A beautiful example of an "optimal stopping problem" – Feynman's restaurant problem – with a great backstory behind it. This is a fun, well written article, and a fun math problem too.
https://t.co/0Nng9KLDHa
Vincenzo Viviani was born on this day in 1622. He is most famous for Viviani's Theorem
In an equilateral triangle, the sum of the perpendicular distances from any interior point to the 3 sides is equal to the height of the triangle.
Nikolay Bogdanov-Belsky's famous painting, "Mental Arithmetic. In the Public School of S. Rachinsky." The math problem the boys are trying to solve on the board is (10²+11²+12²+13²+14²)/365.
Ferrari: —Es curioso: usted habla últimamente cada vez más de la aceptación y la gratitud.
Borges: —Es que yo creo, como Chesterton, que uno debería agradecer todo. Chesterton dijo que el hecho, bueno, de estar sobre la Tierra, de estar de pie sobre la Tierra, de ver el cielo, bueno, de haber estado enamorado, son como dones que uno no puede cesar de agradecer. Y yo trato de sentir eso, y he tratado de sentir, por ejemplo, que mi ceguera no es sólo una desventura, aunque ciertamente lo es, sino que también me permite, bueno, me da más tiempo para la soledad, para el pensamiento, para la invención de fábulas, para la fabricación de poesías. Es decir, que todo eso es un bien, ¿no? Recuerdo aquello de aquel griego, Demócrito, que se arrancó los ojos en un jardín para que no le estorbara la contemplación del mundo externo. Bueno, en un poema yo dije: "El tiempo ha sido mi Demócrito". Es verdad, yo ahora estoy ciego, pero quizás el estar ciego no sea solamente una tristeza. Aunque me basta pensar en los libros, que están tan cerca y que están tan lejos de mí, para, bueno, para querer ver. Y hasta llego a pensar que si yo recobrara mi vista, yo no saldría de esta casa y me pondría a leer todos los libros que tengo aquí, y que apenas conozco, aunque los conozco por la memoria, que modifica las cosas.
LIBRO DE DIÁLOGOS
BORGES - FERRARI
Editorial Sudamericana.
(1986 / 1987 / 1999).
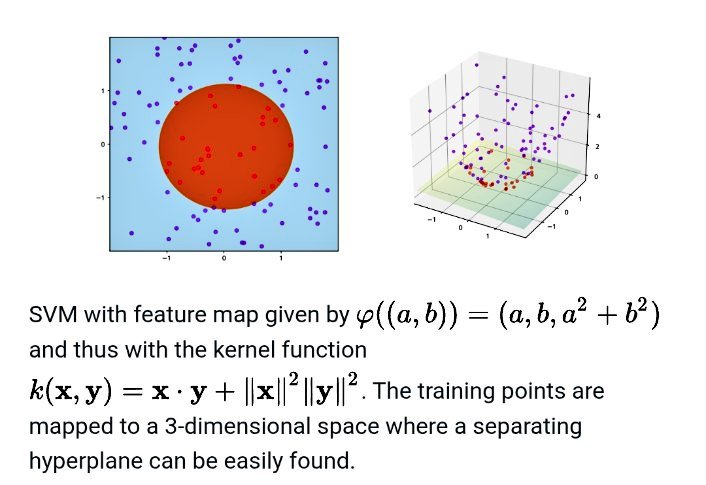
Kernel methods are making a quiet comeback in the age of foundation models because they offer strong theoretical guarantees, data efficiency, and interpretability in regimes where massive neural networks are costly, unstable, or overkill. Mathematically, kernels embed data into high- or infinite-dimensional Hilbert spaces where linear methods become powerful, relying on tools such as reproducing kernel Hilbert spaces, spectral theory, Mercer’s theorem, and concentration inequalities. In probability and statistics, kernels connect to Gaussian processes, covariance operators, and characteristic functions, enabling uncertainty quantification and principled generalization. In machine learning, modern scalable approximations—random features, Nyström methods, and structured kernels—allow kernel models to handle millions of points efficiently. As foundation models dominate representation learning, kernels are increasingly used for calibration, adaptation, and low-data fine-tuning, where their convex optimization and stability are advantageous. This blend of deep representations with kernel learning revives classical math in a new, complementary role for trustworthy and efficient AI.
In 1876, James Abram Garfield (1831–1881), who served as the twentieth President of the United States, published a new proof of the Pythagorean theorem in the New England Journal of Education.
Is there any single inequality in all of Mathematics with this much reach? It’s incredible🤯
Cauchy-Schwarz inequality looks almost too plain to matter. One line. No distributions. No smoothness. No independence. Not even probability. Just an inner product and the idea of length and overlap.
It’s the same move every time… Cauchy-Schwarz, plus a smarter choice of what “objects” are and what “overlap” means, and somehow that tiny idea turns into a whole toolbox for geometry, analysis, probability, statistics, and learning theory.
Here are some examples you may have met explained:
You keep reusing the same inequality, but you change what you mean by "inner product"… and you change what you feed into it.
Treat random variables like vectors, and suddenly you get the universal rule that correlation can’t exceed one. Covariance is forced to behave because geometry won’t let it do otherwise.
Feed it absolute value against the constant function “one,” and you get a clean statement that the average magnitude of something can’t exceed its root-mean-square size. One moment controls another with no extra assumptions.
Switch to functions and integrals, and it becomes the go-to move for taming products inside integrals. The standard splitting of mixed term into two energies trick that powers analysis and PDE estimates.
Switch to finite vectors, pair your data with the all-ones vector, and you get the classic fact that the ordinary average can’t beat the quadratic average. Averages don’t get to cheat.
Expand the length of a sum, use Cauchy-Schwarz to control the cross term, and the triangle inequality drops out.
Feed it a matrix acting on a vector, and you get the core stability bound of linear algebra: bilinear interactions are limited by how much the matrix can stretch space. This is amazing spectral norm control in one move.
Pair a signal with a unit basis element, and you get coefficient control...no single component can be larger than the total energy. This is why Fourier and orthonormal expansions don’t blow up.
And in the special case where the overlap is literally zero, you get the cleanest geometry of all: energies add perfectly. Orthogonality is the equality case.
#CauchySchwarz #Inequalities #LinearAlgebra #Probability #Statistics #MachineLearning
Beyond her acting career, Hedy Lamarr co-patented a “frequency-hopping” spread-spectrum system for guiding torpedoes in 1942—technology that later formed the basis for Wi-Fi and Bluetooth—and was posthumously inducted into the National Inventors Hall of Fame in 2014.











