We talk a lot about how important it is to set up self-verification loops. Especially in the age of powerful models that can run for long periods of time, self-verification is a key ingredient that enables the model to run for much longer, delivering a result that is closer to what you intended, so you can do more without having to constantly check in on Claude as it works.
@delba_oliveira gives a great breakdown of what that looks like and why it matters
The biggest unlock in Opus 4.8 isn't the model.
It's Dynamic Workflows inside Claude Code.
Here's what that means in plain English:
Old way → you give Claude one task, it does one task.
New way → Claude plans the entire project,
breaks it into subtasks,
spawns hundreds of parallel subagents,
runs them all simultaneously,
then synthesizes everything back into one output.
Real example of what this handles:
→ Migrate 100,000+ lines of code in a single session
→ Refactor an entire codebase while keeping tests green
→ Build, test, and document a full feature in one run
This is not "AI autocomplete."
This is an AI engineering team working for you.
Prompt engineering has been replaced by loop engineering.
What is it? (Explained in 60 seconds)
For the past 2 years we have been prompting agents with individual tasks. That is starting to change.
So far, if you wanted an agent to build a dashboard for a client, you would give it a task, review the output, improve the prompt, and repeat the process until the work was done.
Looping changes that.
Instead of giving an agent individual tasks, you give it a goal and let it work through a recursive loop until that goal is met.
For example:
→ Research
→ Draft
→ Evaluate
→ Test
→ Improve
→ Repeat
The agent keeps cycling through the loop until it reaches the standard you defined.
Within loop engineering there are two main approaches:
1. Open Looping
You give the agent a goal and allow it significant freedom in how it achieves it.
This is powerful, but also expensive and harder to control.
2. Closed Looping
The human defines the architecture, constraints and evaluation criteria.
The agent is then responsible for executing, improving and iterating within those boundaries until the goal is reached.
The next evolution is orchestrated looping.
Instead of a single agent running a loop, one agent breaks the goal into smaller tasks and assigns them to specialist agents.
Each specialist runs its own loop and reports back.
In other words:
You move from one agent improving itself to an entire team of agents iterating together until the goal is achieved.
Anthropic engineer:
"You're not supposed to prompt Claude. You're supposed to build a system that prompts itself."
this is one of the best workflows I've seen in a long time
in this video she breaks down exactly how most people are using Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the automation workflows most users don't know exist
- the daily task pipelines that run without touching the keyboard
- the daily workflows Anthropic's own engineers automated first
if you've been using Claude for more than a month and never left the chat window, you've been using one agent when you could be running a team of them
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
the guide is in the article below
I decided to publish my internal Azure Entra ID tool. There are a lot of these already available, but I've added some interesting features that have made a difference for me over the years. You can capture token through the browser using playwright
https://t.co/xiZaz0PKsC
#Azure
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
Karpathy found a way to reduce token consumption by 90%
The problem is that the LLM re-reads the same files over and over again, loses context between documents, and provides less accurate answers as a result
The solution is called Wiki Layer the LLM cleans, structures, and links all your data once, after which it never works with raw files again
Three folders `raw/` for originals, `wiki/` for a clean knowledge base in Markdown, and files with rules for the agent
Result up to 90% token savings on repeat queries, automatic links between documents, and a visual knowledge graph in Obsidian
Everything stays on your local machine nothing goes to the cloud
Anthropic engineer:
"You can build 5 assistants in one afternoon. Each one handles a task you've been doing manually every single day."
In 45 minutes he builds 5 focused agents from scratch on camera.
Most people are still doing code review, testing, and documentation by hand every single day
Anthropic Managed Agents engineer revealed how to build a production-ready agent team in one session.
26-minutes. free. by Managed Agents team.
here's what they cover:
• 4 blocks: Agent, Environment, Session, Events
• outcomes - Claude iterates a rubric until it passes
• self-hosted sandboxes on Cloudflare, Modal, Vercel
• live observation - every tool call, every subagent
most people are still rebuilding agent infrastructure from scratch - while the people who get this ship real agents in one afternoon
watch the full workshop, then read the article below
Anthropic team member just revealed the 3 layers that turn Claude into a self-running agent team.
36 minutes. free. by Claude Agents engineer.
here's what he covers:
• verification - Claude checks its own work
• multi-сlaude - many agents in parallel background
• loops - keyboard out of the hot
• path routines - prompts that run themselves
most people babysit one agent at a time - while the people who get this delegate entire workflows to running loops
Watch master class, then read the article below ↓
Anthropic engineer:
"You're not supposed to prompt Claude. You're supposed to build a system that prompts itself."
this is one of the best workflows I've seen in a long time
in this video she breaks down exactly how most people are using Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the plugins that 95% of users have never installed
- the workflows that run without you typing a single prompt
- why typing one prompt and closing the tab is leaving 90% on the table
if you've been using Claude for months and still start every session from scratch, you have at least 28 untouched features. probably 30
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
full guide in the article below
Anthropic senior engineer just revealed how to use Claude Code at 110% in a 47-minute session.
