do in 10 seconds. We just need to keep the board steady right now.
If you want to dig into the paper, it’s "The prediction illusion: perceptual control mechanisms that fool the observer" by Mansell, Gulrez, and Landman (2025).
It’s a dense read, but it completely reframes the "Bayesian Brain" debate.
One final thought:
Next time you're doing something skilled—driving, typing, sports—notice the difference.
Are you calculating what comes next? Or are you just managing the gap between *what you see* and *what you want*?
You might find you're doing a lot less "thinking" than you assumed.](https://pbs.twimg.com/media/G6Nb5h3WAAAUIFP.jpg)

























![IntuitMachine's tweet photo. We've become obsessed with the idea that the brain is a "Prediction Machine."
The dominant theory in neuroscience says we're constantly simulating the future, calculating probabilities to guess what happens next.
A new paper argues this is a complete illusion. The reality is simpler, and strangely, much more powerful.
Here is the argument for Perceptual Control:
The "Prediction Illusion" starts with a mistake in observation.
When we see someone successfully handle a chaotic environment (like catching a flyball), it *looks* like they predicted the future trajectory of the ball.
But observing prediction isn't the same as implementing it.
The authors use the perfect analogy: The Watt’s Steam Governor.
In the 19th century, this device kept steam engines running at a constant speed. If pressure surged, it slowed the engine. If load increased, it sped up.
To an observer, it looked like the machine was "predicting" pressure surges and pre-empting them.
But the Governor has no brain. It has no model of the future.
It’s a mechanical negative feedback loop. [cite_start]It measures the *current* speed, compares it to the *desired* speed, and adjusts the valve immediately[cite: 80].
It doesn't predict; it controls.
This brings us to the "Hello" experiment, which broke my brain a little.
Researchers asked people to keep a computer cursor on a target. The computer applied a "disturbance" (forces pushing the cursor away) that the person had to fight against with their mouse.
Here's the twist:
The disturbance wasn't random. [cite_start]It was an invisible force field shaped like the word "hello" (written upside down and mirrored)[cite: 166].
The participants fought the force, keeping the cursor steady.
When researchers looked at the participants' hand movements, they had perfectly written the word "hello".
Crucially, the participants had NO idea they were writing words.
If the brain were a "prediction machine," it would have needed to model the force to predict the hand movement.
But the participants wrote a legible word purely by reacting to immediate error signals—instantaneously correcting the cursor's position.
This is **Perceptual Control Theory (PCT)**.
The theory suggests the nervous system isn't a linear pipeline (Input → Compute → Output).
It’s a closed loop. We act to keep our *perception* of the world matching our internal *reference value*.
[Image of Perceptual Control Theory negative feedback loop diagram]
Think about catching a baseball.
If you were a "prediction machine," you’d calculate the ball's trajectory, wind speed, and gravity, then run to where the ball *will* be.
But that’s computationally expensive and error-prone.
In reality, fielders just run in a way that keeps the "optical velocity" of the ball constant in their vision.
If the ball looks like it's rising too fast, they move back. Dropping? They move forward.
No physics calculus required. Just maintaining a visual constant.
This solves the "Noise" problem.
In predictive models, small jitters in your movement are considered "noise" or errors to be filtered out.
It’s the system "feeling out" the environment to maintain control.
This has huge implications for AI and robotics.
We are currently building robots with massive compute power to "predict" stability.
But robots built on PCT principles—like inverted pendulums that just react to maintain verticality—are often more robust and stable than the predictive ones.
Why does this matter for you?
It changes how we view "agency."
We often think we need to predict the outcome of our actions to be effective. [cite_start]But the most efficient systems don't predict the outcome—they specify the goal and let the feedback loop handle the rest[cite: 39].
The "Prediction Illusion" suggests we aren't prophets simulating the future.
We are controllers, surfing the present.
We don't need to know what the wave will do in 10 seconds. We just need to keep the board steady right now.
If you want to dig into the paper, it’s "The prediction illusion: perceptual control mechanisms that fool the observer" by Mansell, Gulrez, and Landman (2025).
It’s a dense read, but it completely reframes the "Bayesian Brain" debate.
One final thought:
Next time you're doing something skilled—driving, typing, sports—notice the difference.
Are you calculating what comes next? Or are you just managing the gap between *what you see* and *what you want*?
You might find you're doing a lot less "thinking" than you assumed.](https://pbs.twimg.com/media/G6Nb5h_W4AAGxbo.jpg)