![abakcus's tweet photo. The beauty of Rafael Araujo's intricate work. [https://t.co/lY1vvAlUFj] https://t.co/FGKZe4VMSj](https://pbs.twimg.com/media/G_S-YK7XAAEz9e2.jpg)
![abakcus's tweet photo. The beauty of Rafael Araujo's intricate work. [https://t.co/lY1vvAlUFj] https://t.co/FGKZe4VMSj](https://pbs.twimg.com/media/G_S-YK5WIAAZrnR.jpg)







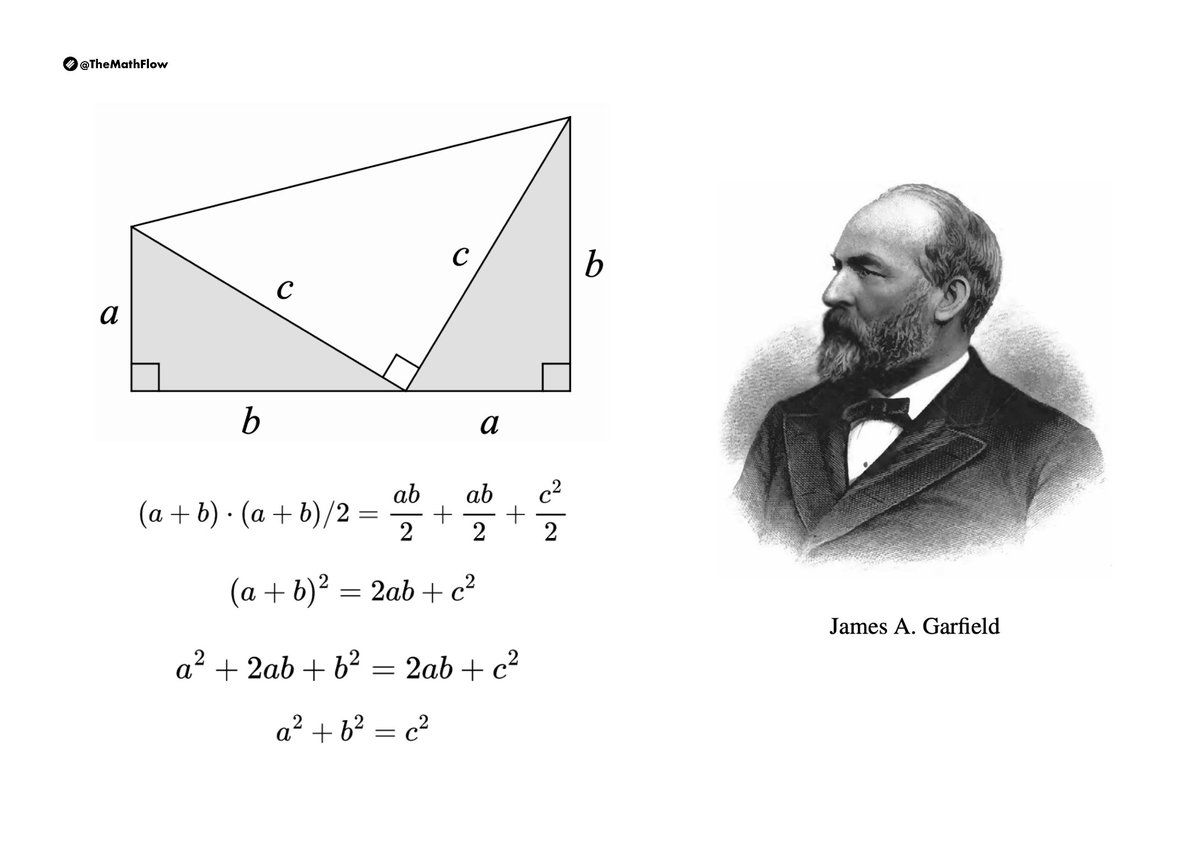

![abakcus's tweet photo. The beauty of Rafael Araujo's intricate work. [https://t.co/lY1vvAlUFj] https://t.co/FGKZe4VMSj](https://pbs.twimg.com/media/G_S-YK-XUAANL7z.jpg)