47-minutes. free. by Anthropic team.
worth more than any $500 vibe-coding course
here's what she covers:
• 3 things Claude needs: access, knowledge, tooling
• git worktrees + one Claude each = a team you manage • /loop that babysits PRs and fixes CI overnight
• agents that message each other while you sleep
most people use Claude on one repo in one window - while the people who get this run teams of agents in parallel
watch the full talk, then read the article below
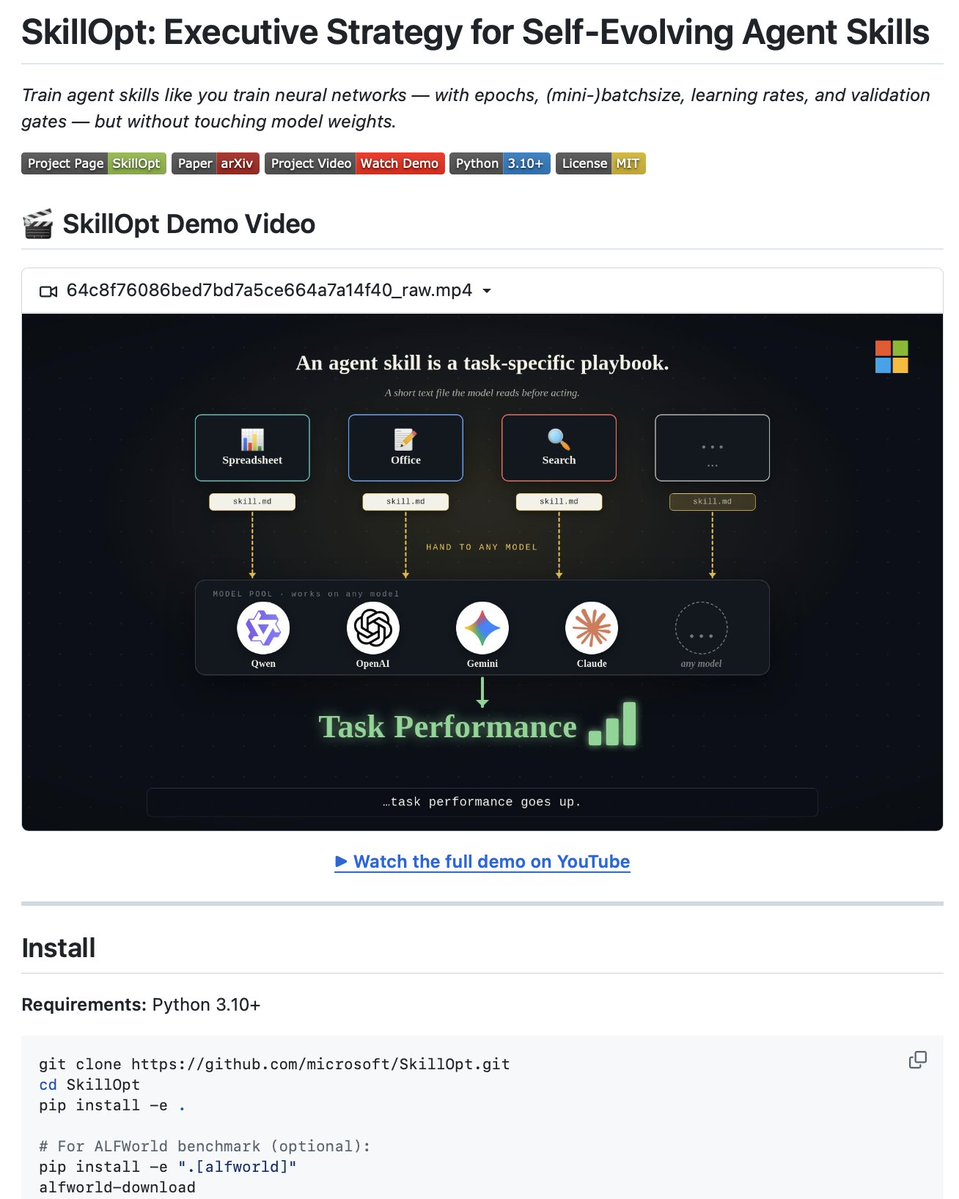
Microsoft just turned SKILL .md into a trainable object!
SkillOpt is a text-space optimizer for agent skills. Instead of hand-writing or one-shot generating your SKILL .md, SkillOpt treats the skill document as the trainable external state of a frozen agent and optimizes it through a feedback loop.
The core idea: a separate optimizer model analyzes agent rollout trajectories, proposes bounded add/delete/replace edits to the skill document, and accepts only edits that strictly improve performance on a held-out validation split. Rejected edits go into a buffer as negative feedback for future iterations.
The deep learning analogy is intentional. Rollout batch is your training data. Edit budget is your learning rate. Validation gate is your validation set. Rejected-edit buffer is your negative feedback signal. The optimizer runs offline. The deployed artifact is just a static SKILL .md file.
Results on GPT-5.5 across 6 benchmarks: +23.5 points average over no-skill baseline in direct chat, +24.8 inside Codex, +19.1 inside Claude Code. SpreadsheetBench jumped from 41.8 to 80.7. OfficeQA from 33.1 to 72.1. Best or tied-best on 52 of 52 evaluated cells.
What's striking: these gains come from just 1-4 accepted edits. The final skill stays compact at 300-2000 tokens. One accepted edit gave OfficeQA a +39 point gain.
Optimized skills also transfer. A SpreadsheetBench skill trained in Codex transferred to Claude Code with a +59.7 point gain. Skills trained on GPT-5.4 improved every smaller GPT variant tested.
Key capabilities:
• Text-space skill optimization with no model weight updates
• Bounded add/delete/replace edits with validation gating
• Rejected-edit buffer as negative feedback
• Epoch-wise slow/meta update for longer-horizon learning
• Works across Claude Code, Codex, and direct chat harnesses
• Optimized skills transfer across models, harnesses, and benchmarks
100% Open Source
I've shared the link to the paper and repo in the comments!
Customers kept asking how to run Claude on Microsoft Foundry inside their own Azure tenant, with the IaC their team already uses.
Packaged the answer into a starter kit. One azd up command and you are done.
https://t.co/owepu6GCkA
#Anthropic#Azure